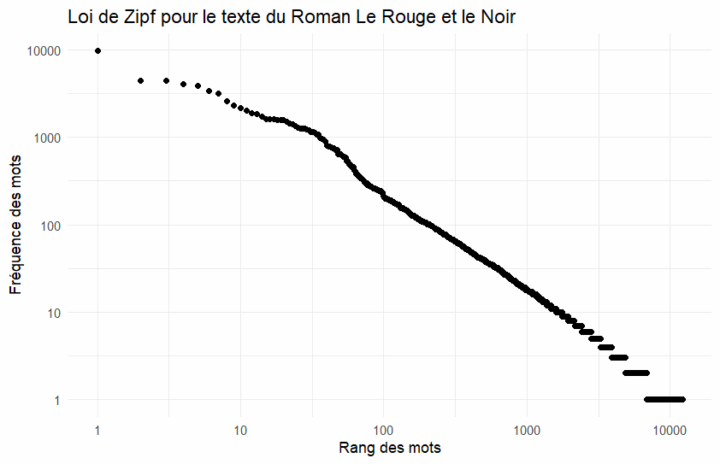
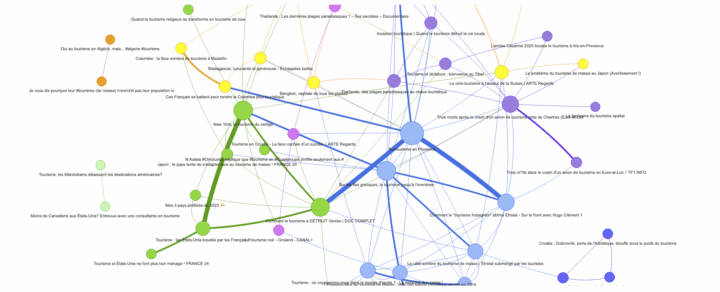
Le prétraitement (preprocessing) est une étape incontournable avant de lancer vos tests et analyses. Prétraitement = normalisation du texte ! Plusieurs étapes de normalisation sont possibles (liste non exhaustive qui dépend de vos objectifs) : Supprimer les stopwords Normaliser les accents du texte (cette normalisation permet de supprimer des doublons liés à des fautes d’orthographe par...