Le preprint de Kosmyna et al., Your brain on ChatGPT : Accumulation of cognitive debt when using an AI assistant for essay writing task” publié en juin 2025, fait l’effet d’une petite “bombe” dans la sphère critique de l’IA.
L’étude s’inscrit, en osant faire le parallèle, avec la réflexion de Anne Alombert sur l’automatisation de l’écriture par les LLM. Dans cette perspective, Anne Alombert compare les LLM aux sophistes que l’on pourrait qualifier de “beaux parleurs/influenceurs” dont le contenu du discours n’est pas le point fondamental.
Autrement dit, l’extension de nos capacités cognitives, qu’il s’agisse de déléguer l’écriture (LLM) ou de s’appuyer sur une mémoire externalisée, fonctionnerait comme un “pharmakon” : remède par l’efficacité de ces dispositifs techniques, poison par ses effets secondaires, notamment dans la structuration de la pensée.

Le point critique tient dans le fait de “déléguer”. Déléguer l’écriture à un LLM, ce n’est pas seulement gagner du temps : c’est aussi court-circuiter une partie du travail cognitif que l’écriture accomplit en structurant la pensée. Or, dans les usages (à distinguer de la “pratique”), l’interaction avec un LLM se réduit souvent à une suite de questions-réponses.
C’est précisément ce “déplacement”, de l’écriture vers “l’assistance”, que mettent en évidence les résultats rapportés par Kosmyna et ses co-auteurs : baisse des connexions neuronales pendant la tâche, et difficultés à citer son propre texte lorsque l’essai a été rédigé avec assistance.
Ainsi, lorsque la mémoire se trouve dématérialisée dans un dispositif technique, le risque n’est pas seulement une fragilisation de la mémoire individuelle, mais un affaiblissement des connexions dans le cerveau.
1. Objectif de l’étude
Dans ce preprint du MIT, Nataliya Kosmyna et ses co-auteurs poursuivent l’hypothèse : mesurer ce que change l’assistance par un LLM pendant une tâche de rédaction, en comparant trois groupes (sans outil, moteur de recherche, LLM) et en observant à la fois l’activité neuronale durant la rédaction et les comportements après la tâche (mémoire du texte, sentiment d’appropriation, satisfaction…).
2. Les sources
Les auteurs ont créé un site web dédié à ce preprint !
Ensuite, mes recherches m’ont conduit à deux versions quasi similaires du preprint, avec parfois des paragraphes plus étayés dans l’une que dans l’autre.
L’article est dense (206 pages)… nous nous concentrerons ici sur l’analyse des réponses des participants au questionnaire administré après la tâche de rédaction.
3. Protocole
A chaque session, les participants rédigent une courte rédaction, toutes issues de sujets de type SAT (test standardisé d’entrée à l’université aux USA). Les participants ont 20 minutes pour produire leur rédaction/essai.
Les auteurs recrutent 54 participants (18–39 ans) diplômés de plusieurs universités et les répartissent aléatoirement en trois groupes de 18 personnes.
- Groupe 1: “Brain-Only“, sans aucune assistance technologique.
- Groupe 2 : “Search-Engine“, utilise un moteur de recherche
- Groupe 3 : “LLM-to-Brain“, dispose d’un accès à GPT-4o
Le protocole s’est étalé sur quatre mois. Pendant la rédaction, les chercheurs ont enregistré l’EEG. À l’issue de la rédaction, ils ont mené l’entretien.
Le groupe “moteur de recherche (“Search-Engine”) peut consulter des sites web mais aucun LLM (ils utilisent Google et ajoutent “-ai” aux requêtes pour “éviter” des réponses enrichies par IA).
“Search Engine Group” : Participants in this group could use any website to help them with their essay writing task, but ChatGPT or any other LLM was explicitly prohibited; all participants used Google as a browser of choice. Google search and other search engines had “-ai” added on any queries, so no AI enhanced answers were used by the “Search Engine group” (page 22)”
Une partie (18 personnes) revient pour une quatrième session, où les auteurs inversent la condition: des utilisateurs LLM passent sans outil (“LLM-to-Brain“) et des participants “Brain-Only” passent au LLM (“Brain-to-LLM“).
4. Résultats
Comme indiqué plus haut, nous allons décortiquer une petite partie des résultats. Nous n’analyserons pas la section “Analyse NLP” : le préprint fait 206 pages…, et il est impossible de tout couvrir ici. La partie concernant les entités nommées (NER) et des n-grams ne seront pas analysés ici.
4.1 Baisse de la connectivité neuronal
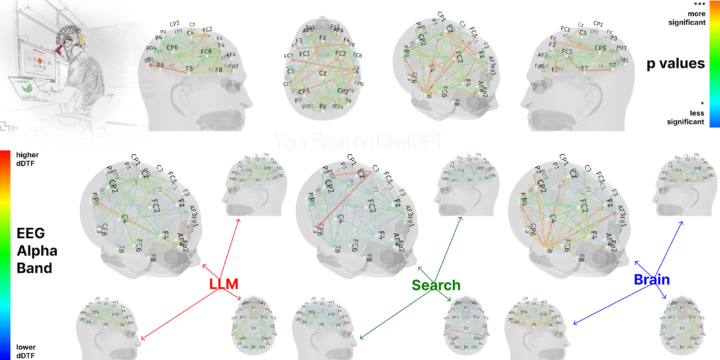
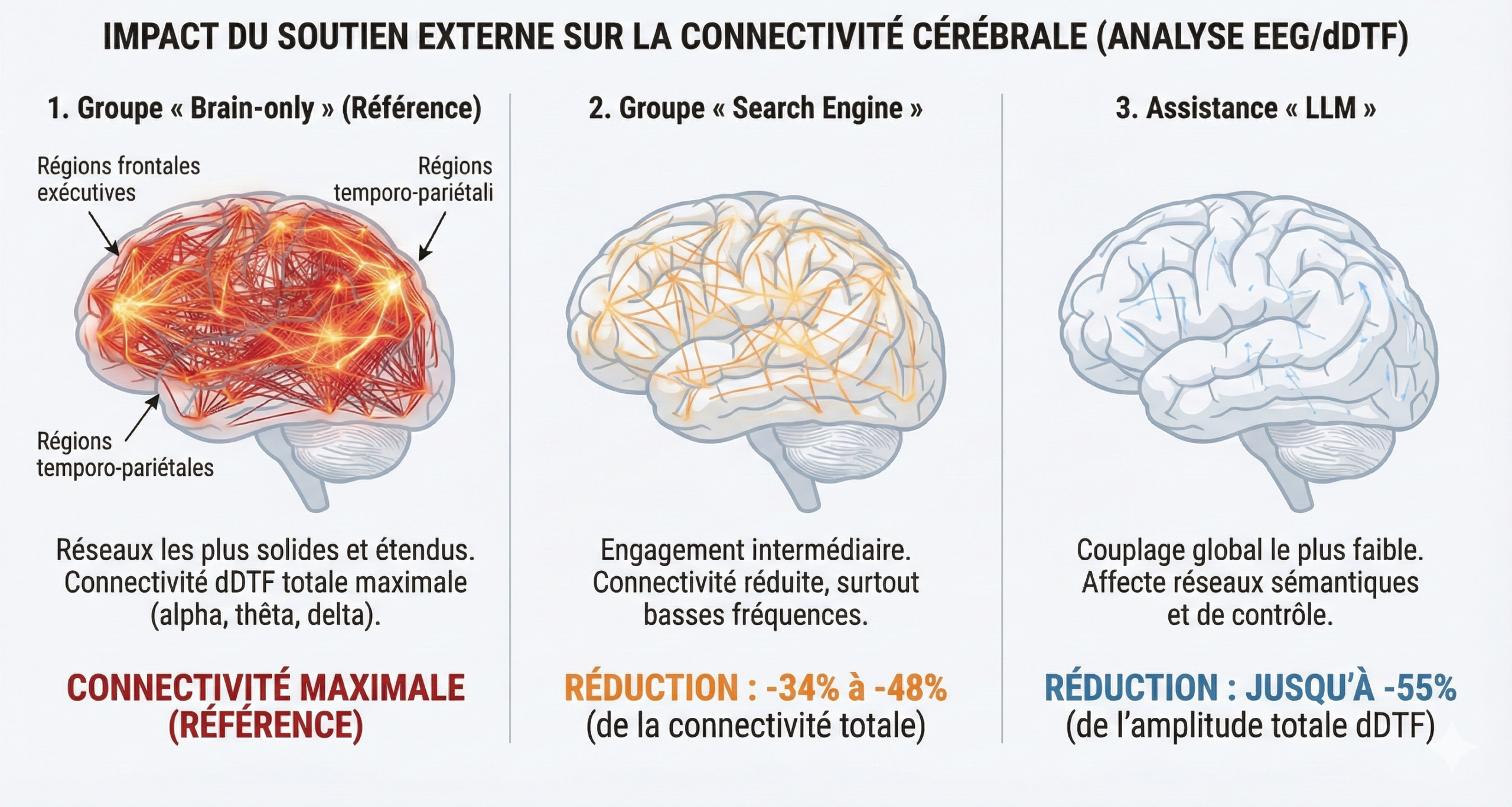
Sur l’EEG, les auteurs observent une diminution de la connectivité neuronale quand l’assistance externe augmente : le groupe “Brain-Only” montre les réseaux les plus activés, le groupe “Search-Engine” est intermédiaire, et le groupe “LLM” présente la connectivité la plus faible.
L’usage d’un LLM s’accompagne d’une diminution de l’activité cérébrale mesurée par EEG de 55 % .
Le groupe utilisant un moteur de recherche classique présente une réduction, située entre 34 % et 48 %.
La connectivité cérébrale a systématiquement diminué en fonction de l’importance du soutien externe : le groupe “Brain-only” (cerveau seul) a présenté les réseaux les plus solides et les plus étendus, le groupe “Search Engine” (moteur de recherche) a montré un engagement intermédiaire, et l’assistance par LLM a suscité le couplage global le plus faible. Les activations et la connectivité étaient les plus marquées dans le groupe “Brain-Only”, qui a systématiquement affiché la connectivité dDTF totale la plus élevée dans les bandes alpha, thêta et delta, particulièrement dans les régions temporo-pariétales et frontales exécutives. Vient ensuite le groupe Search Engine, qui a manifesté une connectivité totale environ 34 à 48 % inférieure à travers le cerveau selon la bande de fréquence, en particulier dans les basses fréquences. Le groupe LLM a montré la connectivité la moins étendue, avec une réduction allant jusqu’à 55 % de l’amplitude totale de la dDTF par rapport au groupe Brain-Only dans les réseaux sémantiques et de contrôle à basse fréquence. (page 136 – traduction française – pdf : ICI)
“Déléguer” (Terme qui renvoie à l’introduction de cet article) une partie de la réflexion à une IA générative ne se limite pas à une assistance, mais s’accompagne d’une baisse de l’activité neuronale mobilisée.
4.2 Activation corticale
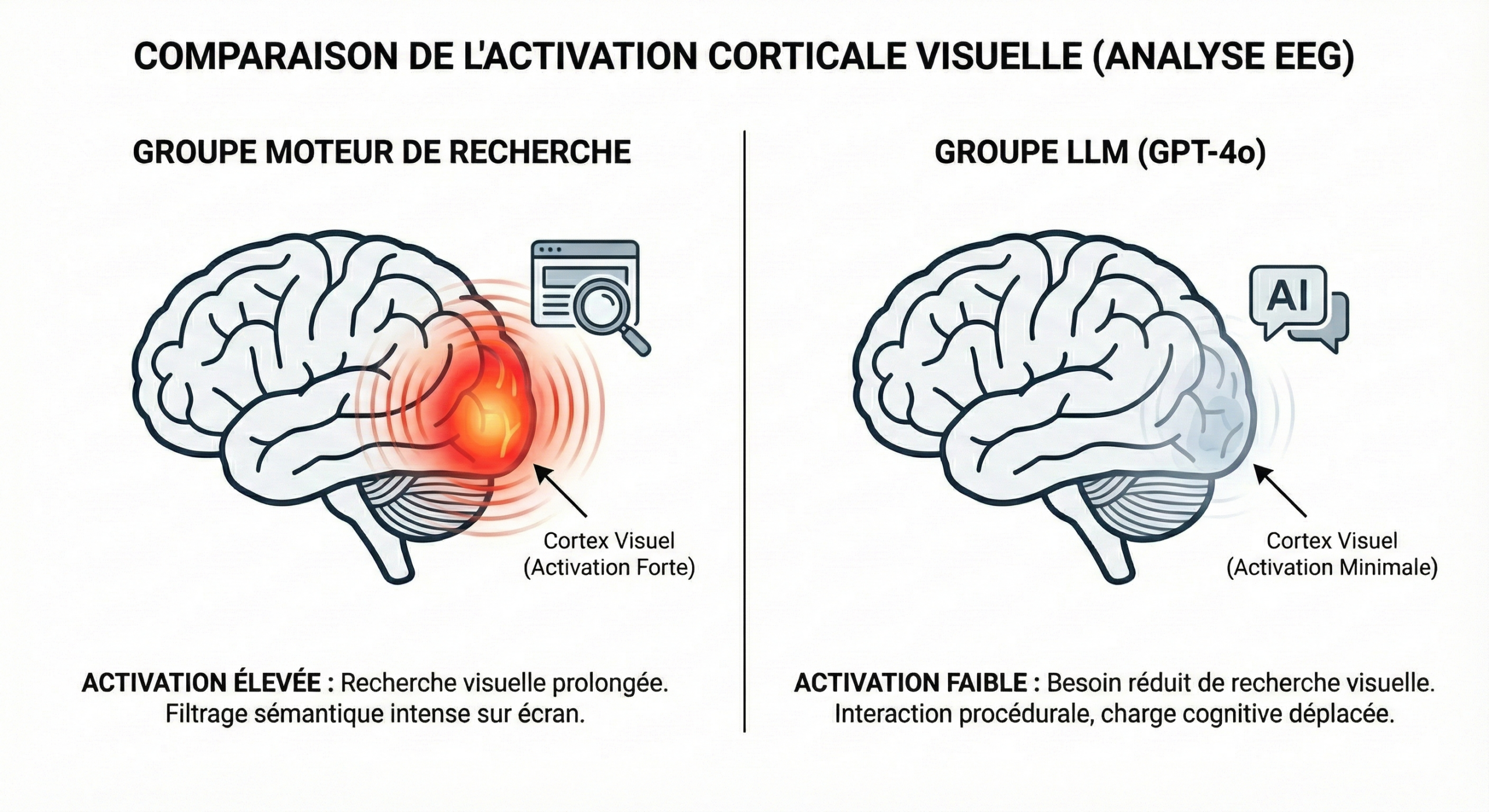
Chez les utilisateurs de moteurs de recherche, on observe une “hyper-activité du cortex occipital”, liée à l’effort de tri et de filtrage des informations.
Un autre (participant) préfère “Internet à ChatGPT pour trouver des sources et des preuves, car ce n’est pas fiable” (P13)
Chez les utilisateurs de LLM, cette activation visuelle est absente, suggérant que l’interaction se limite à une intégration des suggestions de l’IA par du “copier/coller”.
Le groupe “Brain-Only” mobilise principalement les régions associées à l’idéation créative.
5. Défaillance de la mémoire…
Une divergence majeure (Session 1 – question 3 – capacité à citer) a été identifiée concernant la capacité des participants à citer de mémoire leur travail.
Lors de la première session, 83 % des utilisateurs de LLM se sont révélés incapables de fournir une seule citation de leur essai.
Cette “amnésie” du groupe “LLM” semble donc traiter de manière superficielle l’information (Session 1 – question 3 – capacité à citer).
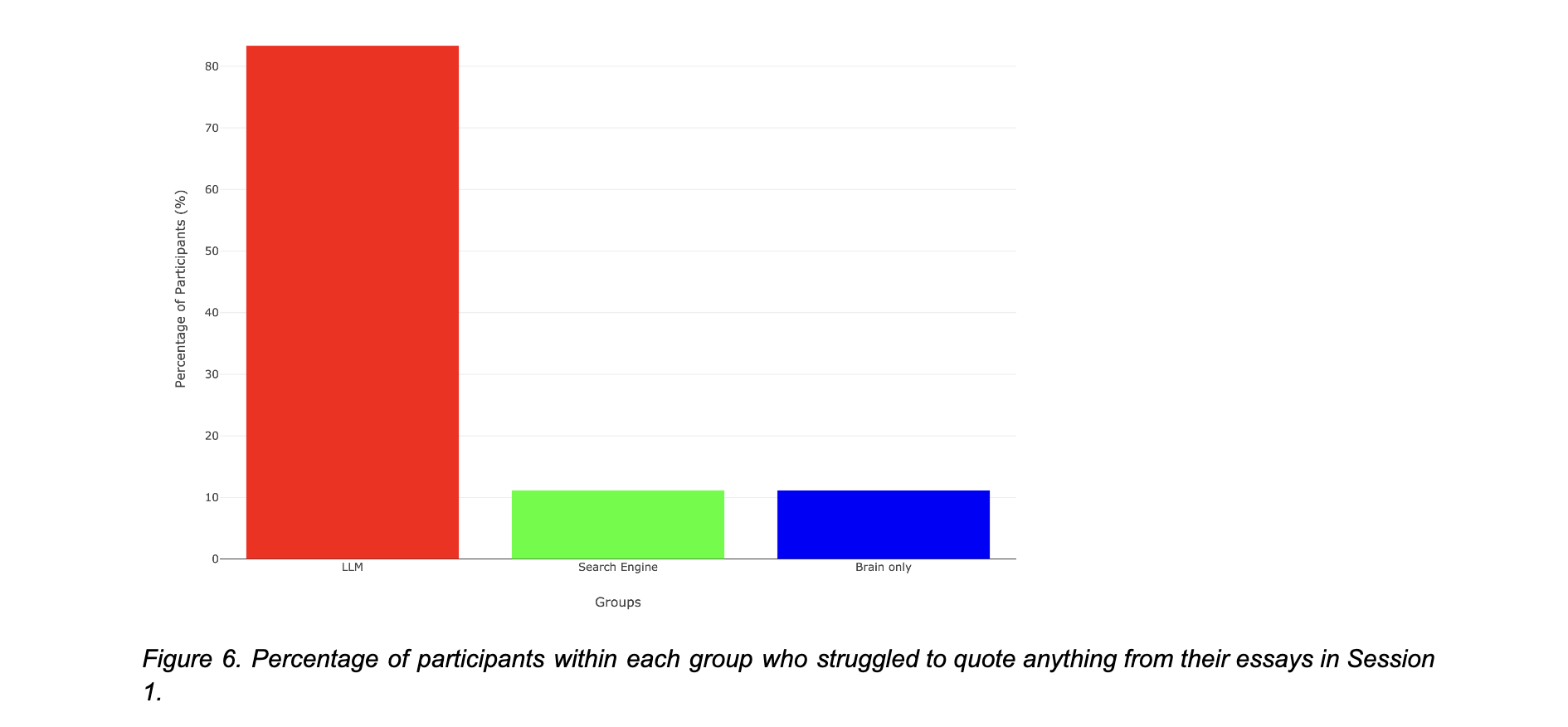
Donc, dans le groupe assisté par LLM, 83,3 % des participants (15/18) n’ont pas réussi à fournir une citation, alors que seuls 11,1 % (2/18) dans les groupes “Search-Engine” et “sans outil” ont rencontré la même difficulté.
5.1 Session 1 – question 4 – Précision des citations
Cette partie de l’étude évalue la précision avec laquelle les participants parviennent à citer leur propre rédaction et elle confirme une divergence entre les groupes (cette question est donc dans la continuité de la question 3).
Dans le groupe LLM, aucun participant (0/18) ne produit de citation correcte.
Les groupes “Search-Engine” et “Brain-Only” obtiennent des performances élevées et proches.
Un participant : “Je pouvais citer précisément parce que je savais où trouver l’information dans mon essai, puisque je l’avais cherchée en ligne.“
Le bilan des sessions 1,2,3 sur la “capacité à citer avec précision” fait émerger un point qualitatif qui rejoint l’étude de Sparrow et al. sur “l’effet Google”.
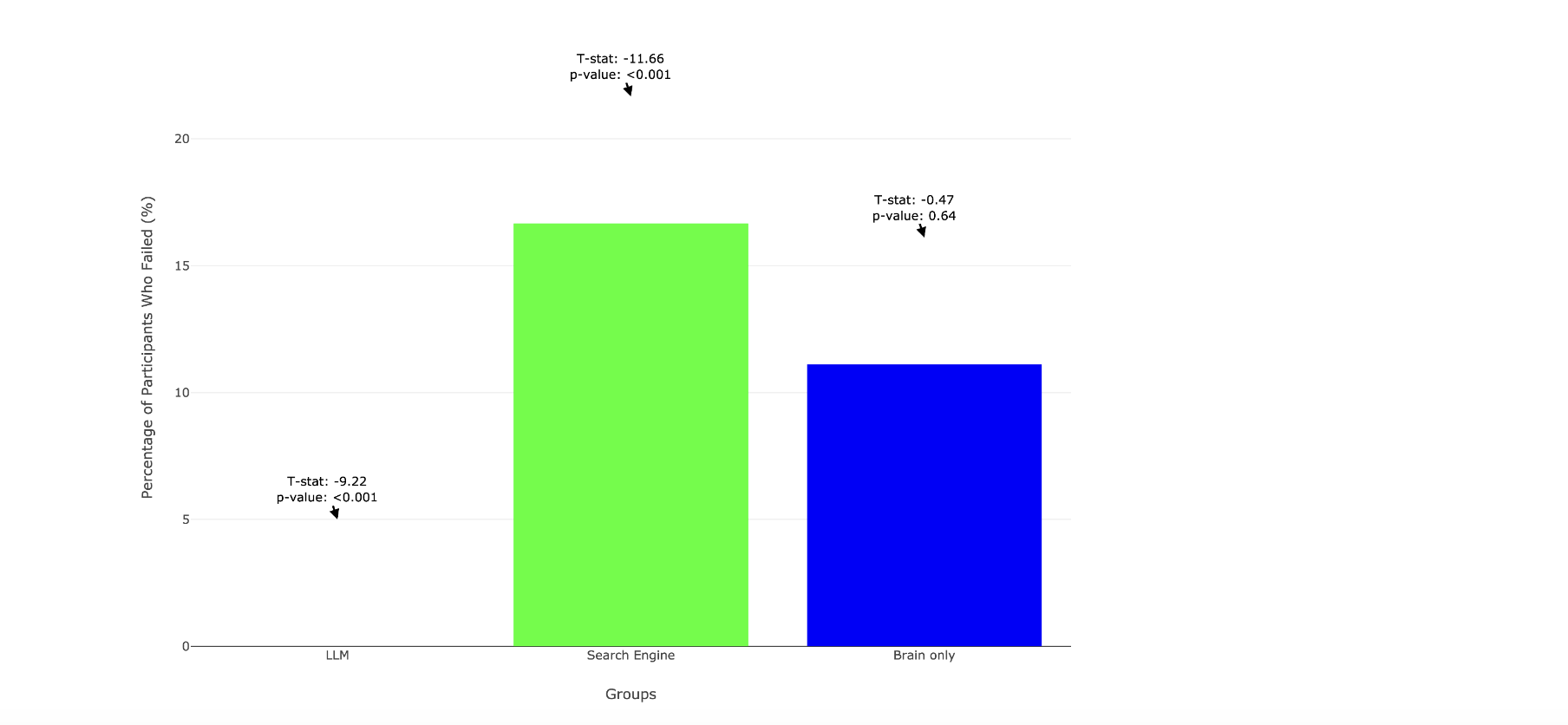
Les es approches nécessitant un effort cognitif (recherche active d’informations) permettent une mémorisation du travail.
5.2 Session 1 – question 5 – sentiment de paternité
Cette question mesure le degré auquel les participants ont le sentiment d’être les auteurs de l’essai qu’ils ont produit.
Les résultats montrent une corrélation entre le niveau d’assistance et la diminution du sentiment de propriété intellectuelle. Le groupe “Brain-Only” affiche le niveau le plus élevé : 16/18 déclarent une pleine panternité.
Le groupe “Search-Engine” ne rapporte aucune absence de propriété, mais la pleine propriété devient minoritaire (6/18), au profit d’une propriété partielle.
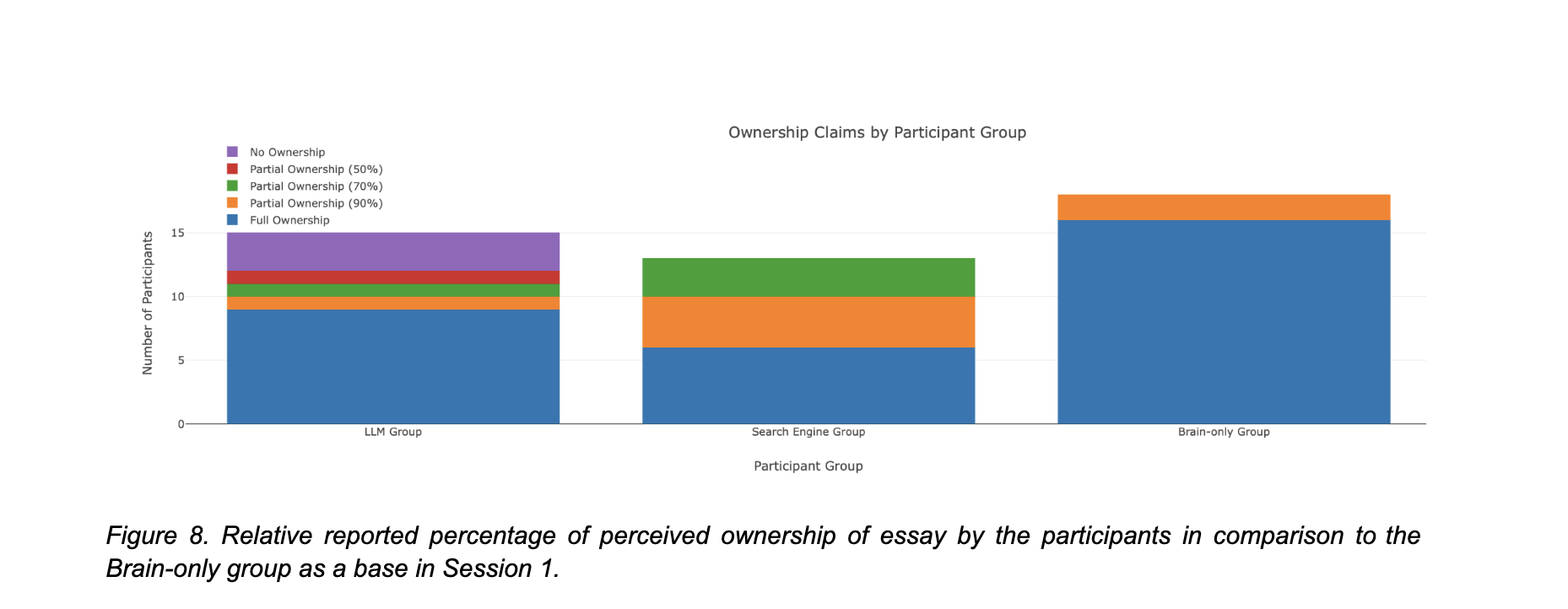
Le groupe “Brain-Only“, met l’accent sur l’autonomie et l’authenticité, notant que l’essai “paraissait très personnel parce qu’il portait sur mes propres expériences” (participant n°50).
Groupe LLM :
Un participant affirme : “L’essai était à environ 50 % à moi. J’ai apporté des idées, et ChatGPT a aidé à les structurer.“
Le groupe LLM est le plus dispersé : 9/18 déclarent une “pleine propriété”, tandis que les autres évoquent une “propriété partielle”, et 3/18 aucune propriété.
5.3 Session 1 – question 6 – perception de la satisfaction
Cette question évalue la satisfaction des participants quant à la qualité de leur travail. Les résultats suggèrent qu’un recours à des aides extérieures est associé à une satisfaction globale plus élevée que l’écriture entièrement autonome.
Dans le groupe “Search-Engine“, la satisfaction est de 18/18 participants se déclarent satisfaits de leur essai. 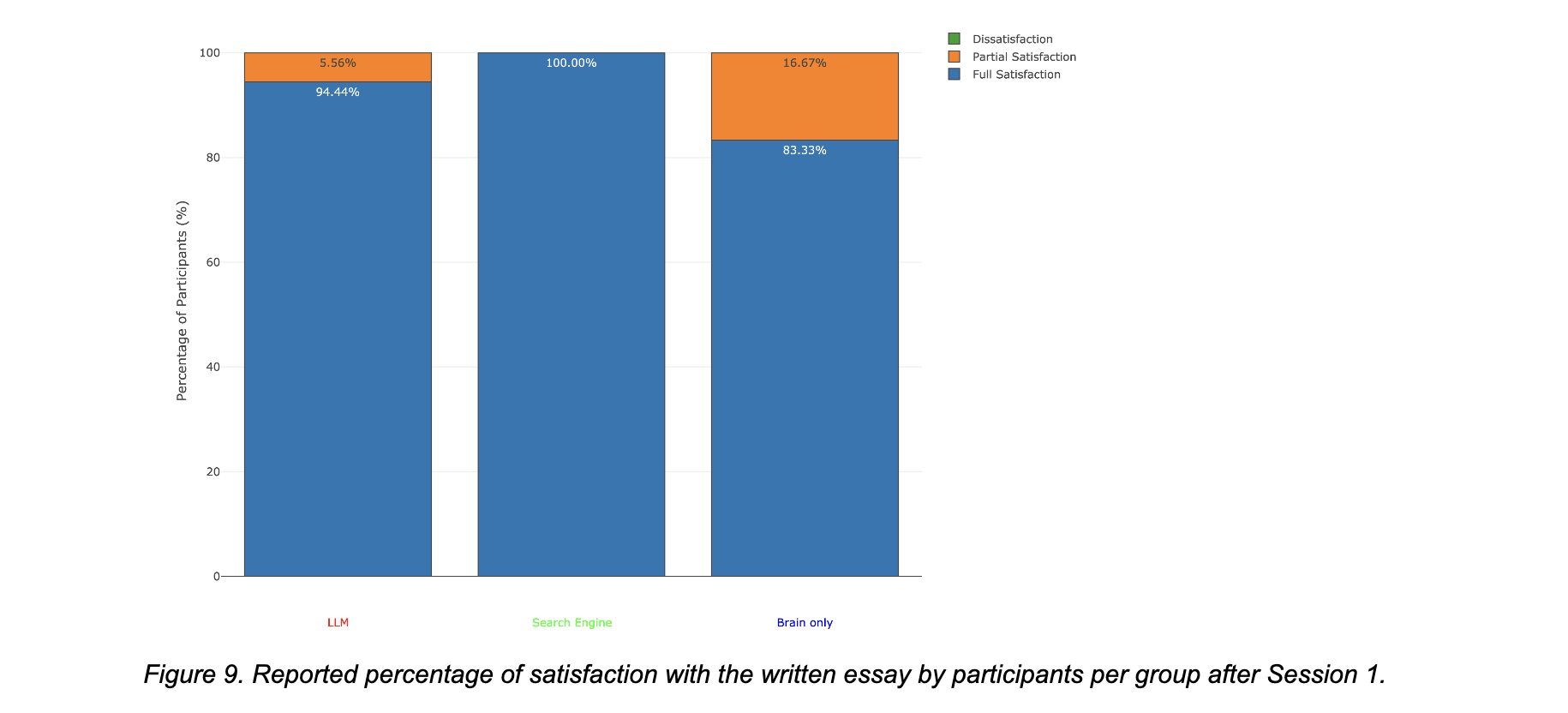
Des participants reconnaissent que le système “m’a aidé à améliorer ma grammaire, mais il n’a pas apporté grand-chose à ma créativité“, qu’il est “bien pour la structure… [mais] pas utile pour générer des idées“, et qu’il “ne pouvait pas m’aider à formuler mes idées comme je le voulais” (session 3).
Le groupe “Brain-Only” affiche des réponses plus contrastées : 15/18 se disent majoritairement satisfaits, tandis que 3/18 expriment des réserves.
5.4 Zoom sur la session 4
Pour rappel, durant la session 4, les participants ont été réaffectés au groupe opposé à celui auquel ils avaient été assignés initialement lors des sessions 1, 2 et 3. En raison des disponibilités des participants et de contraintes de planification, seuls 18 participants ont pu y assister.
Ces personnes ont été placées soit dans le groupe LLM, soit dans le groupe “Brain-Only“.
Les participants ayant commencé sans assistance utilisent ensuite le LLM sans baisse notable de connectivité. À l’inverse, ceux assistés dès le départ ne retrouvent pas une activité comparable lorsqu’ils rédigent seuls : l’activité reste faible et les idées sont plus limitées et répétitives.
Conclusion
Doit-on alors parler de dette cognitive ? La première partie de l’étude met clairement en évidence, au niveau neuronal, des différences entre les trois groupes, et les réponses aux questions vont dans le même sens : le groupe assisté par un LLM pour rédiger un devoir rencontre de réelles difficultés de restitution.
La session 4 révèle aussi les difficultés du groupe LLM, réaffecté en mode “Brain-Only“, à faire face à la rédaction en mobilisant uniquement ses connaissances et son réseau neuronal.
Cela constitue un double constat, à la fois neurologique et comportemental par une forte dépendance à la technique.