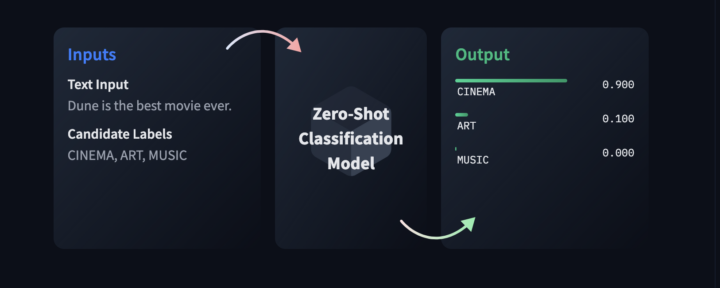
Pour comprendre la notion d’entropie mobilisée dans le calcul de la Divergence de Jensen-Shannon (JSD), il faut se détacher de l’entropie de Boltzmann, qui renvoie à l’ordre et au désordre d’un système, notamment en thermodynamique, pour se concentrer sur l’entropie au sens informationnel. Dans ce cadre, l’incertitude ne décrit pas un désordre physique, mais le degré de prévisibilité d’une...