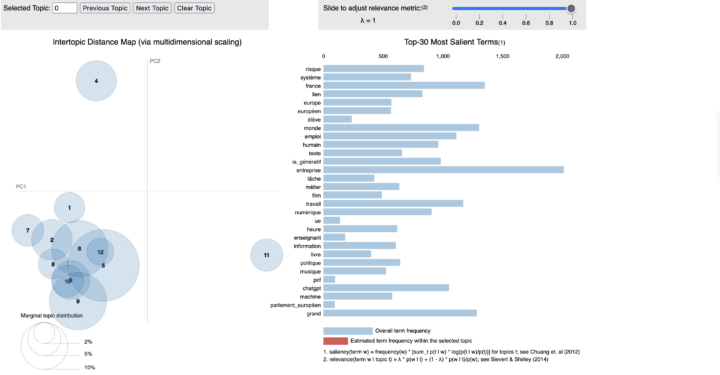
Historique du test LDA Le Latent Dirichlet Allocation (LDA) est un modèle probabiliste basé sur l’idée que les documents sont constitués d’une combinaison de topics, et que chaque topic est caractérisé par une distribution de mots. LDA appartient à la catégorie des modèles d’apprentissage non supervisé. Dans le contexte du traitement automatique du langage naturel, le test LDA...
