

Fonctionnement de Selenium
Selenium est une bibliothèque utilisée pour automatiser les navigateurs web.
Elle permet d’écrire des scripts en divers langages de programmation (comme Python, Java, C#, etc…) pour interagir avec des pages web de la même manière qu’un utilisateur humain le ferait.

Quelles différences entre Selenium et l’utilisation de l’API de Méta ?
Installer ChromeDriver sur MAC
ChromeDriver est un pont entre le code Selenium et le navigateur Google Chrome. Selenium utilise divers drivers pour contrôler différents navigateurs, et ChromeDriver est spécifiquement conçu pour interagir avec Chrome. Ainsi le script utilisant Sélénium, à besoin de de ChromeDriver pour piloter Chrome de manière automatisée, simulant les actions d’un utilisateur humain, comme cliquer sur des boutons, remplir des formulaires et naviguer à travers des pages (scroller par exemple).
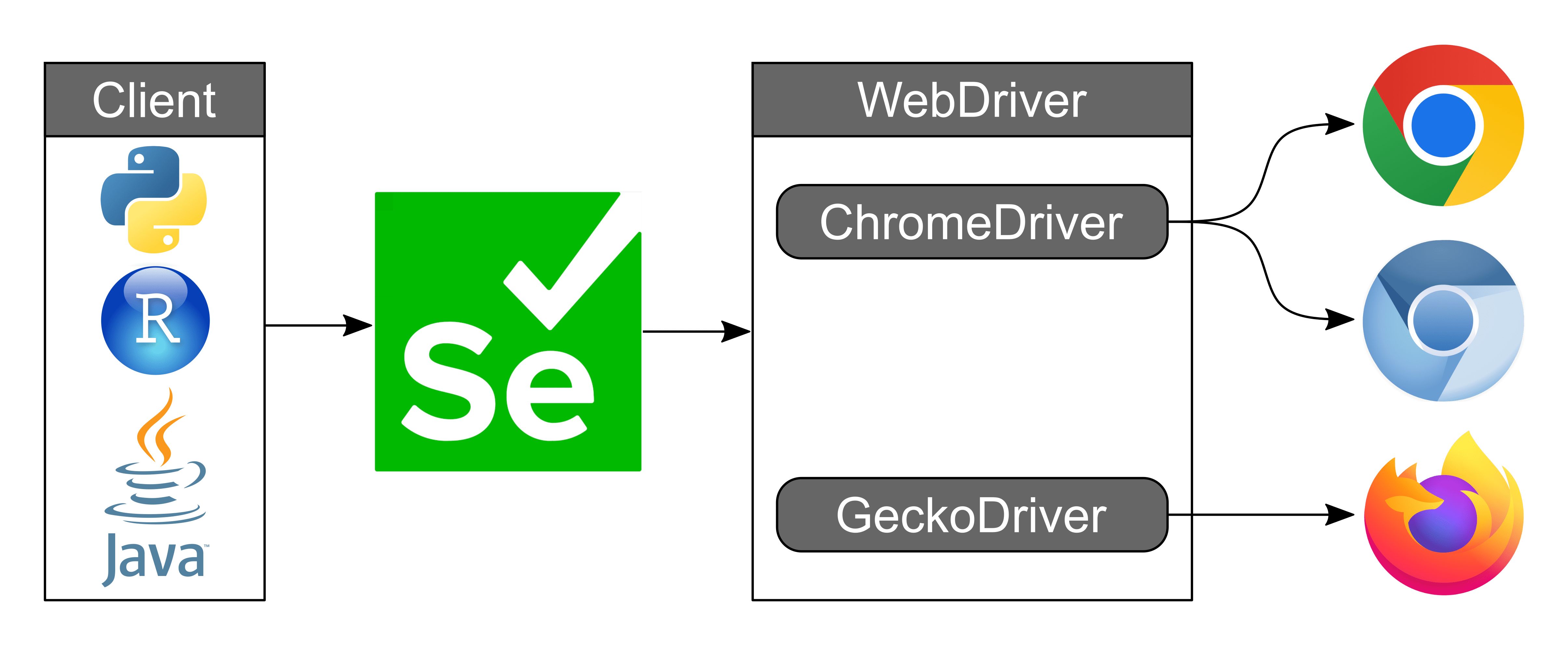
Pour installer ChromeDriver sur votre Mac, il faut s’assurer de disposer d’une version stable de Google Chrome et obtenir le numéro de cette version afin de télécharger la version adéquate de ChromeDriver.
Pour les Mac M1, M2, et M3, vous devez télécharger la version “mac-arm64“.
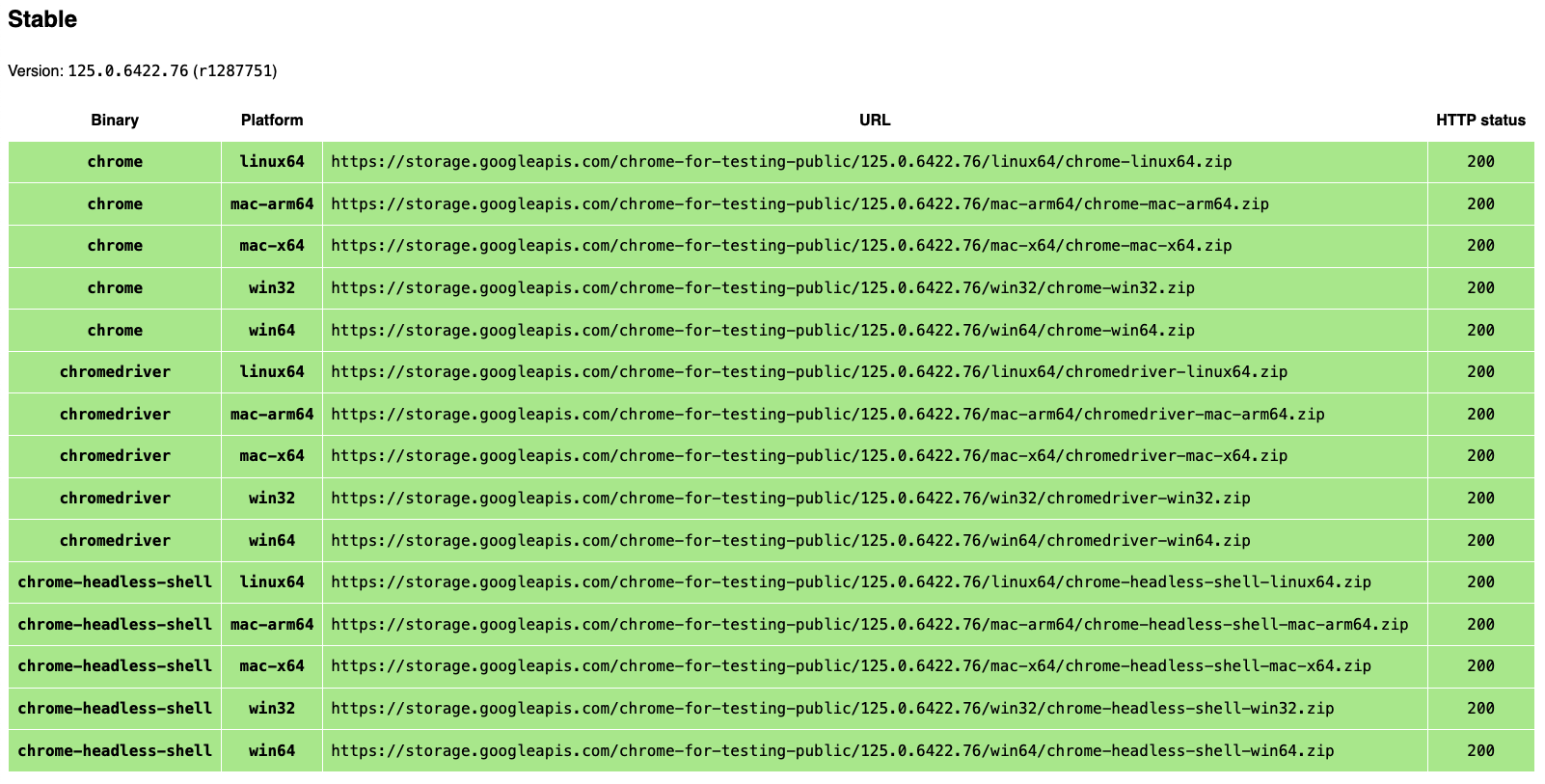
Voici les étapes :
- Télécharger la version correcte de ChromeDriver pour votre navigateur Chrome
- Installer ChromeDriver à partir du Terminal
- Décompresser et déplacer ChromeDriver dans
/usr/local/bin/de votre Mac - Vérifier la version de ChromeDriver
Voici les commandes complètes à exécuter dans l’ordre :
1. Accédez au répertoire contenant le fichier ZIP :
Une fois enregistré, vous devez repérer le répertoire de votre DD dans lequel vous avec avez enregistré ChromeDriver, pour cela c’est plutôt simple glissez/déposez le répertoire dans le terminal vous obtiendrez le chemin 😉
Ensuite dans le terminal vous allez accéder au répertoire cible dans lequel se trouve ChromeDirver.
Exemple : /Users/Le nom de votre Mac/Documents/chromedriver/
La suite des instructions se feront dans à partir du terminal du Mac et dans le répertoire dans lequel est situé ChromeDrive.
2. Décompressez le fichier ZIP :
Tapez la commande pour décompresser l’archive de chromedriver.
unzip chromedriver-mac-arm64.zip
3. Accédez au répertoire décompressé :
cd chromedriver-mac-arm64
4. Attribuez les permissions d’exécution au fichier chromedriver :
chmod +x chromedriver
5. Déplacez le fichier chromedriver vers /usr/local/bin/ :
Cette étape est primordiale, car le script va appeler le fichier depuis cet emplacement
sudo mv chromedriver /usr/local/bin/chromedriver
6. Vérifiez la version de chromedriver :
A ce stage il faut vérifier la version de ChromeDriver et être sur qu’elle est compatible avec la version de Google Chrome.>
chromedriver --version
Le script
Au lancement du script, je me dis “Eureka !” mais, alors que je suis déjà connecté à Facebook via Google Chrome, le script lance la boîte de dialogue pour s’authentifier et il m’est impossible de saisir mon mot de passe ; le script s’arrête !
Il faut donc utiliser les cookies de session pour maintenir la connexion et pour automatiser les interactions avec le site web Facebook nécessitant une authentification.
Cela permet de contourner les problèmes de connexion manuelle.
Dans un premier temps il est impératif de se connecter manuellement à partir de Google Chrome à Facebook.
Ensuite, il faut utiliser une extension de navigateur comme EditThisCookie pour exporter les cookies de session.
Pour ce faire, il faut ajouter l’extension à votre navigateur (Chrome). Après vous être connecté à Facebook, cliquez sur l’icône de l’extension et exportez les cookies au format JSON.
Enregistrez le fichier nommé facebook_cookies.json dans le répertoire de votre projet.
Voici le script, avec des commentaires décrivant les différentes étapes.
#pip install selenium pandas
####
import json
import re
import requests
import pandas as pd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Chemin vers le fichier chromedriver installé dans /usr/local/bin/
chrome_service = Service('/usr/local/bin/chromedriver')
# Chemin vers le fichier de cookies exporté --> à remplacer
cookies_file = '/Users/stephanemeurisse/Documents/Recherche/ScrapFacebook/facebook_cookies.json'
######
# Charger les cookies depuis le fichier JSON
def load_cookies(driver, cookies_file):
with open(cookies_file, 'r') as file:
cookies = json.load(file)
for cookie in cookies:
# Certains champs ne sont pas acceptés par Selenium, les filtrer
if 'sameSite' in cookie:
del cookie['sameSite']
if 'priority' in cookie:
del cookie['priority']
driver.add_cookie(cookie)
# Initialiser le WebDriver pour Chrome
driver = webdriver.Chrome(service=chrome_service)
# URL de la page d'accueil Facebook
login_url = 'https://www.facebook.com'
# Naviguer vers la page d'accueil
driver.get(login_url)
# Charger les cookies pour maintenir la session
load_cookies(driver, cookies_file)
# Rafraîchir la page pour appliquer les cookies
driver.refresh()
# Attendre que la page se charge complètement
time.sleep(5)
# URL du post Facebook --> à remplacer
post_url = 'https://www.facebook.com/groups/722944715998047/permalink/810420960583755/'
# Naviguer vers le post
driver.get(post_url)
# Attendre que la page se charge
time.sleep(5) # Ajustez en fonction de votre connexion Internet
# Faire défiler pour charger tous les commentaires
scroll_pause_time = 2
while True:
last_height = driver.execute_script("return document.body.scrollHeight")
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
time.sleep(scroll_pause_time)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
# Extraire les commentaires
comments = []
try:
comment_elements = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[data-ad-preview='message']"))
)
for comment in comment_elements:
comments.append(comment.text)
except Exception as e:
print(f"Erreur lors de l'extraction des commentaires: {e}")
# Fermer le navigateur
driver.quit()
# Sauvegarder les commentaires dans un fichier CSV
if comments:
df = pd.DataFrame(comments, columns=['Comment'])
df.to_csv('facebook_comments.csv', index=False)
print(f'Commentaires extraits et sauvegardés dans {os.path.join(os.getcwd(), "facebook_comments.csv")}')
else:
print("Aucun commentaire trouvé.")
[…] de ce script est d’extraire automatiquement les textes présents sur les pages d’accueil (ce script se limite à la homepage) de sites web touristiques […]