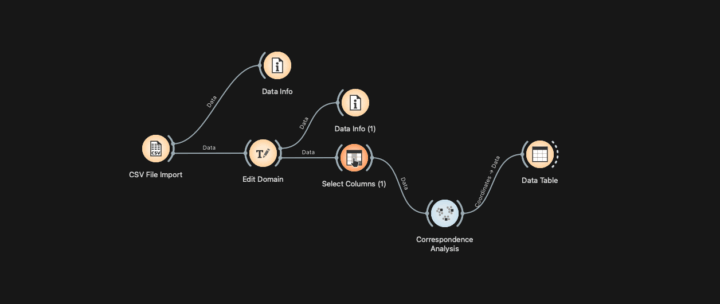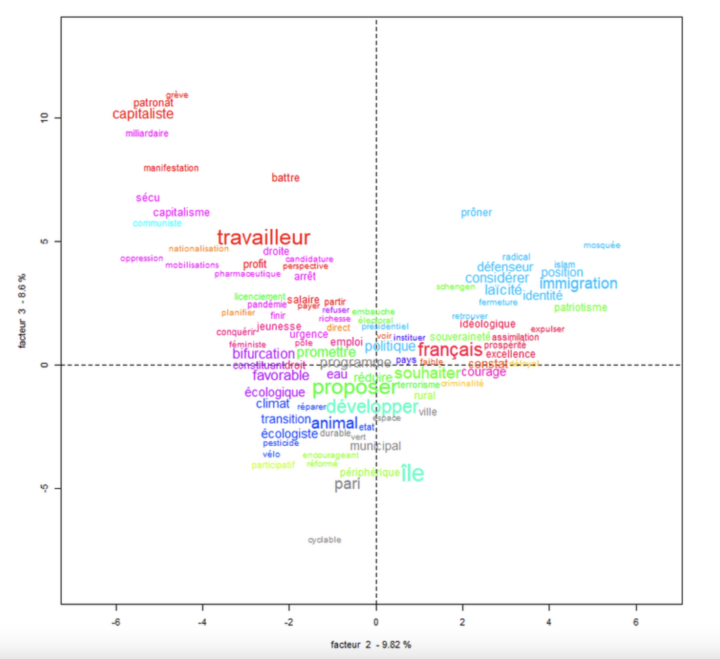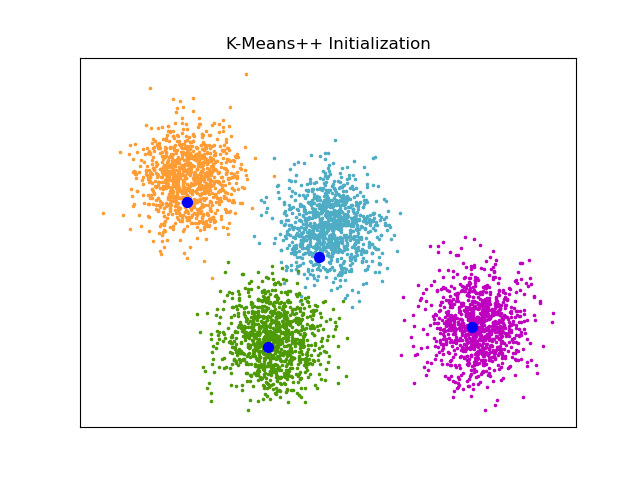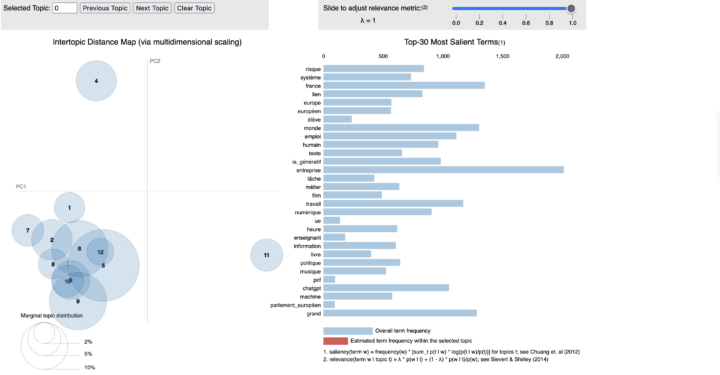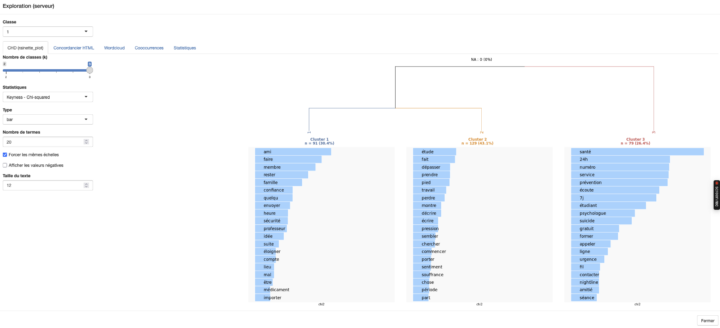
L’enjeu ici est de développer, sur un serveur distant, un script permettant de réaliser une CHD, une AFC et d’autres tests, tels que l’analyse des entités nommées (NER) et l’analyse de cooccurrences. J’avais déjà développé, dans un article précédent, la mise en œuvre du package rainette développé par Julien Barnier. C’est à partir de cette base que j’ai transposé le script en application sur le...