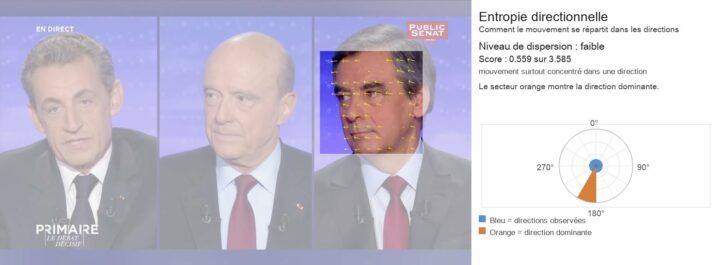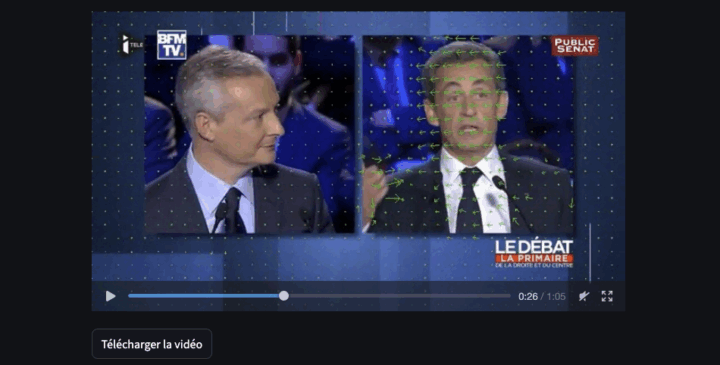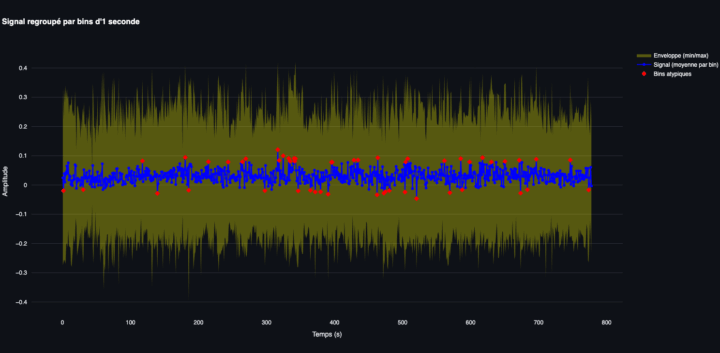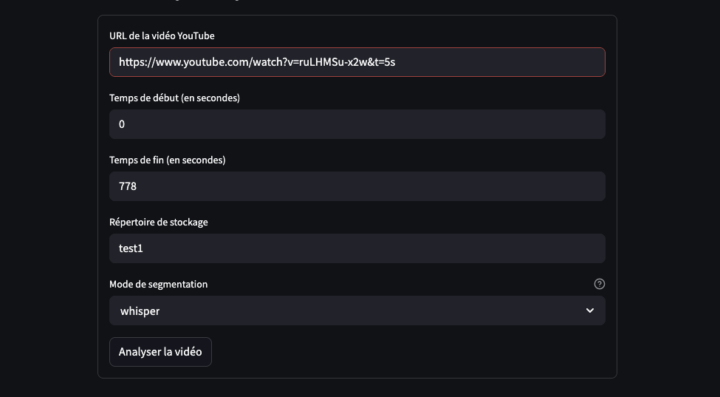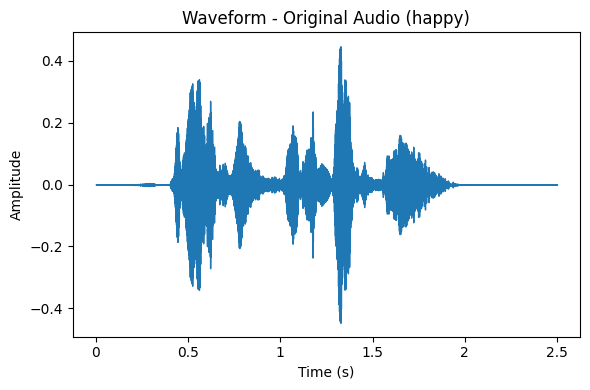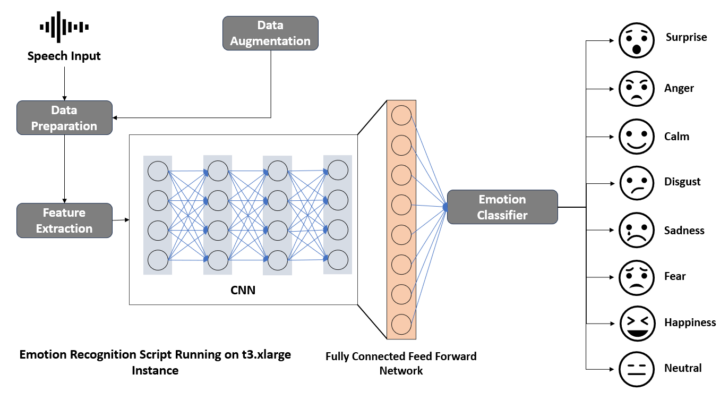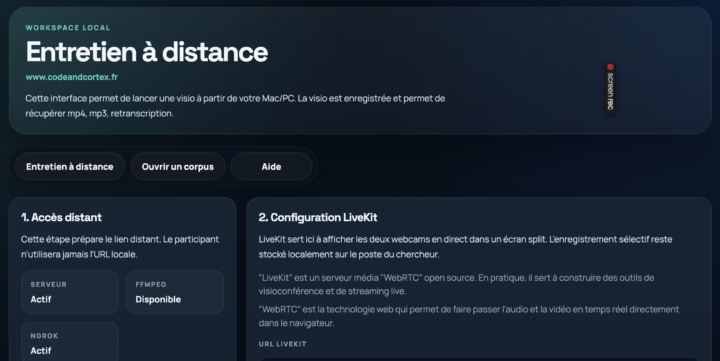
Voici un prototype d’application d’entretien à distance conçu pour les Sciences Humaines. L’objectif n’est pas de proposer une énième solution de visioconférence, mais de construire un dispositif de production de données multimodales (texte/audio/vidéo). Le lien github de l’appli : L’enquêteur pilote directement l’application sur son Mac ou son PC, sans recourir à une plateforme tierce. Il...