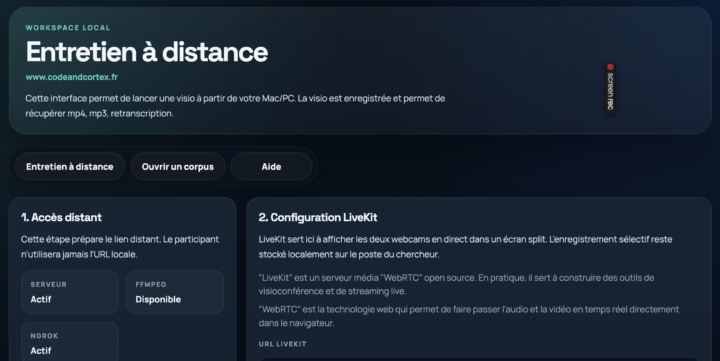
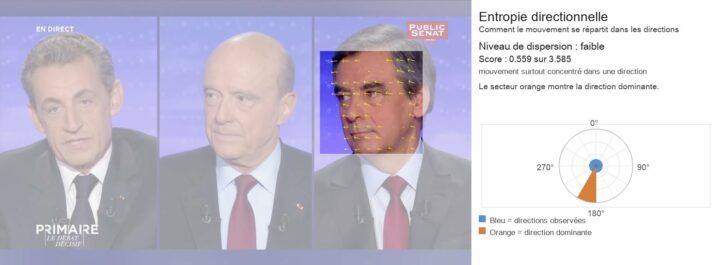
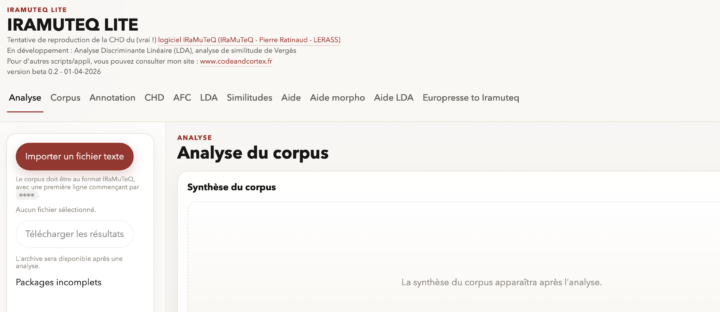
Aucun individu ne pourrait lire, dans le temps d’une vie, l’ensemble des données textuelles utilisées pour entraîner un LLM. Comme le rappelle Yann LeCun, les grands modèles de langage sont entraînés sur une masse textuelle considérable : il évoque environ 170 000 ans de lecture pour parcourir un tel corpus, à raison de huit heures par jour. Pourtant, cette disproportion quantitative ne suffit...