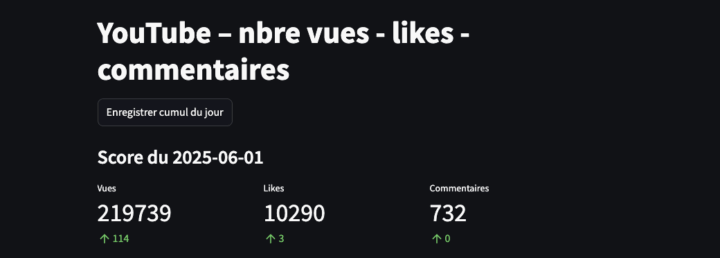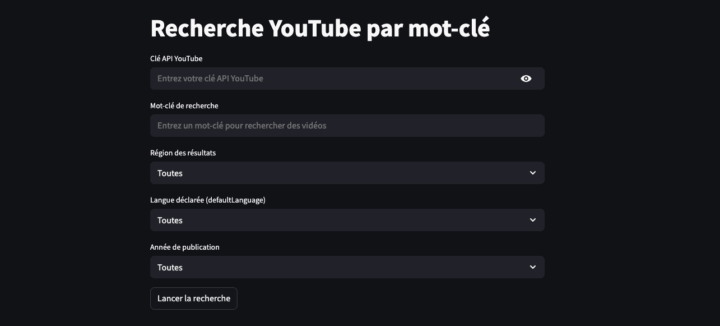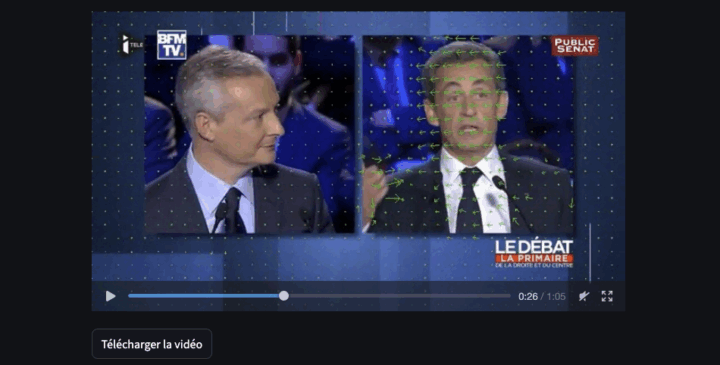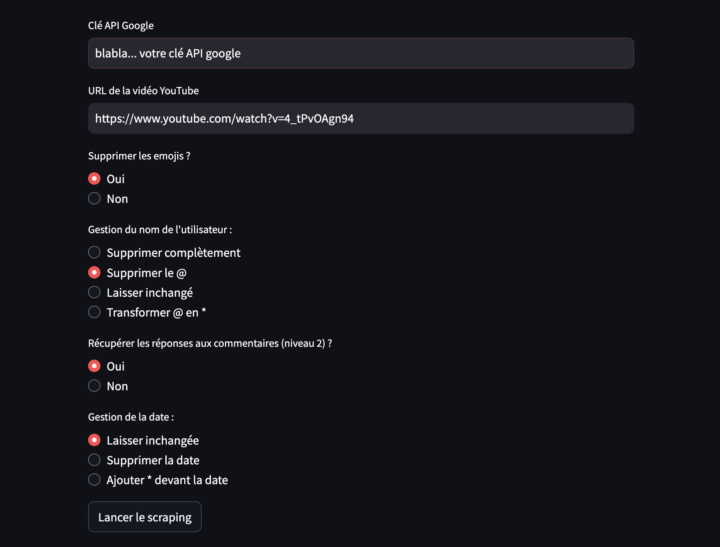
Mesurer l’impact des vidéos d’influenceurs (par exemple) sur YouTube reste un exercice complexe. Il est tentant d’imaginer qu’une vidéo qui accumule des vues, des likes et des commentaires puisse mécaniquement entraîner une hausse des réservations touristiques dans une destination. Mais établir une relation de cause à effet entre visibilité en ligne et comportements de consommation réels — comme...