
Pour comprendre la notion d’entropie mobilisée dans le calcul de la Divergence de Jensen-Shannon (JSD), il faut se détacher de l’entropie de Boltzmann, qui renvoie à l’ordre et au désordre d’un système, notamment en thermodynamique, pour se concentrer sur l’entropie au sens informationnel. Dans ce cadre, l’incertitude ne décrit pas un désordre physique, mais le degré de prévisibilité d’une distribution : plus la répartition des éléments est difficile à anticiper, plus l’entropie est élevée.
La divergence de Jensen-Shannon (JSD) est une mesure issue de la théorie de l’information qui permet de quantifier l’écart entre deux distributions de probabilité. Appliquée à l’analyse textuelle, elle sert à comparer la répartition des mots dans deux corpus. Une JSD faible indique que les deux ensembles mobilisent un vocabulaire distribué de manière proche ; une JSD plus élevée signale au contraire une différence plus marquée dans les usages lexicaux.
Son intérêt est double : elle fournit un indicateur de divergence lexicale entre textes, tout en permettant d’identifier les mots qui contribuent le plus à cette divergence. Dans une perspective longitudinale, la JSD est utile pour suivre l’évolution d’un discours dans le temps, en repérant des déplacements lexicaux progressifs, des ruptures ou, au contraire, des phases de stabilité.
La JSD n’est pas un test statistique comparable, par exemple, au chi². Elle constitue une mesure descriptive de l’écart entre deux distributions lexicales : elle quantifie l’ampleur de la divergence, mais ne fournit ni p-value ni critère de significativité statistique.
1. L’Entropie de Shannon
L’entropie de Shannon provient de la théorie de l’information. À l’origine, elle sert à mesurer l’incertitude d’un message. Plus une distribution est concentrée sur quelques éléments dominants, plus l’entropie est faible. Plus la distribution est dispersée entre de nombreux éléments, plus l’entropie est élevée.
![\[H = - \sum_{i=1}^{n} p_i \log(p_i)\]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-ae1e638f482a0cba79ec990fdf20b26b_l3.png "Rendered by QuickLaTeX.com")
Appliquée à un texte, cette idée permet de décrire la manière dont les mots se répartissent dans un entretien. Un discours très resserré autour de quelques termes fortement récurrents présente une entropie plus faible qu’un discours où le vocabulaire se répartit de façon plus étendue.
2. La Divergence de Jensen-Shannon
La divergence de Jensen-Shannon (JSD) est une mesure issue de la théorie de l’information qui permet de comparer deux distributions de probabilité. Dans le cadre d’une analyse textuelle, elle sert à comparer la répartition des mots dans deux corpus. Son intérêt est de produire à la fois un score global de divergence et une décomposition mot par mot, ce qui permet d’identifier les termes qui contribuent le plus aux différences observées dans les deux textes.
![\[ P=(p_i), \qquad Q=(q_i) \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-49083feb2a6f04fb7643fb4f8e5870d3_l3.png "Rendered by QuickLaTeX.com")
![\[ M=\frac{P+Q}{2}=(m_i) \qquad \text{avec} \qquad m_i=\frac{p_i+q_i}{2} \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-173b56ec7fe8979778c34ed3e24d097c_l3.png "Rendered by QuickLaTeX.com")
![\[ H(R)=-\sum_i r_i \log_2(r_i) \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-748a46bda8d96215d1d7dd1cdf8d07a0_l3.png "Rendered by QuickLaTeX.com")
![\[ \operatorname{JSD}(P,Q)=H(M)-\frac{1}{2}H(P)-\frac{1}{2}H(Q) \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-be22cff2377e558f69c136a7edb179fb_l3.png "Rendered by QuickLaTeX.com")
Sur le plan mathématique, la JSD repose sur l’entropie de Shannon. Si l’on note P et Q les distributions comparées, et M = (P + Q)/2 leur distribution moyenne, alors la JSD s’écrit comme la différence entre l’entropie de cette distribution moyenne et la moyenne des entropies de P et Q.
À l’échelle d’un mot donné i, p_i représente la probabilité, ou fréquence relative, de ce mot dans le texte A, tandis que q_i représente sa probabilité dans le texte B. Enfin, m_i correspond à la moyenne de ces deux probabilités, selon la formule m_i = (p_i + q_i)/2. La contribution de chaque mot à la divergence globale dépend ainsi de l’écart entre sa fréquence relative dans les deux textes.
La JSD compare deux distributions de probabilités lexicales en évaluant dans quelle mesure chacune s’écarte de leur distribution moyenne.
3. Le code source
Sur GitHub, vous pouvez tester le script avec les deux textes. Il faudra au préalable installer les bibliothèques nécessaires indiquées dans le fichier requirements.txt.
https://github.com/stephane1109/divergence-jensen-shannon/tree/main
3.1 Le corpus
Le corpus utilisé pour ce test se compose de deux textes simulés, notés A et B, de longueurs différentes. Ce choix n’est pas anodin : il permet d’illustrer l’intérêt de la divergence de Jensen-Shannon dans un cas où les corpus ne sont pas de taille équivalente. La version retenue ici est la JSD standard, recommandée dans la littérature pour la comparaison de corpus, y compris lorsque l’on confronte un texte court à un texte long. À l’inverse, la distance de Labbé est, d’après ses auteurs, sensible aux différences de taille entre corpus, ce qui invite à une interprétation plus prudente lorsque les textes comparés sont de longueurs inégales.

- Labbé & Labbé, La distance intertextuelle : PDF
- Lu, Henchion & MacNamee, Diverging Divergences : PDF
3.2 Score de JSD globale
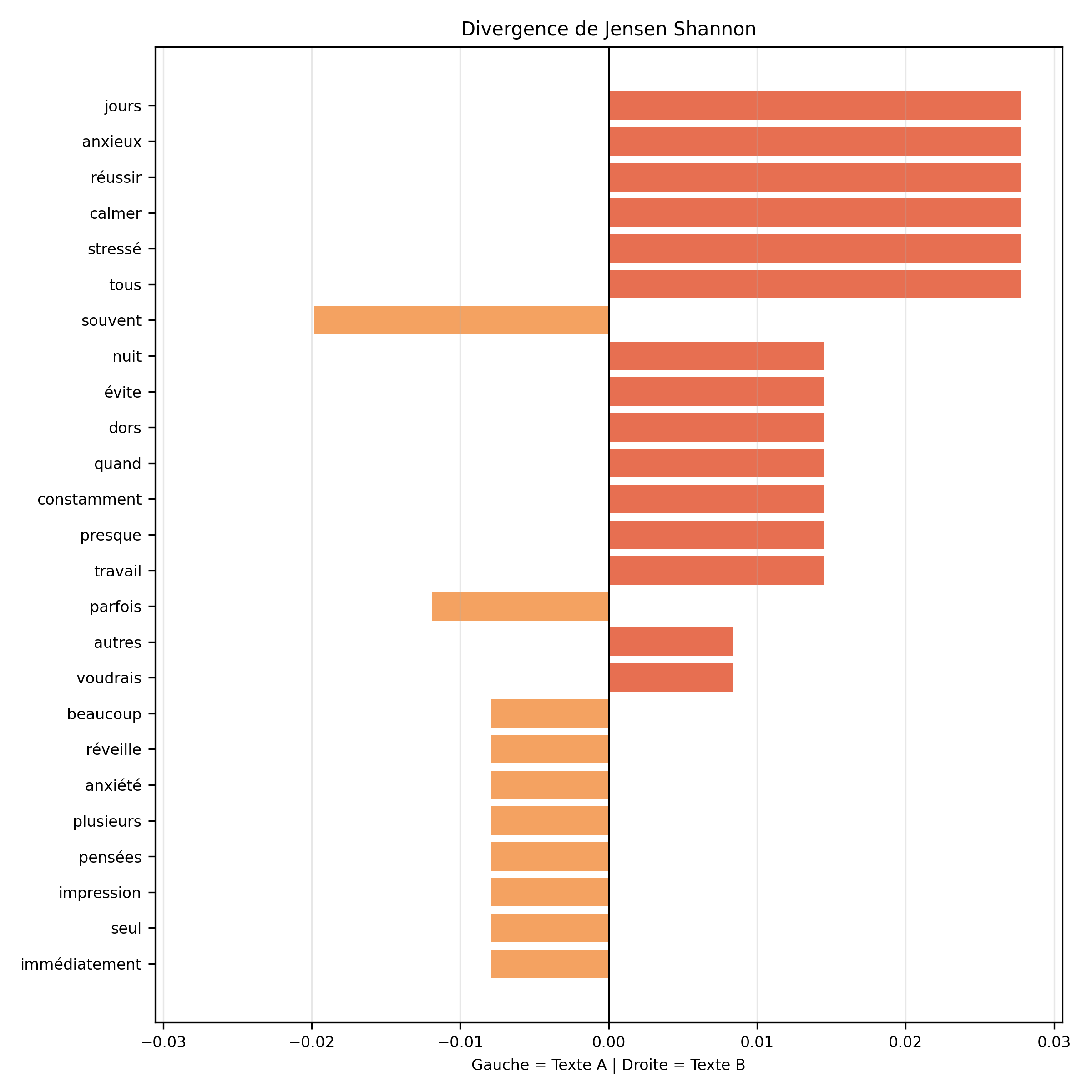
Le score global de divergence de Jensen-Shannon correspond au cumul des contributions de l’ensemble des termes du vocabulaire comparé. Chaque mot apporte une part plus ou moins importante à la divergence selon sa fréquence relative dans chacun des deux textes.
“(…) En tout état de cause, il ne faut pas comparer des textes trop différents à la fois par leur vocabulaire et leur taille : 1 à 10 étant, de ce point de vue, un maximum à ne pas dépasser (…)” (Corpus 3, page 8, La distance intertextuelle)
Le score final repose donc sur l’addition des contributions lexicales, ce qui permet de mesurer l’écart global entre les deux distributions. Cette logique de quantification d’une distance entre textes peut être rapprochée de la mesure intertextuelle de Labbé, bien que les deux méthodes ne reposent pas sur les mêmes principes de calcul ni sur la même interprétation.
3.3 Score pour un terme
Pour illustrer le calcul de la Jensen-Shannon divergence (JSD), on peut examiner le mot “travail”, présent dans les deux textes. Après prétraitement, notamment la normalisation et le filtrage des stopwords à l’aide de la bibliothèque NLTK, le texte A contient 126 mots conservés et le texte B en contient 18.
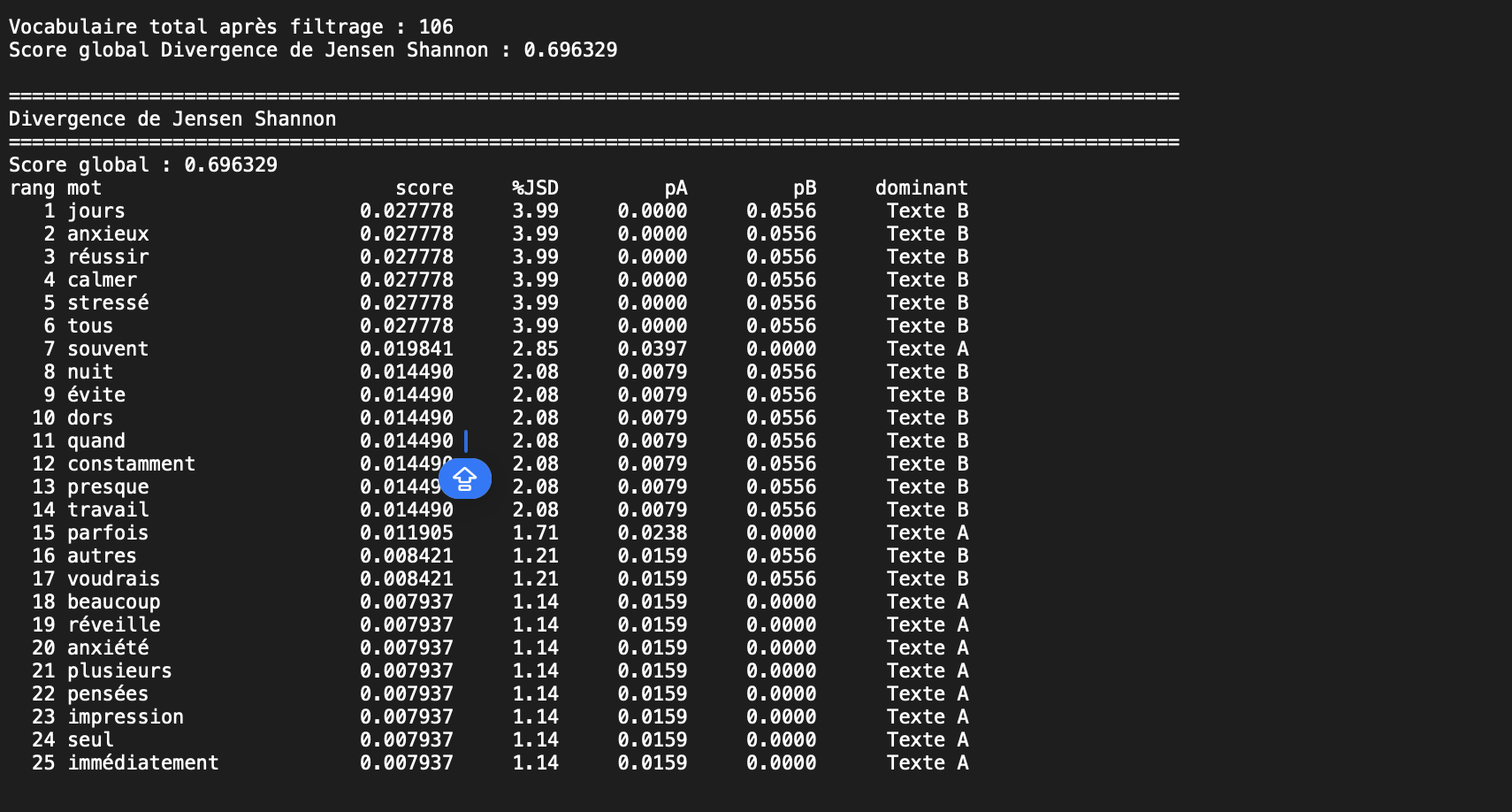
Dans le corpus, le mot “travail“ apparaît une fois dans chacun des deux textes.
- P désigne la distribution de probabilité des mots dans le texte A
- Q la distribution de probabilité des mots dans le texte B
- p_i correspond à la fréquence relative d’un mot dans le texte A
- q_i correspond à la fréquence relative d’un mot dans le texte B
- M désigne la distribution moyenne construite à partir de P et Q
- m_i représente, pour un mot donné, la moyenne des deux probabilités p_i et q_i
- c_i désigne la contribution du mot i à la divergence de Jensen-Shannon globale
(Calculette en log2 : https://www.omnicalculator.com/fr/mathematiques/calculateur-log-2)
Ses fréquences relatives sont donc :
![\[ p_{\mathrm{travail}}=\frac{1}{126}=\ 0.0079 \qquad q_{\mathrm{travail}}=\frac{1}{18}=\ 0.0556 \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-d88049e06601c1a2f9431c885842bd14_l3.png "Rendered by QuickLaTeX.com")
La moyenne des deux probabilités vaut :
![\[ m_{\mathrm{travail}}=\frac{p_{\mathrm{travail}}+q_{\mathrm{travail}}}{2} =\frac{0.0079+0.0556}{2} =\ 0.0317 \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-3a0c1ba5a724aeaf01439178f0cd9ef1_l3.png "Rendered by QuickLaTeX.com")
La contribution du mot à la JSD est alors :
![\[ \begin{aligned} c_{\mathrm{travail}} &= -\left(m_{\mathrm{travail}} \times \log_2(m_{\mathrm{travail}})\right) +\frac{1}{2}\times p_{\mathrm{travail}} \times \log_2(p_{\mathrm{travail}}) +\frac{1}{2}\times q_{\mathrm{travail}} \times \log_2(q_{\mathrm{travail}}) \\[6pt] &= -\left(0.03175 \times \log_2(0.03175)\right) +\frac{1}{2}\times 0.00794 \times \log_2(0.00794) +\frac{1}{2}\times 0.05556 \times \log_2(0.05556) \\[6pt] &= -\left(0.03175 \times (-4.97728)\right) +\frac{1}{2}\times 0.00794 \times (-6.97728) +\frac{1}{2}\times 0.05556 \times (-4.16993) \\[6pt] &= 0.15801 - 0.02769 - 0.11583 \\[6pt] &\approx 0.01449 \end{aligned} \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-adcbcdbe36aef0ddbc83a8cf4d83f7d3_l3.png "Rendered by QuickLaTeX.com")
Bien que le mot apparaisse une fois dans chacun des deux textes, sa contribution à la divergence n’est pas nulle, car il occupe une place proportionnellement plus importante dans le texte B, qui est beaucoup plus court.
Cet exemple montrent que la JSD repose sur la fréquence relative des mots dans chaque texte. Un mot peut apparaître le même nombre de fois dans deux entretiens et néanmoins contribuer à la divergence s’il occupe un poids relatif différent dans chacun d’eux.
Conclusion
L’intérêt principal de la JSD, dans une analyse longitudinale, est de suivre une trajectoire discursive. On peut par exemple comparer chaque texte à un texte initial de référence. Cela permet d’observer si le lexique reste stable, s’éloigne progressivement de son point de départ, ou connaît des inflexions brusques.
La JSD devient alors un indicateur de transformation du langage.
Dans le domaine de la santé mentale, la JSD peut aider à suivre l’évolution du langage d’un patient au fil du temps. Elle permet de repérer des déplacements lexicaux, mais aussi des formes de structuration du discours, comme l’émergence de thèmes, la persistance d’obstacles, ou la répétition de certaines boucles discursives.
Dans l’accompagnement entrepreneurial, la JSD peut servir à suivre l’évolution du discours d’un porteur de projet entre plusieurs séances ou plusieurs écrits. Elle peut mettre en évidence un passage d’un discours flou à un discours plus structuré, d’une focalisation sur les obstacles à une focalisation sur les actions, ou encore d’un langage centré sur l’idée à un langage centré sur la mise en œuvre, les partenaires, le financement ou le modèle économique.
Là encore, la JSD n’évalue ni la qualité intrinsèque du projet ni la réussite future ; elle renseigne sur la transformation du cadrage discursif.