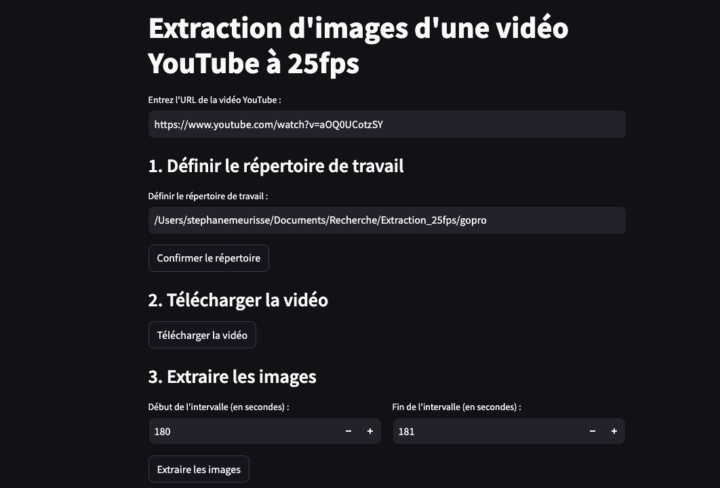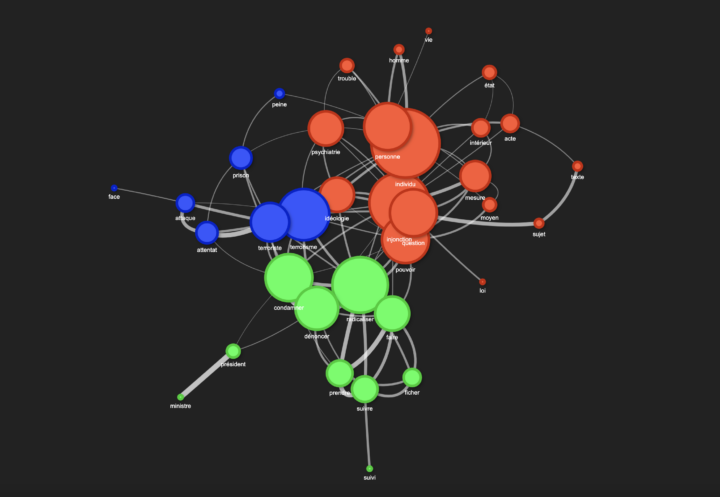
Parmi les nombreuses approches utilisées dans le traitement du langage naturel (NLP – Natural Language Processing), la mesure de la similarité cosinus permet de comparer des mots en fonction de leur proximité dans un espace vectoriel. Le script ci-dessous a été conçu avec un corpus test, issu d’articles récupérés via Europresse et formaté pour être compatible avec le logiciel...