Au départ, on peut citer les travaux de Gregory Bateson et de Margaret Mead. Durant cette période, Gregory Bateson met en évidence le concept de double bind (double contrainte, double lien, injonction paradoxale), issu d’un processus d’analyse d’images (chronophotographie) et d’observation de terrain.
L’analyse ne se limite pas à des contenus isolés, mais repose sur l’inscription du sujet dans un système de relations, où les interactions, les contextes et les niveaux de communication deviennent centraux.

Avec l’arrivée du numérique, la recherche a trouvé de nouvelles sources de données. La conversion de vidéos YouTube en texte, l’exploitation des réseaux sociaux ou le scraping de sites internet constituent désormais des matériaux de recherche accessibles. Ces données apparaissent, plus spontanées, notamment dans le langage, et s’affranchissent en partie des contraintes propres aux dispositifs classiques d’entretien, qui (peuvent) introduire des biais liés à la relation enquêteur–enquêté et aux finalités de la recherche.
Dans la continuité des travaux de Bateson, cela ouvre une perspective : celle d’une exploration du web dans une approche multimodale, visant à synchroniser texte, image et audio. Il s’agit, en quelque sorte, d’une forme d’anthropologie numérique, adaptée à des contenus qui ne relèvent plus d’un terrain “classique”, mais d’un espace de diffusion médiatisé.
1. De l’observation à la construction d’indicateurs
Dans cette perspective, l’enjeu est de construire des indicateurs capables de rendre perceptible ce qui ne l’est pas directement. Là où l’observation participante permettait de contextualiser les interactions, l’analyse numérique permet d’extraire des informations que l’œil humain ne peut pas nécessairement repérer.
L’approche ici ne cherche pas à interpréter le sens du mouvement (ce que ferait une IA d’analyse d’émotions, mais sa structure mathématique.
L’analyse de l’image à partir de l’algorithme optical flow s’inscrit dans cette logique. Initialement utilisé en vidéo pour l’interpolation d’images et la génération de mouvements ralentis, cet algorithme repose sur l’estimation du déplacement des pixels entre deux images successives.
Par exemple, produire un ralenti vidéo suppose en principe de filmer à haute fréquence (120 ou 240 images par seconde), alors que le standard reste 25 images par seconde (rendant le mouvement fluide à l’œil humain). À défaut de disposer de camera filmant à 240 images/s, optical flow est utilisé afin d’estimer les images intermédiaires à partir du mouvement apparent.
2. Intérêt de Optical flow
Optical flow permet par exemple le suivi de points d’intérêt spécifiques, tels que les lèvres, les yeux, permettant ainsi une analyse des micro-mouvements du visage.





Dans notre cadre on n’utilise pas optical flow pour créer des images manquantes, mais pour extraire le mouvement existant.
Dans notre cadre, optical flow n’est pas mobilisé pour reconstruire une image, mais pour extraire une structure du mouvement.
Chaque pixel est associé à un vecteur caractérisé par une direction et une magnitude.
2.1 L’image vecteurs
L’image vecteurs montre dans quelle direction et avec quelle force le mouvement se fait entre deux images.

Chaque “flèche” représente un mouvement, la direction de la flèche indique “où” ça bouge, la longueur de la flèche indique l’intensité du mouvement.
2.2 L’image magnitude
La magnitude est la longueur du vecteur de mouvement. Elle mesure l’intensité du déplacement d’un pixel entre deux images. C’est en quelque sorte un indicateur d’énergie du mouvement.

La couleur encode la direction (rouge : mouvement horizontal (droite), cyan : mouvement horizontal (gauche), vert : mouvement vertical (haut), magenta : mouvement vertical (bas) et la luminosité encode l’intensité.
3. Entropie de Shannon
L’entropie ne doit pas être comprise comme un test statistique, mais comme une mesure de dispersion. Elle permet ici de caractériser la distribution d’un ensemble d’états.
L’entropie peut être vue comme une mesure de l’incertitude d’un événement en fonction de la connaissance que nous avons.
L’entropie est une valeur qui quantifie cette incertitude
L’entropie informationnelle et la variance sont toutes deux des mesures de dispersion, mais elles reposent sur des logiques différentes. L’entropie, issue de la théorie de l’information, décrit la répartition d’une distribution de probabilités : elle mesure le degré d’incertitude d’un système en fonction de la manière dont ses états sont distribués.
La variance, en revanche, est une mesure statistique classique qui quantifie l’écart des valeurs autour de leur moyenne :
Si, à ce stade de l’article, la notion d’entropie informationnelle reste encore abstraite, on peut la saisir à partir d’une expérience très simple : celle du « je ne comprends pas ». Cette phrase en donne une image intuitive. Elle désigne un moment où l’information est présente, mais ne s’organise pas encore en une forme suffisamment stable pour produire du sens. C’est cette incertitude, cette dispersion des possibles, que l’entropie informationnelle cherche à déterminer.
La formulation de l’entropie de Shannon est la suivante :
![\[H = - \sum_{i=1}^{n} p_i \log_2(p_i)\]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-6cbf46413a3f90c26c3662d8a8e37ffa_l3.png "Rendered by QuickLaTeX.com")
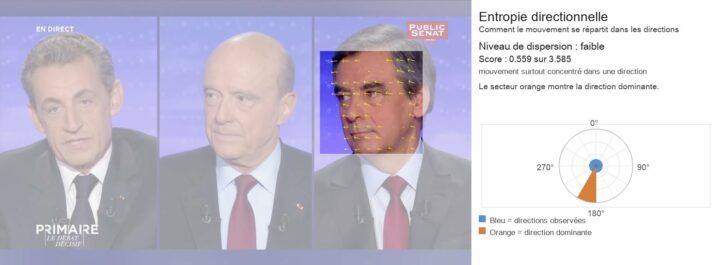
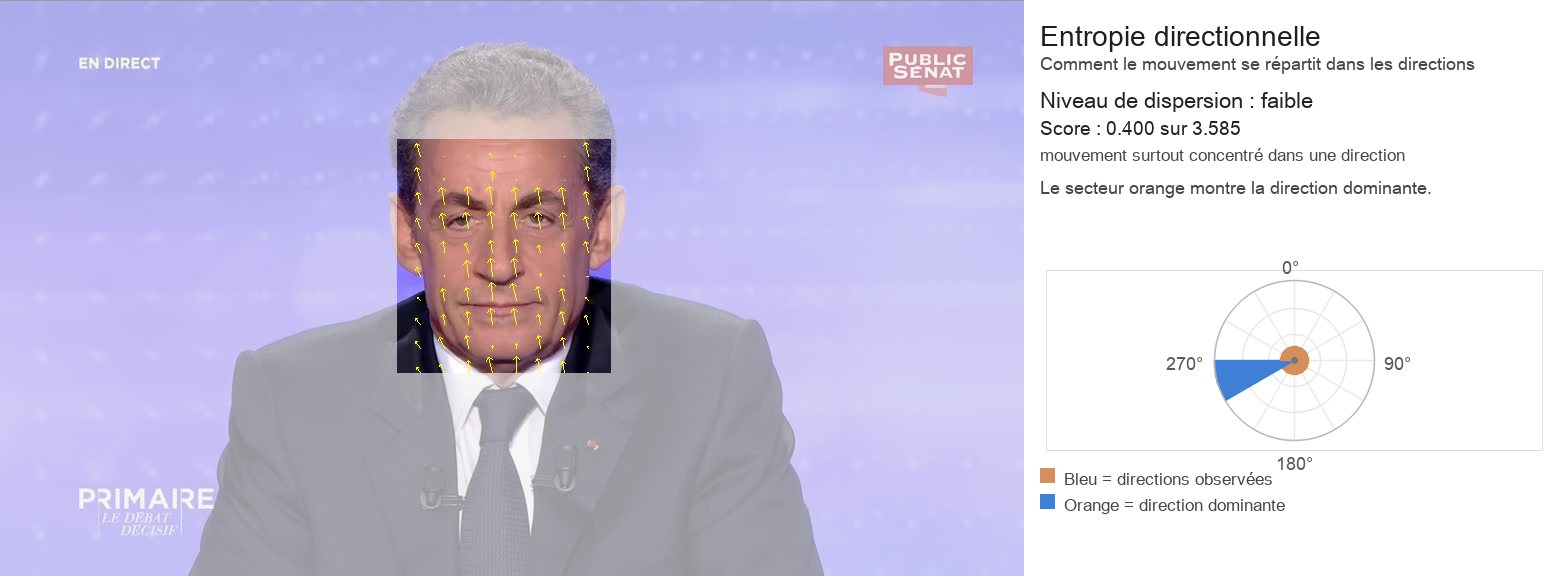
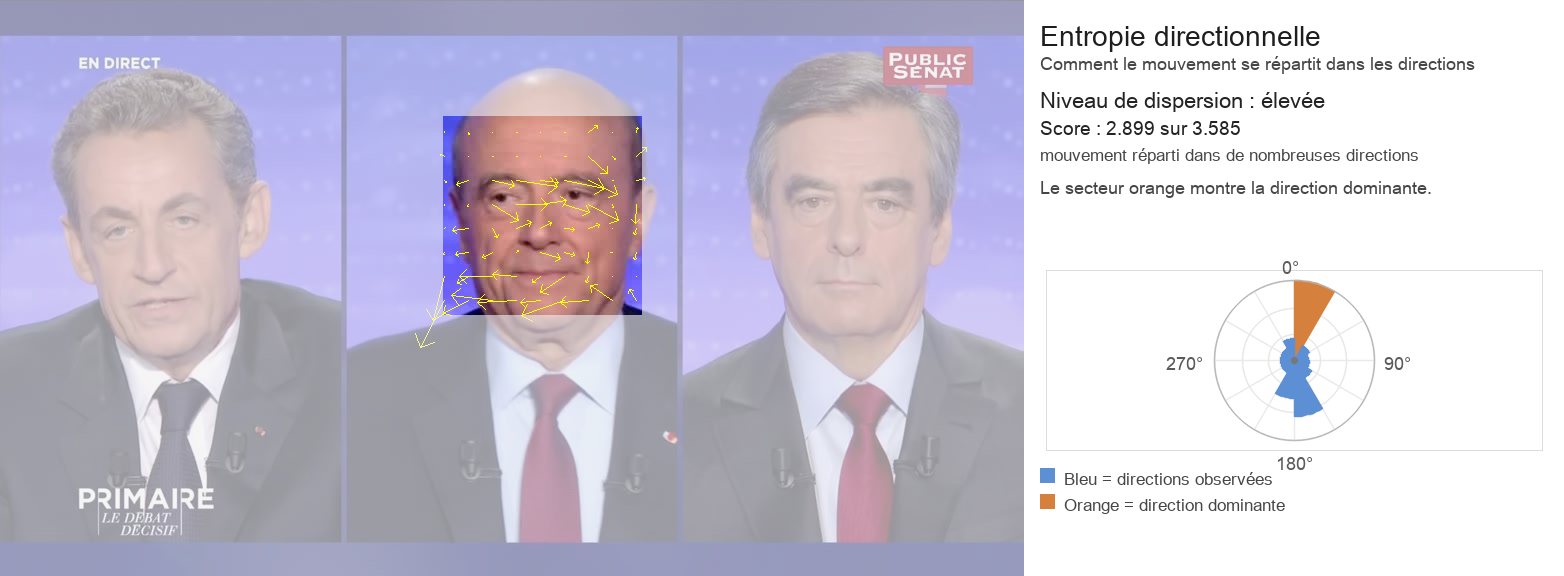
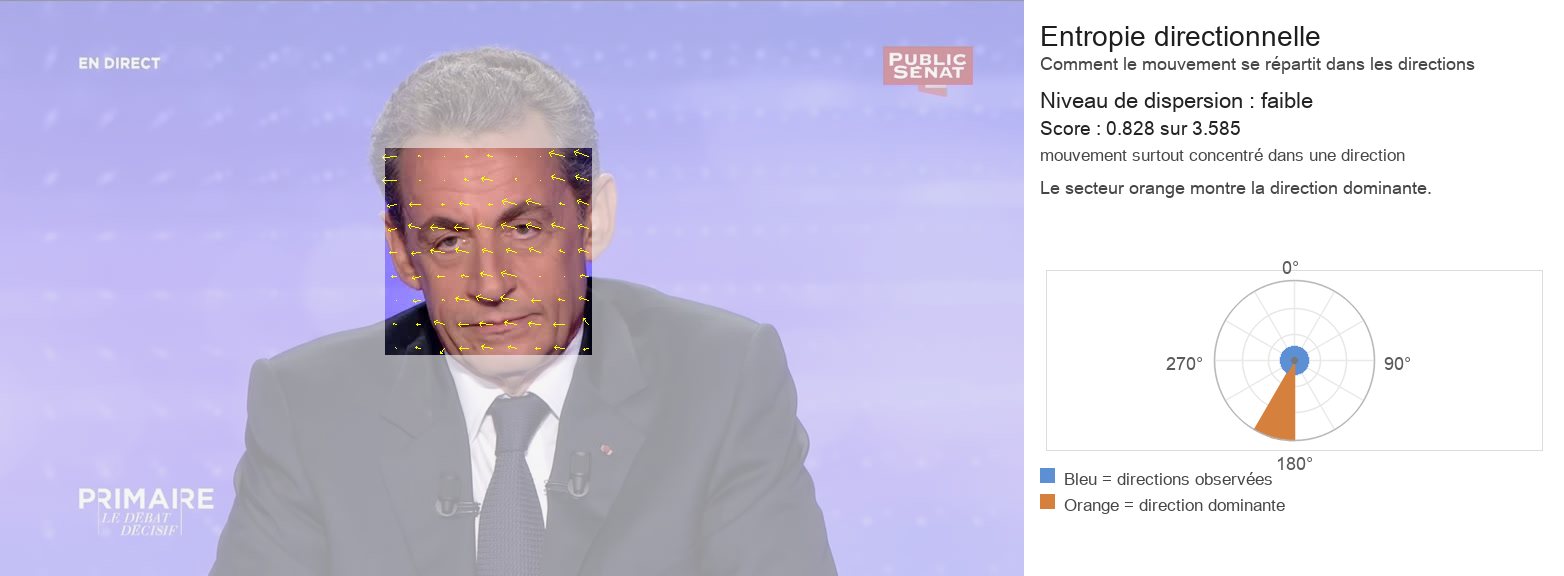
3.1 Entropie directionnelle
L’entropie directionnelle mesure la dispersion d’une distribution (angulaire) du mouvement et permet de caractériser la manière dont le mouvement s’organise :
Une faible entropie correspond à une concentration des orientations autour d’une ou de quelques directions dominantes, traduisant une cohérence directionnelle du mouvement.
Une entropie élevée correspond à une distribution plus uniforme des orientations, traduisant une dispersion des directions de mouvement.
Dans notre cas, le choix de 12 directions (angles) implique que la valeur maximale de l’entropie est atteinte lorsque la distribution est uniforme sur ces 12 secteurs, soit une entropie égale à log₂(12).
![\[H_{dir} = - \sum_{i=1}^{12} p_i \log_2(p_i)\]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-1f0d10fcf29fa836a74acdbc6f2f99b6_l3.png "Rendered by QuickLaTeX.com")
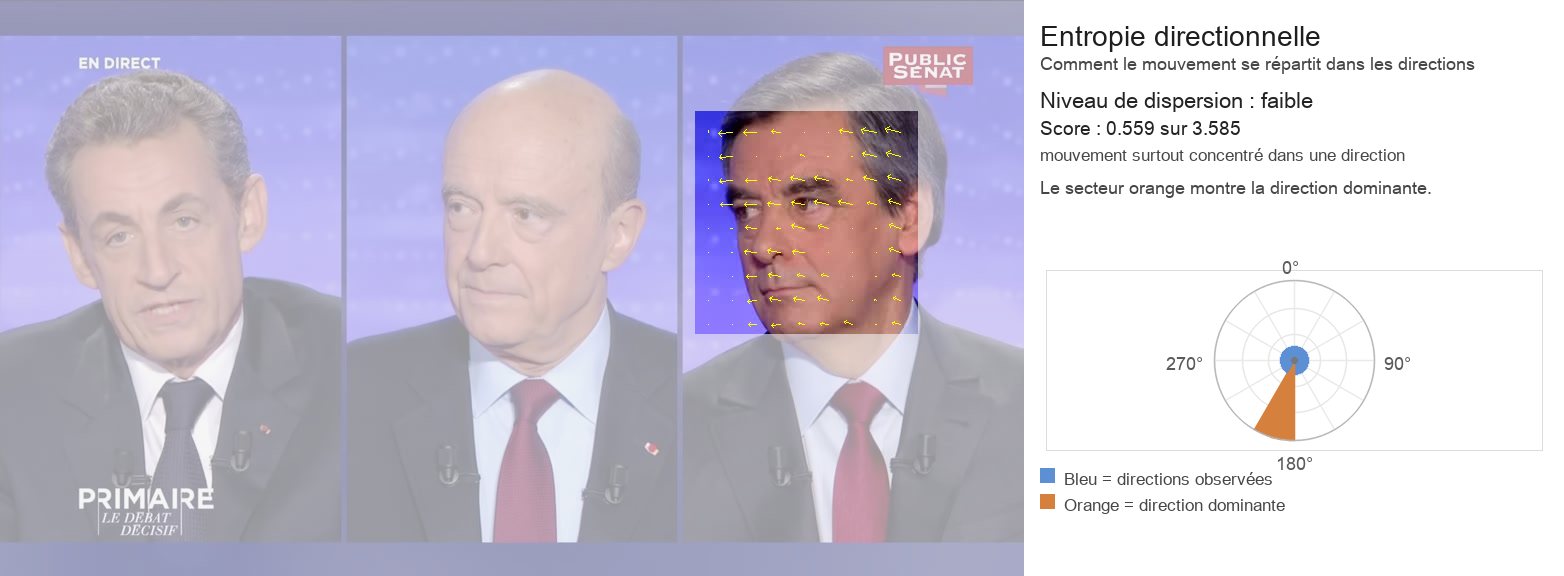
Le logarithme transforme une probabilité (exemple : 1 chance sur 12) en une quantité d’information (log(2)12 = 3,58 bits).
- Si le mouvement est certain (1 seule direction), l’information est de 0.
- Si le mouvement est totalement incertain (réparti sur les 12 directions), l’information est au maximum, soit 3,58.
![\[H_{max} = \log_2(12)\]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-2361edc6b3c33e751869e0369ed6f336_l3.png "Rendered by QuickLaTeX.com")
soit environ 3,58 bits.
![\[\log_2(12) \approx 3.58\]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-fc944e06e393d32db5426298a8270542_l3.png "Rendered by QuickLaTeX.com")
Cette valeur correspond à une situation où le mouvement est totalement dispersé, sans direction dominante.
Dans certains cas, il peut être pertinent de normaliser l’entropie :
![\[H_{norm} = \frac{H_{dir}}{\log_2(12)}\]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-adc707f31dae4914e39d3df66e356c3d_l3.png "Rendered by QuickLaTeX.com")
Conclusion
Le développement d’une approche multimodale ne vise pas à substituer une lecture automatique à l’analyse qualitative, mais à proposer des indicateurs permettant d’enrichir l’observation. Par exemple, dans le cadre des entretiens, notamment en visioconférence, il devient possible de capter simultanément texte, image et audio, et d’en extraire des indicateurs.

La “synchronisation avec le texte” constitue le prochain défi, car, dans le cadre d’une approche multimodale, toute interprétation doit passer par le contexte. Ainsi, comme cela a déjà été réalisé dans l’analyse audio lors d’un précédent script, il est possible de filtrer les scores d’entropie et de recueillir les segments de texte correspondants.