Introduction
L’objectif de cet article est de vous proposer un script Python (avec une interface tkinter) visant à rechercher les articles en doublons et les articles trop courts dans un corpus Europresse.
Si vous traitez souvent des corpus d’articles provenant de la base de données Europresse pour vos analyses dans IRaMuTeQ, vous êtes confronté au problème des doublons ou d’articles trop courts dans le corpus.
Pour pallier à cela, vous avez la possibilité de filtrer manuellement en cochant ou décochant les articles que vous souhaitez exporter à partir de la plateforme Europresse.
Cette solution de filtrage à la source de l’export est une technique qui fonctionne, mais elle est chronophage.
Nettoyage à l’aide du script
J’ai développé une interface en Python qui simplifie ce processus, permettant une gestion rapide et efficace des articles en double ou trop courts avant leur importation dans IRaMuTeQ. Il est important de noter que ce script est conçu pour être utilisé avec un corpus Europresse pré-traité pour IRaMuTeQ. Cela signifie que chaque première ligne de chaque article doit être composée de variables étoilées.
Le script utilise les “****” de chaque première ligne pour identifier l’article et scanner le texte à partir de la seconde ligne. Le pré-traitement de votre fichier au format IRaMuTeQ est donc un prérequis pour que le script fonctionne correctement.
Ce prétraitement peut être réalisé manuellement ou à l’aide de ce script (article 1 – article 2– l’application en ligne – v3).
Votre corpus doit donc avoir ce format/encodage (encodage classique pour un traitement avec IRaMuTeQ) avant d’exécuter le script de nettoyage des articles.
Le script
Le script repose sur la technique du hachage. Le hachage est une processus qui permet de transformer des données de différentes tailles en une valeur de taille fixe.
Le script utilise la bibliothèque hashlib pour effectuer le hachage des articles.
Prenons un exemple pour illustrer le fonctionnement du hachage :
Dans le premier cas, supposons que nous ayons deux articles avec le même contenu, bien que leur première ligne (étoilée) puisse être différente. Même si les titres sont différents, le texte des articles est identique, avec les mêmes mots et les mêmes phrases. Lorsque ces deux articles sont soumis à la fonction de hachage, ils produisent tous deux la même valeur de hachage (la même empreinte en quelque sorte). Cela signifie que le résultat de la fonction de hachage est le même pour ces deux articles, ce qui indique qu’ils ont un contenu identique.
Dans le deuxième cas, considérons deux articles qui diffèrent l’un de l’autre. Ils peuvent avoir des mots ou des phrases différents, ce qui les rend distincts. Lorsque ces deux articles sont soumis à la fonction de hachage, ils produisent des valeurs de hachage différentes. Cela signifie que le résultat de la fonction de hachage est unique pour chaque article, indiquant ainsi qu’ils ont un contenu différent.
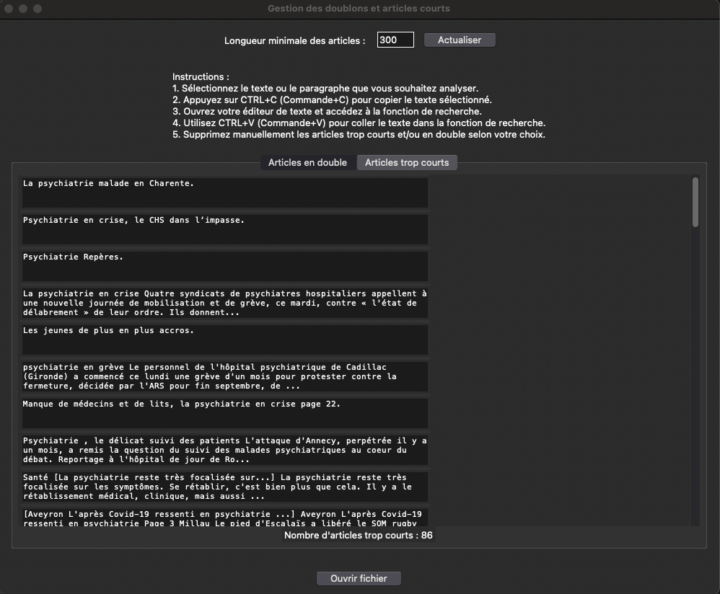
Détection des articles en double
L’export de corpus provenant de sites comme Europresse peut générer des doublons, ce qui rend l’analyse dans IRaMuTeQ moins précise. L’interface utilise un algorithme de hachage pour identifier rapidement les articles en double. Une fois détectés, ces doublons sont affichés dans un onglet distinct pour une suppression facile avant l’importation dans IRaMuTeQ.
Détection des articles trop courts
Dans l’interface, vous pouvez définir un nombre minimum de caractères pour détecter les “articles trop courts”.
Dans Europresse, il n’est pas rare de rencontrer des éditos ou des sommaires de journaux dépourvus du contenu principal de l’article.
Ces articles sont ensuite répertoriés dans un onglet distinct, vous permettant de les examiner et de les éditer pour éventuellement les supprimer de votre corpus.

Gestion manuelle de la suppression des articles
Bien que l’interface facilite la détection des doublons et des articles trop courts, j’ai délibérément choisi de maintenir la phase de suppression manuelle. Cela s’explique en partie par quelques difficultés rencontrées dans le code Python, mais d’un autre côté, cela présente également des avantages. En laissant cette étape à l’utilisateur, cela lui permet d’avoir un contrôle total sur le processus de suppression.

Le process se résume ainsi :
- Enregistrez d’abord votre fichier texte (corpus IRaMuTeQ) sous un nouveau nom (pour travailler sur une copie)
- Lancez le script
- Ouvrez votre fichier texte formaté pour IRaMuTeQ
- L’onglet “nombre de caractères” n’affecte que le filtrage des articles “trop courts”. Vous pouvez définir le nombre de caractères pour chaque article
- Ce paramètre est dynamique : le résultat en bas de la boîte de dialogue indique le nombre d’articles filtrés
- Copiez l’article (commande+C)
- Collez (Commande+V) l’article dans l’éditeur de texte avec votre corpus et activez la fonction recherche dans l’éditeur de texte
- Supprimez l’article
- Enregistrez votre fichier texte (votre corpus)
# Importation des bibliothèques nécessaires
import tkinter as tk
from tkinter import ttk, filedialog, simpledialog, messagebox
import hashlib # Pour le hachage des articles
import pyperclip # Pour copier le texte dans le presse-papiers
# Longueur minimale par défaut des articles
LONGUEUR_MINIMALE_PAR_DEFAUT = 300
def detecter_doublons(chemin_fichier, longueur_minimale):
"""Fonction pour détecter les doublons et les articles trop courts dans un fichier texte."""
articles_uniques = {}
articles_doublons = []
articles_courts = []
with open(chemin_fichier, 'r', encoding='utf-8') as fichier:
contenu_article = []
entete_article = ''
debut_article = False
for ligne in fichier:
if ligne.startswith('**** '): # Ligne de début d'article
if debut_article: # Si on est déjà dans un article
corps_article = ''.join(contenu_article)
texte_article = entete_article + corps_article
hash_article = hashlib.sha256(corps_article.encode('utf-8')).hexdigest()
# Vérification des doublons
if hash_article in articles_uniques:
if len(corps_article) > len(articles_uniques[hash_article][1]):
articles_doublons.append(
(articles_uniques[hash_article][0], articles_uniques[hash_article][1]))
articles_uniques[hash_article] = (entete_article, corps_article)
else:
articles_doublons.append((entete_article, corps_article))
else:
articles_uniques[hash_article] = (entete_article, corps_article)
# Vérification de la longueur minimale
if len(corps_article) < longueur_minimale:
articles_courts.append((entete_article, corps_article))
contenu_article = []
entete_article = ligne
else:
debut_article = True
entete_article = ligne
else:
contenu_article.append(ligne)
# Traitement du dernier article
if contenu_article:
corps_article = ''.join(contenu_article)
texte_article = entete_article + corps_article
hash_article = hashlib.sha256(corps_article.encode('utf-8')).hexdigest()
if hash_article in articles_uniques:
if len(corps_article) > len(articles_uniques[hash_article][1]):
articles_doublons.append((articles_uniques[hash_article][0], articles_uniques[hash_article][1]))
articles_uniques[hash_article] = (entete_article, corps_article)
else:
articles_doublons.append((entete_article, corps_article))
else:
articles_uniques[hash_article] = (entete_article, corps_article)
if len(corps_article) < longueur_minimale:
articles_courts.append((entete_article, corps_article))
return articles_uniques, articles_doublons, articles_courts
def ouvrir_fichier():
"""Fonction pour ouvrir un fichier texte contenant des articles."""
chemin_fichier = filedialog.askopenfilename(title="Sélectionnez le fichier texte des articles")
if chemin_fichier:
global articles_uniques, articles_doublons, articles_courts, chemin_fichier_actuel
chemin_fichier_actuel = chemin_fichier
detecter_et_afficher()
def detecter_et_afficher():
"""Fonction pour détecter et afficher les doublons et les articles trop courts."""
longueur_minimale = int(longueur_minimale_var.get())
articles_uniques, articles_doublons, articles_courts = detecter_doublons(chemin_fichier_actuel, longueur_minimale)
afficher_articles(articles_doublons, articles_courts)
def extraire_texte(texte_article, longueur=50):
"""Fonction pour extraire un texte à partir d'un article."""
lignes = texte_article.split('\n')
if len(lignes) > 1:
return lignes[1][:longueur] + '...' if len(lignes[1]) > longueur else lignes[1]
return texte_article[:longueur] + '...' if len(texte_article) > longueur else texte_article
def afficher_menu_contextuel(event, widget):
"""Fonction pour afficher un menu contextuel pour copier du texte."""
menu = tk.Menu(root, tearoff=0)
menu.add_command(label="Copier", command=lambda: copier_texte(widget))
menu.post(event.x_root, event.y_root)
def copier_texte(widget):
"""Fonction pour copier du texte dans le presse-papiers."""
try:
selection = widget.selection_get()
pyperclip.copy(selection)
except tk.TclError:
pass
def afficher_articles(articles_doublons, articles_courts):
"""Fonction pour afficher les doublons et les articles trop courts dans l'interface graphique."""
for widget in doublons_scrollable_frame.winfo_children():
widget.destroy()
for widget in courts_scrollable_frame.winfo_children():
widget.destroy()
doublons_count_label.config(text=f"Nombre d'articles en double : {len(articles_doublons)}")
courts_count_label.config(text=f"Nombre d'articles trop courts : {len(articles_courts)}")
# Affichage des doublons
for entete, corps in articles_doublons:
texte_article = entete + corps
text_field = tk.Text(doublons_scrollable_frame, height=3, wrap="word")
text_field.insert("1.0", extraire_texte(texte_article, 200))
text_field.config(state="normal")
text_field.pack(anchor='w', fill='x', expand=True, pady=2)
text_field.bind("<Button-3>", lambda event, widget=text_field: afficher_menu_contextuel(event, widget))
# Affichage des articles trop courts
for entete, corps in articles_courts:
texte_article = entete + corps
text_field = tk.Text(courts_scrollable_frame, height=3, wrap="word")
text_field.insert("1.0", extraire_texte(texte_article, 200))
text_field.config(state="normal")
text_field.pack(anchor='w', fill='x', expand=True, pady=2)
text_field.bind("<Button-3>", lambda event, widget=text_field: afficher_menu_contextuel(event, widget))
# Création de la fenêtre principale
root = tk.Tk()
root.title("Gestion des doublons et articles courts")
root.geometry('1000x800')
root.eval('tk::PlaceWindow . center')
# Création de la zone pour le paramétrage de la longueur minimale des articles
longueur_minimale_frame = tk.Frame(root)
longueur_minimale_frame.pack(fill='x', pady=10)
center_frame = tk.Frame(longueur_minimale_frame)
center_frame.pack(anchor='center')
longueur_minimale_label = tk.Label(center_frame, text="Longueur minimale des articles :")
longueur_minimale_label.pack(side='left', padx=5, pady=5)
longueur_minimale_var = tk.StringVar(value=str(LONGUEUR_MINIMALE_PAR_DEFAUT))
longueur_minimale_entry = tk.Entry(center_frame, textvariable=longueur_minimale_var, width=5)
longueur_minimale_entry.pack(side='left', padx=5, pady=5)
actualiser_bouton = ttk.Button(center_frame, text="Actualiser", command=detecter_et_afficher)
actualiser_bouton.pack(side='left', padx=5, pady=5)
# Instructions pour l'utilisation de l'interface
instruction_label = tk.Label(root, text=(
"Instructions :\n"
"1. Sélectionnez le texte ou le paragraphe que vous souhaitez analyser.\n"
"2. Appuyez sur CTRL+C (Commande+C) pour copier le texte sélectionné.\n"
"3. Ouvrez votre éditeur de texte et accédez à la fonction de recherche.\n"
"4. Utilisez CTRL+V (Commande+V) pour coller le texte dans la fonction de recherche.\n"
"5. Supprimez manuellement les articles trop courts et/ou en double selon votre choix."
), wraplength=800, justify="left")
instruction_label.pack(pady=10)
# Création des onglets pour afficher les doublons et les articles trop courts
tab_control = ttk.Notebook(root)
tab_doublons = ttk.Frame(tab_control)
tab_courts = ttk.Frame(tab_control)
tab_control.add(tab_doublons, text='Articles en double')
tab_control.add(tab_courts, text='Articles trop courts')
tab_control.pack(expand=1, fill='both')
# Cadre pour afficher les doublons
doublons_frame = tk.Frame(tab_doublons)
doublons_canvas = tk.Canvas(doublons_frame)
doublons_scrollbar = ttk.Scrollbar(doublons_frame, orient="vertical", command=doublons_canvas.yview)
doublons_scrollable_frame = ttk.Frame(doublons_canvas)
doublons_scrollable_frame.bind(
"<Configure>",
lambda e: doublons_canvas.configure(
scrollregion=doublons_canvas.bbox("all")
)
)
doublons_canvas.create_window((0, 0), window=doublons_scrollable_frame, anchor="nw")
doublons_canvas.configure(yscrollcommand=doublons_scrollbar.set)
doublons_frame.pack(fill='both', expand=True)
doublons_canvas.pack(side="left", fill="both", expand=True)
doublons_scrollbar.pack(side="right", fill="y")
# Cadre pour afficher les articles trop courts
courts_frame = tk.Frame(tab_courts)
courts_canvas = tk.Canvas(courts_frame)
courts_scrollbar = ttk.Scrollbar(courts_frame, orient="vertical", command=courts_canvas.yview)
courts_scrollable_frame = ttk.Frame(courts_canvas)
courts_scrollable_frame.bind(
"<Configure>",
lambda e: courts_canvas.configure(
scrollregion=courts_canvas.bbox("all")
)
)
courts_canvas.create_window((0, 0), window=courts_scrollable_frame, anchor="nw")
courts_canvas.configure(yscrollcommand=courts_scrollbar.set)
courts_frame.pack(fill='both', expand=True)
courts_canvas.pack(side="left", fill="both", expand=True)
courts_scrollbar.pack(side="right", fill="y")
# Labels pour afficher le nombre d'articles en double et trop courts
doublons_count_label = tk.Label(tab_doublons, text="Nombre d'articles en double : 0")
doublons_count_label.pack()
courts_count_label = tk.Label(tab_courts, text="Nombre d'articles trop courts : 0")
courts_count_label.pack()
# Bouton pour ouvrir un fichier texte
bouton_ouvrir_fichier = ttk.Button(root, text="Ouvrir fichier", command=ouvrir_fichier)
bouton_ouvrir_fichier.pack(pady=10)
# Activation du menu contextuel pour copier du texte
root.bind("<Button-3>", afficher_menu_contextuel)
# Lancement de l'interface graphique
root.mainloop()
Conclusion
Cette interface offre une solution pratique et intuitive pour traiter les corpus d’articles Europresse avant leur analyse dans IRaMuTeQ.
En détectant rapidement les doublons et les articles trop courts, elle simplifie le processus de nettoyage des données, permettant une analyse textuelle plus précise et efficace dans IRaMuTeQ.
[…] Si vous exécutez auto-py-to-exe sur Windows, il générera un fichier exécutable .exe compatible avec Windows. Dans mon exemple, j’ai choisi de compiler le script permettant de rechercher les doublons et les articles trop courts dans Europresse. L’article et le script sont disponibles ici. […]
[…] de doublons Europresse : Cet outil identifie les doublons et les articles trop courts dans les fichiers provenant d’Europresse, garantissant ainsi que […]