L’objectif de ce script est d’extraire automatiquement les textes présents sur les pages d’accueil (ce script se limite à la homepage) de sites web touristiques (ou autres), afin de constituer un corpus exploitable pour l’analyse textuelle. Une fois ces textes collectés et nettoyés, on pourra réaliser plusieurs types d’analyses, notamment :
- Analyse de fréquence des termes : bon, là je vous apprends rien…
- Application du test TF-IDF (Term Frequency – Inverse Document Frequency) : cette méthode ne se limite pas à identifier les mots les plus fréquents, mais donne davantage de poids aux termes rares, c’est-à-dire ceux qui apparaissent souvent dans un document spécifique mais rarement dans les autres. Cette pondération permet de faire ressortir les spécificités lexicales d’un site, et de mieux comprendre ce qui le différencie des autres, par exemple pour des analyses SEO.
Ce script constitue donc une première étape : il prépare des fichiers textes « propres » et filtrés, qui peuvent ensuite être traités par un second script dédié à l’analyse en appliquant par exemple le test TF-IDF.
1. Les librairies utiles !
Le script utilise les librairies suivantes :
- requests : pour récupérer les pages web.
- BeautifulSoup : pour parser (lire le code HTML d’une page web, en reconnaître les différentes balises…) le HTML.
- Streamlit : pour l’interface utilisateur.
- os et re : pour gérer les fichiers et nettoyer les textes
Ici on cible spécifiquement les contenus HTML dans les balises <h1>, <p>, <div>, <span> et applique un filtrage pour éviter les textes parasites (mentions légales ou les newsletters, moteurs de vente en ligne, agendas…)
2. Création du nom de fichier texte
Cette fonction retire le protocole (http:// ou https://) et remplace les caractères spéciaux par des underscores pour créer un nom de fichier propre.
def nettoyer_nom_site(url):
nom = re.sub(r"https?://(www\.)?", "", url)
nom = nom.split("/")[0]
nom = re.sub(r"[^\w\-]", "_", nom)
return nom

3. Suppression des caractères indésirables dans les textes
def nettoyer_texte(texte):
texte = re.sub(r'\d+', '', texte) # Retire tous les chiffres
texte = re.sub(r'[^\w\s,.\'’?!:;()\-\–àâçéèêëîïôùûüÿœæÀÂÇÉÈÊËÎÏÔÙÛÜŸŒÆ]', '', texte)
return texte
Ici, on retire : Tous les chiffres (\d+) et tous les caractères non alphabétiques à l’exception de ponctuations et lettres accentuées (français).
Ce nettoyage permet d’obtenir un texte homogène pour des analyses futures en appliquant le test TF-IDF.
4. Fonctionnement de BeautifulSoup : parser le HTML et filtrer
soup = BeautifulSoup(reponse.text, "html.parser")
Lorsqu’on récupère le texte d’un site web, on extrait non seulement le contenu principal (les paragraphes destinés aux visiteurs) mais aussi une grande quantité de bruit provenant de balises non pertinentes.
Ce bruit comprend :
- des éléments techniques (scripts, styles CSS, balises de navigation),
- des textes répétitifs ou sans intérêt dans notre cas pour l’analyse (les mentions légales, les formulaires, les boutons de réservation, les newsletters…),
- des textes très (trop) courts sans intérêt pour l’analyse (comme « réserver », « contact », « en savoir plus »).
for element in soup(["script", "style", "footer", "nav", "header"]):
element.decompose()
Ici, on supprime les balises non pertinentes (scripts, styles, barres de navigation, pied de page…) pour éviter ainsi le “bruit” (bien que dans une perspective d’analyse SEO du site certaines de ces balises seraient pertinentes).
Autre filtrage :
for mot in ['footer', 'legal', 'mentions', 'bottom', 'bouton', 'cookies', 'newsletter', 'reservation', 'réservation', 'Agenda', 'agenda']:
for div in soup.find_all(attrs={"class": lambda c: c and mot in c.lower()}):
div.decompose()
for div in soup.find_all(attrs={"id": lambda i: i and mot in i.lower()}):
div.decompose()
Ici, on supprime toutes les balises dont le class ou l’id contient des mots indésirables (mentions légales, cookies, newsletter…).
5. Extraction et filtrage des blocs de texte
for b in soup.find_all(['h1', 'p', 'div', 'span']):
txt = b.get_text(separator=" ", strip=True)
if txt:
if len(txt) >= 100 :
if not any(mot in txt.lower() for mot in mots_indesirables):
textes.append(txt)
On récupère le texte de chaque balise ciblée et on applique :
- Un filtre de longueur : au moins 100 caractères pour éviter les petits textes sans intérêt (valeur modifiable dans le script).
- Un filtre de contenu : on ignore les blocs contenant des mots parasites comme « mentions légales ».
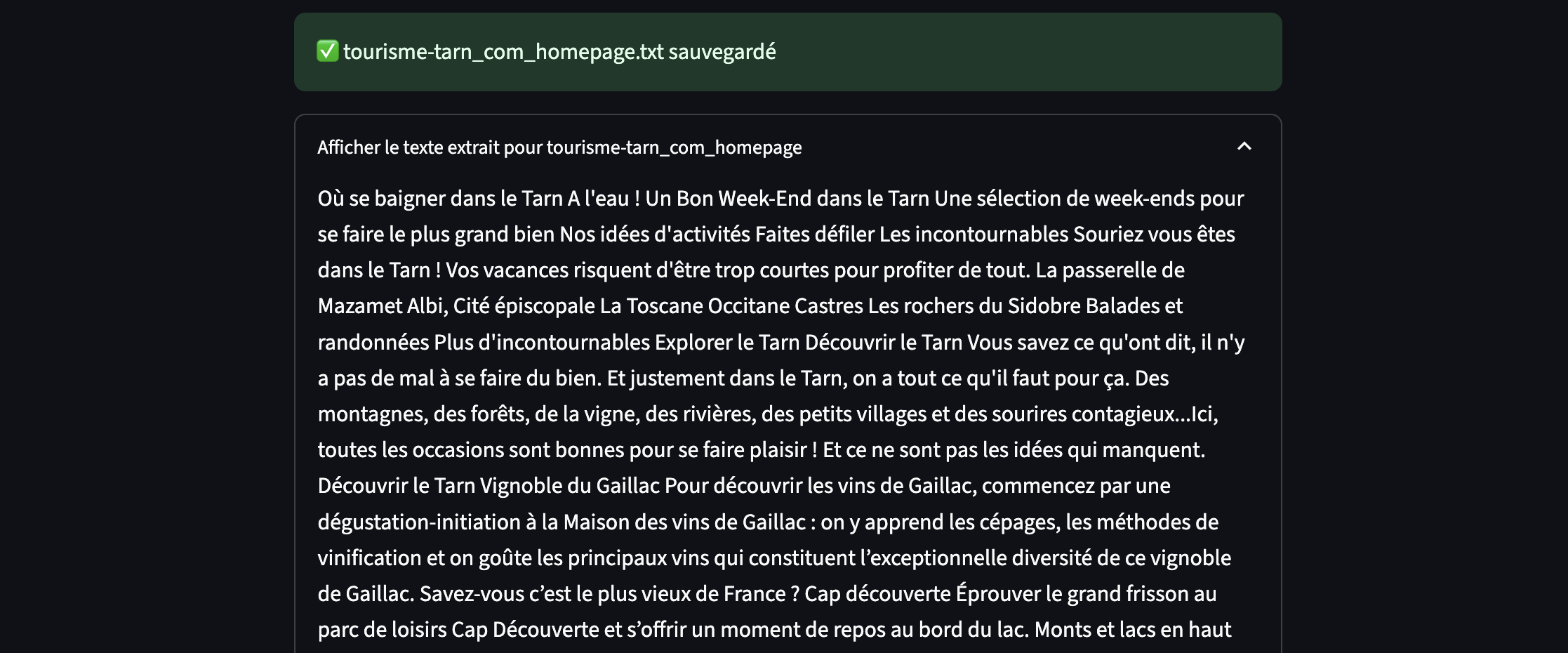
6. Enregistrement des textes extraits
lignes_uniques = list(dict.fromkeys(textes))
texte_final = "\n".join(lignes_uniques)
texte_final = nettoyer_texte(texte_final)
chemin_fichier = os.path.join(dossier_sortie, f"{nom_fichier}.txt")
with open(chemin_fichier, "w", encoding="utf-8") as f:
f.write(texte_final)
On supprime les doublons, concatène le texte final, applique le nettoyage, sauvegarde le tout dans un fichier .txt dans le dossier défini par l’utilisateur.
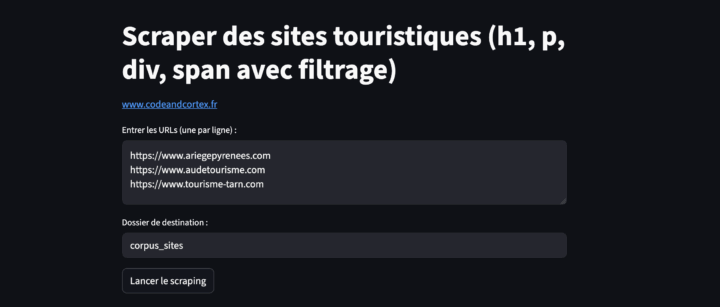
7. Interface Streamlit
def interface_scraper():
st.title("Scraper des sites touristiques (h1, p, div, span avec filtrage avancé)")
st.markdown("[www.codeandcortex.fr](https://www.codeandcortex.fr)")
urls = st.text_area("Entrer les URLs (une par ligne) :",
"https://www.ariegepyrenees.com\nhttps://www.audetourisme.com\nhttps://www.tourisme-tarn.com")
dossier_sortie = st.text_input("Dossier de destination :", "corpus_sites")
if st.button("Lancer le scraping"):
urls_list = [u.strip() for u in urls.splitlines() if u.strip()]
for url in urls_list:
nom_fichier = nettoyer_nom_site(url) + "_homepage"
succes, texte, chemin = extraire_texte_depuis_url(url, nom_fichier, dossier_sortie)
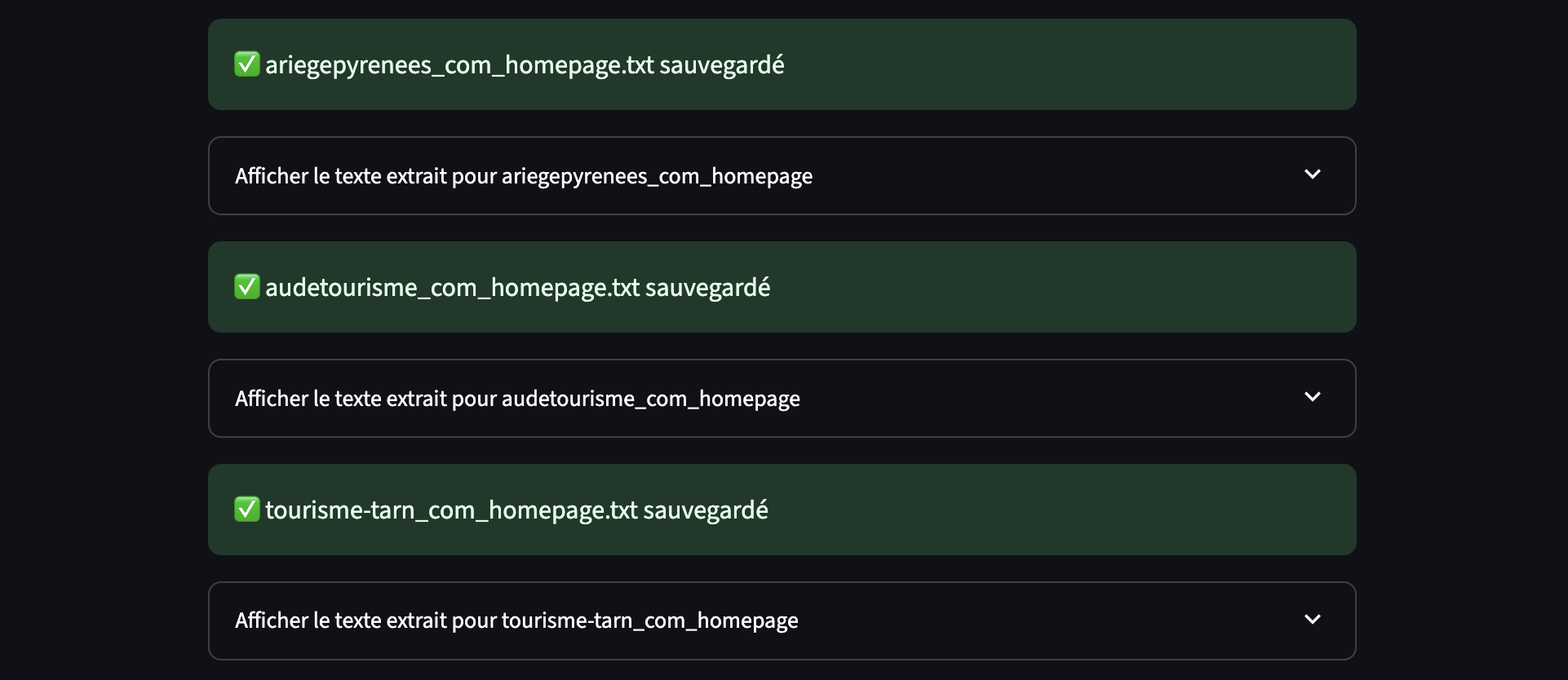
if succes:
st.success(f"✅ {nom_fichier}.txt sauvegardé")
with st.expander(f"Afficher le texte extrait pour {nom_fichier}"):
st.write(texte)
else:
st.error(f"❌ Erreur pour {url} : {texte}")
Lancerz le script à partir de l’instruction dans votre terminal Python : python -m streamlit run main.py
Conclusion
Ce script constitue un outil pour collecter et nettoyer des corpus textuels à partir du web.
On pourra ultérieurement améliorer le filtrage selon l’objectif (analyse textuelle, analyse SEO…) et le nombre de page à scanner.