
Le concept TF-IDF (Term Frequency – Inverse Document Frequency) a émergé dans les années 1970 dans le champ de la recherche d’information, notamment grâce aux travaux de Karen Spärck Jones, chercheuse britannique. Elle a posé les bases de l’idée que les termes rares à l’échelle d’un corpus ont plus de valeur discriminante que les termes fréquents, en particulier pour classer des documents pertinents face à une requête.
La justification théorique de ce test avec pondération des termes s’appuie sur un constat empirique bien connu en linguistique statistique, décrit par la loi de Zipf, qui observe la distribution des mots dans les textes. Lorsqu’une requête contient un terme T, un document a d’autant plus de chances de répondre à cette requête que la fréquence de ce terme dans le document (TF) est élevée.
Cependant, si le terme “T” est largement réparti dans l’ensemble du corpus, c’est-à-dire qu’il apparaît dans plusieurs documents, comme c’est le cas pour les stopwords : « le », « la », « les »…, il devient peu discriminant.
L’objectif ici est de sensibiliser les étudiants à une approche qui s’écarte de l’analyse basique des distributions en fréquences. Le calcul de TF-IDF ne se contente pas de repérer les mots les plus fréquents ; il met en avant ceux qui sont réellement spécifiques, en tenant compte de leur rareté dans l’ensemble du corpus.
C’est pourquoi le test TF-IDF combine ces deux dimensions : il augmente le poids des termes dont la fréquence (TF) est élevée et dont la répartition globale (IDF) est faible, c’est-à-dire des termes rares dans le corpus. Ainsi, la présence d’un terme peu fréquent à l’échelle des documents mais présent dans un document donné contribue fortement à augmenter le score de pertinence de ce document vis-à-vis de la requête.
Aujourd’hui, même si Google ne se limite plus à TF-IDF, l’idée générale reste de comprendre quels termes sont caractéristiques d’une page pour les relier aux intentions de recherche.
1. La théorie
La méthode TF-IDF, pour Term Frequency – Inverse Document Frequency, repose sur une formule simple mais puissante qui combine deux éléments clés. Le premier, TF (Term Frequency), mesure la fréquence relative d’un terme dans un document donné, c’est-à-dire le nombre de fois où le terme apparaît, rapporté au nombre total de termes dans ce document. Le second, IDF (Inverse Document Frequency), mesure l’importance du terme à l’échelle du corpus complet : plus un terme est rare dans l’ensemble des documents, plus son poids augmente.

La combinaison des deux permet d’identifier les termes qui sont non seulement fréquents localement, mais aussi spécifiques au document par rapport au reste du corpus. C’est précisément cette capacité à pondérer les mots rares qui fait la force de l’approche TF-IDF. Sans l’IDF, on obtiendrait simplement un comptage brut des mots les plus utilisés, souvent dominé par des termes génériques ou des mots fonctionnels (par exemple : « est », « les », « pour »).
- t => représente le terme (mot-clé)
- d => représente le document
- D => représente le corpus (ensemble des documents)
1.2 Calcul de TF

1.3 Calcul de IDF

TF-IDF est un score, une mesure de pondération :
- Il ne teste pas d’hypothèse
- Il ne produit pas de valeur “p”
Autrement dit, TF-IDF est un outil exploratoire, pas un test d’hypothèse. Il sert à enrichir l’analyse (par exemple, identifier des mots saillants, préparer un clustering, alimenter une analyse SEO), mais il ne permet pas de conclure statistiquement à des différences significatives.
2. Présentation des trois documents
Pour illustrer le fonctionnement du calcul TF-IDF, voici un corpus composé de trois documents fictifs.
Document 1
« Bienvenue à Bordeaux, capitale mondiale du vin. Bordeaux vous invite à découvrir ses vignobles renommés, où le vin est une véritable passion. À Bordeaux, chaque visite est l’occasion de rencontrer des vignerons et de déguster des vins d’exception. Les vignobles de Bordeaux s’étendent à perte de vue, offrant des paysages magnifiques entre châteaux et rangs de vignes. Bordeaux, c’est aussi l’art de vivre, où le vin accompagne la gastronomie et fait rayonner la ville à l’international. Que vous soyez amateur de vin ou curieux, Bordeaux et ses vignobles vous attendent pour une expérience unique autour du vin. »
Document 2
« Découvrez Chamonix, au cœur des Alpes, destination emblématique de la montagne. Chamonix séduit les passionnés de ski, de randonnée et d’aventure en montagne. En hiver, Chamonix offre des pistes de ski variées, adaptées à tous les niveaux, avec des panoramas exceptionnels sur le Mont-Blanc. À Chamonix, la montagne est omniprésente : que ce soit pour le ski, l’escalade ou simplement admirer les sommets, Chamonix est un véritable paradis pour les amoureux de montagne. Entre sensations fortes et paysages à couper le souffle, Chamonix promet un séjour inoubliable au cœur de la montagne. »
Document 3
« Lyon, capitale de la gastronomie, vous ouvre ses portes pour une expérience culinaire incomparable. À Lyon, les restaurants traditionnels, appelés bouchons, mettent à l’honneur la gastronomie lyonnaise et ses spécialités. Dans chaque restaurant, la gastronomie est une célébration du goût, entre quenelles, andouillettes et tarte à la praline. Lyon est une ville où la gastronomie est partout : sur les marchés, dans les restaurants étoilés ou dans les petites adresses familiales. Venez à Lyon pour goûter à la gastronomie, rencontrer des chefs passionnés et découvrir pourquoi Lyon est devenue la référence mondiale de la gastronomie. »
3. Construire la matrice
Avant de calculer les matrices de fréquences, TF, IDF et TF-IDF, le corpus a été à “nettoyé”. Cette étape consiste à supprimer les stopwords, c’est-à-dire les mots très fréquents, qui n’apportent généralement pas de valeur thématique. En parallèle, nous avons également supprimé toute la ponctuation (points, virgules, deux-points, apostrophes,…) afin d’éviter que des signes isolés soient comptés comme des termes.
Voici le tableau affichant plusieurs niveaux d’analyse pour chaque mot.
- la fréquence brute (combien de fois il apparaît dans chaque document (Doc1_freq…)
- la fréquence relative (TF), calculée en divisant la fréquence par le nombre total de mots du document (Doc1_TF…)
- le nombre de documents contenant le terme (DF)
- et le score d’Inverse Document Frequency (IDF), qui donne plus de poids aux termes rares à l’échelle du corpus
- Enfin le score final : TF * IDF (Doc1_TFIDF…)
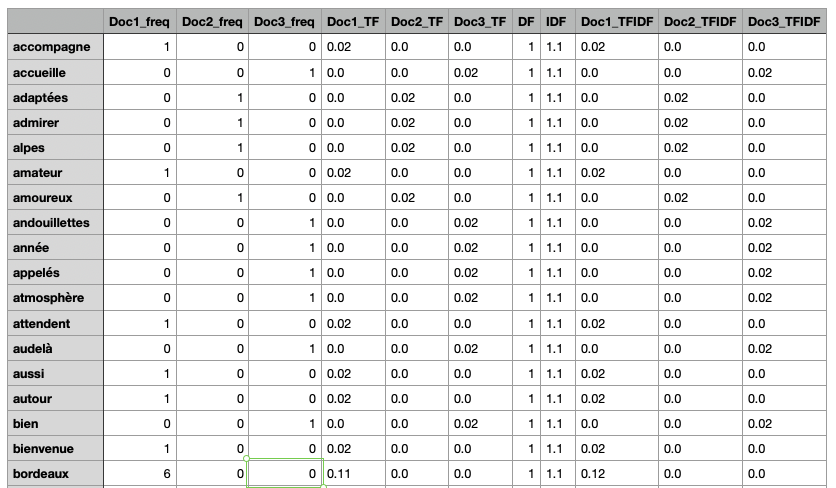
La matrice complète ICI : Matrice_TF-IDF_sans_stopwords_ni_ponctuation.
Ce tableau permet de repérer les mots qui caractérisent chaque document : ils apparaissent fréquemment dans un texte mais rarement dans les autres, et leur score TF-IDF les met ainsi en avant comme des marqueurs lexicaux distinctifs.
4. Pourquoi calcule-t-on l’IDF avec un logarithme ?
La formule de l’IDF est :
où :
- = document
- = nombre de documents contenant “t”
- D = le corpus (ensemble des documents)
4.1 À quoi sert le log ici ?
L’IDF calcule l’importance d’un terme “t” en fonction de sa rareté dans le corpus “D”. Le logarithme permet d’éviter que les mots trop rares écrasent l’analyse, en compressant les écarts et en assurant un poids discriminant mais maîtrisé.
On utilise le logarithme dans l’IDF pour modérer l’impact des mots rares, éviter des scores extrêmes et obtenir une pondération plus comparable.
4.2 Exemple sans le logarithme
- D =1 000 documents
- terme t1 apparaît dans 1 document → IDFsans log(t1) = 1000/1 = 1000
- terme t2 apparaît dans 10 documents → IDFsans log(t2) =1 000/10 = 100
- terme t3 apparaît dans 100 documents → IDFsans log(t3) = 1000/100 =10
Dans cet exemple le terme “t1” a un poids 100 fois plus grand que “t3”, ce qui écrase toute nuance. Un hapax (terme très rare) dominerait artificiellement les résultats.
3.4 Exemple avec le logarithme
- IDF(t1) = log(1000/1) = 6.9
- IDF(t2) = log(1000/10) = 4.6
- IDF(t3)=log(1000/100) = 2.3
Le logarithme réduit l’écart. Le terme rare “t1” reste plus important, mais seulement 3 fois plus que le terme “t3″, au lieu de 100 fois.
Conclusion
L’analyse des homepages des sites de destinations touristiques à l’aide du calcul TF-IDF permet d’aller bien au-delà d’un simple relevé des mots les plus fréquents. En combinant fréquence locale et rareté globale, cette approche met en lumière les termes réellement distinctifs de chaque document, offrant ainsi une lecture plus fine et plus qualitative des contenus.
L’application de TF*IDF peut être également un choix stratégique dans le cadre du NLP.