
1. Bref historique de la mémoire externalisée
L’être humain a toujours su étendre sa mémoire au-delà du cerveau. De l’écriture sur des supports durables aux bibliothèques de l’antiquité, il a multiplié les techniques permettant d’inscrire, conserver et transmettre des savoirs hors de la mémoire individuelle. On peut citer une scène du film “Le Nom de la rose“, réalisé par Jean-Jacques Annaud (1986), où l’on voit des moines appliqués à recopier des manuscrits à la main dans la bibliothèque.
Un basculement s’accélère au début des années 2000 lorsque les moteurs de recherche rendent l’accès à l’information quasi immédiat. Le concept de mémoire transactive, proposée par Daniel Wegner dans les années 1980, aide à comprendre ce déplacement: nous répartissons spontanément le travail de mémoire au sein d’un groupe en sachant « qui sait quoi ». Avec Internet, ce “partenaire” de mémoire tend à devenir non plus un proche, mais un dispositif technique, et notre mémoire se reconfigure en conséquence.
L’article publié dans la revue Science, date de 2011“B. Sparrow et al, Google Effects on Memory: Cognitive Consequences of Having Information at Our Fingertips, Science 333, p.776 (2011)”.
À l’heure des LLM (OpenAI, GPT-3.5 apparu début 2022), cette dématérialisation de la mémoire est de nouveau discutée, et même approfondie, notamment par Anne Alombert (MCF, philosophie contemporaine, Paris 8). Elle insiste sur le fait que l’IA générative fonctionne comme un support de mémoire, mais aussi sur un point décisif : si l’activité d’écriture est elle aussi déléguée aux LLM, cela contribuerait à modifier les processus de mémorisation et l’activité cognitive.
2. Définition de l’effet Google
L’effet Google, souvent qualifié par le terme d’amnésie numérique, désigne la propension du cerveau humain à oublier une information dès lors qu’il sait qu’elle est disponible et facilement accessible via un outil technologique (Google).
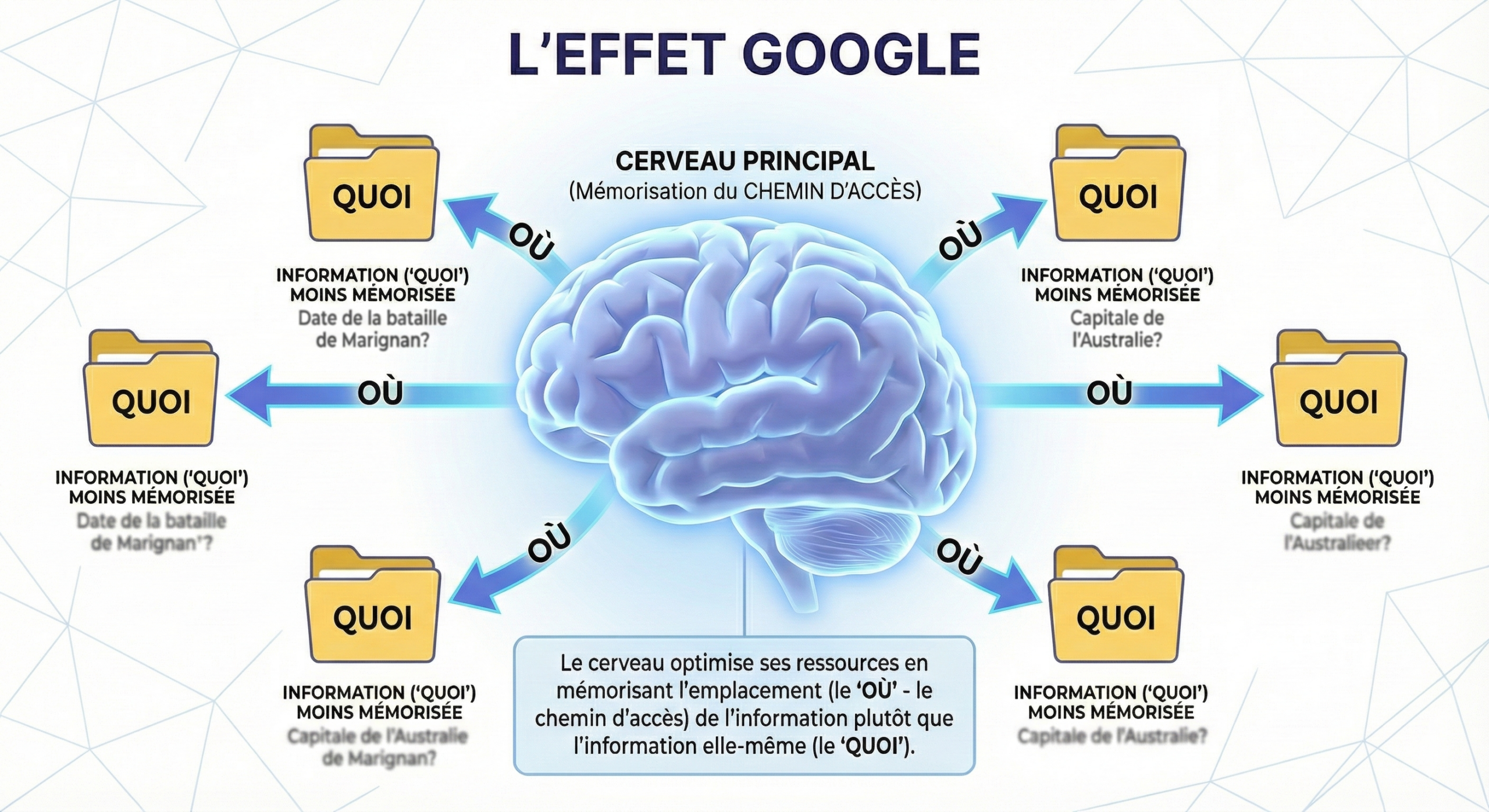
Au lieu de consacrer des ressources neuronales au stockage de données, le cerveau optimise ses capacités en ne mémorisant que le chemin d’accès à ces données.
3. Le protocole de l’étude
L’idée générale : Lorsque les personnes s’attendent à pouvoir retrouver une information facilement, elles ont tendance à moins bien mémoriser le contenu de cette information et à privilégier la mémoire de l’accès.
3.1 Expérience n°1
Les chercheurs font répondre les participants à deux blocs de questions (faciles puis difficiles). Après chaque bloc, ils affichent des mots écrits en rouge ou en bleu (test de Stroop) et demandent de dire uniquement la couleur le plus vite possible, sans lire le mot.
Parmi ces mots figurent des termes liés à Internet (Google, Yahoo…) et des termes neutres.
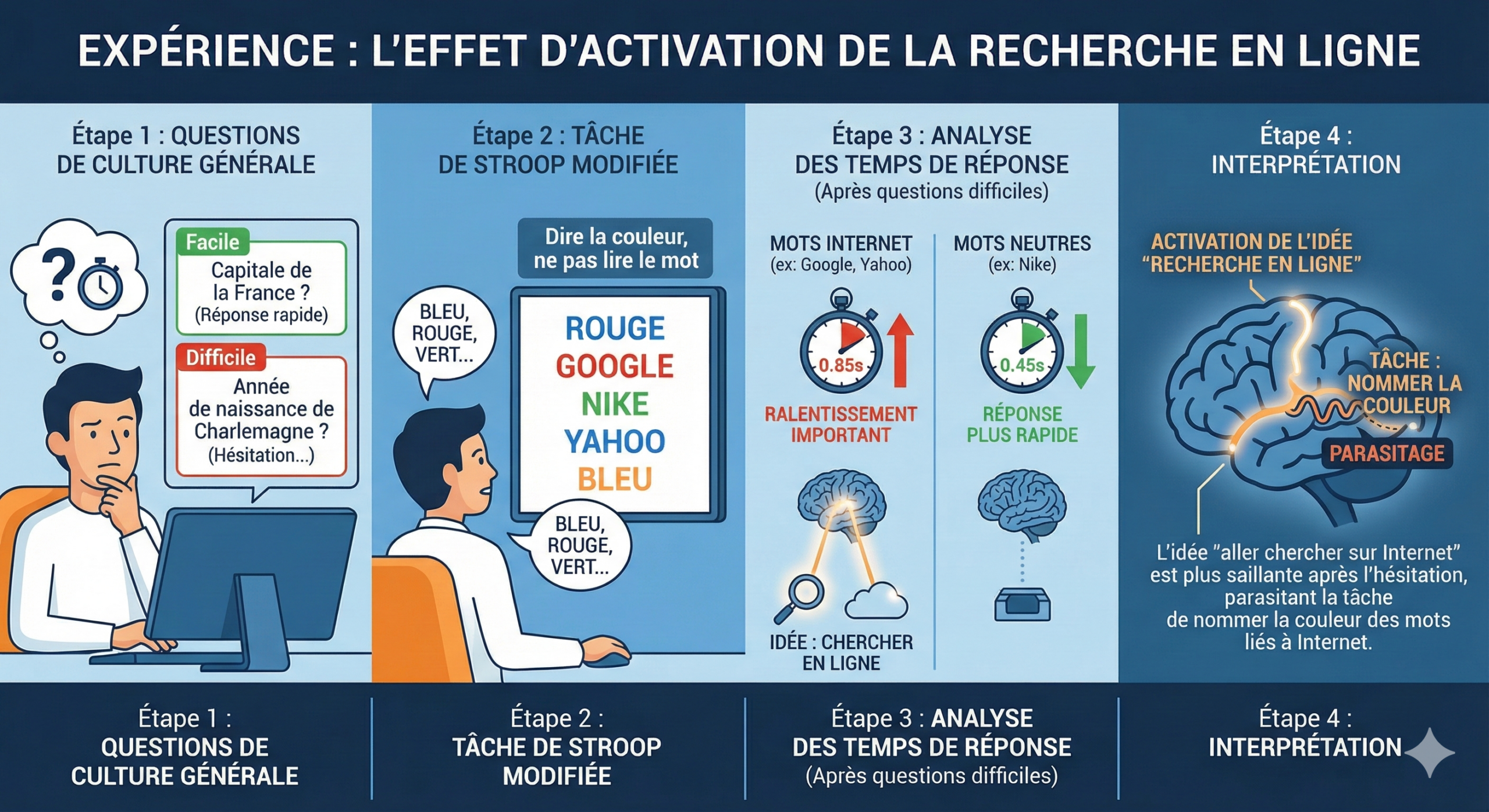
Si, après le bloc de questions difficiles, les mots liés à Internet (comme “Google” ou “Yahoo”) font davantage ralentir la réponse “rouge/bleu/vert/…” que des mots neutres, les chercheurs interprètent ce surcroît de lenteur comme un indice : dans ce contexte de difficulté, l’idée de chercher une information en ligne capte davantage l’attention.
3.2 Expérience n°2
On fait taper à l’écran 40 énoncés (des informations qu’on pourrait facilement aller chercher en ligne).
Ensuite, à un groupe on dit “ce que vous tapez sera sauvegardé”, à un autre “ce que vous tapez sera effacé”.
Puis on “teste la mémoire” des participants en demandant d’écrire autant d’énoncé que possible.
Ainsi, quand les participants croient que c’est sauvegardé, ils retiennent moins bien le contenu, parce qu’ils s’appuient davantage sur l’idée qu’ils pourront retrouver les informations.
3.3 Expérience n°3
Dans une troisième expérience, les chercheurs reprennent le principe de la deuxième, mais ils introduisent explicitement la question du “où”. Au fil des essais, ils associent les mêmes types d’énoncés à trois messages de statut.
Après chaque phrase tapée, l’ordinateur affiche l’un des trois statuts suivants : soit il efface l’information, soit il la sauvegarde sans préciser l’emplacement, soit il la sauvegarde dans le dossier X.
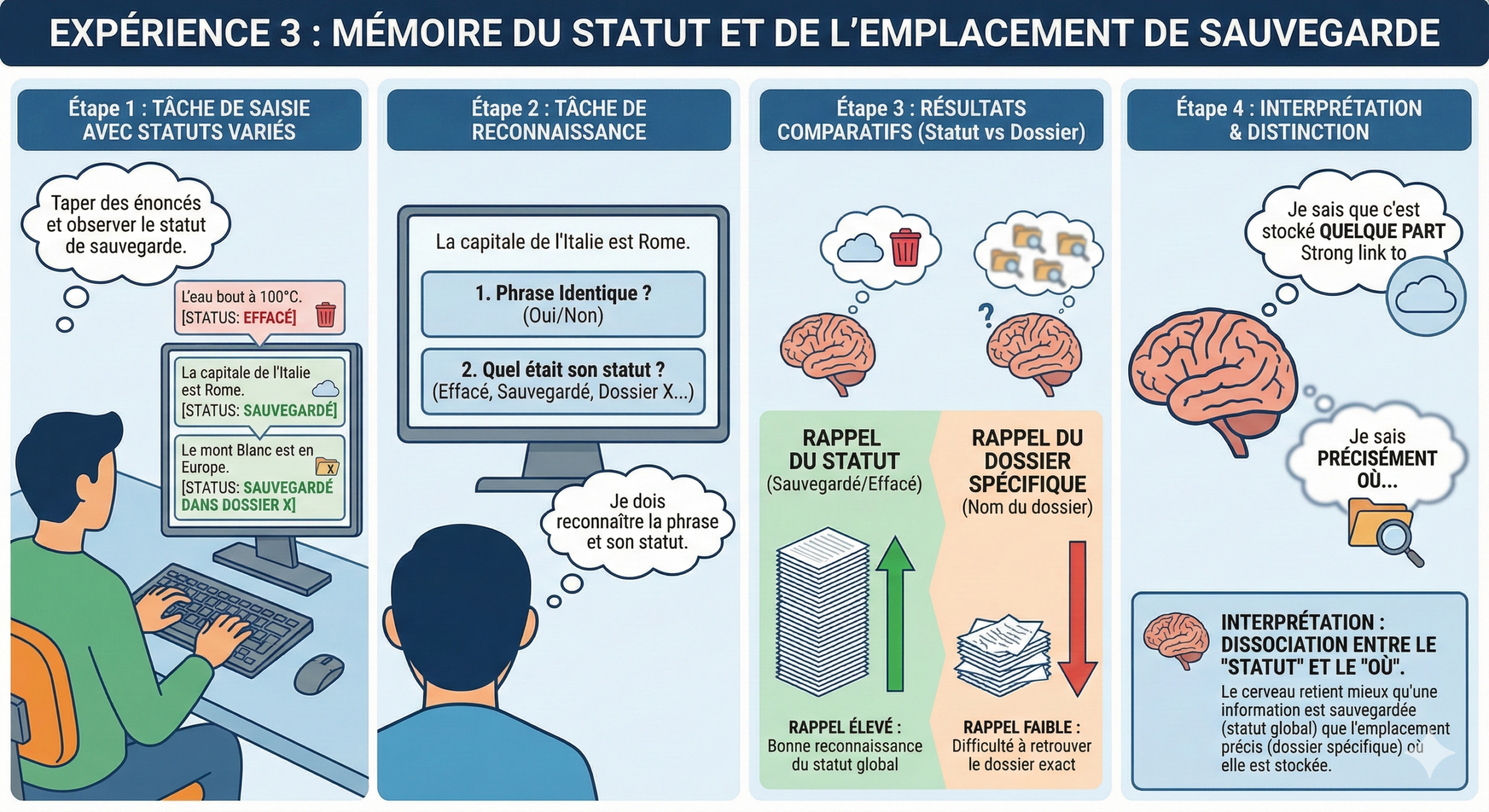
Ensuite, on ne demande pas un simple rappel libre : on fait une tâche de reconnaissance. Les chercheurs remontrent les phrases, puis les participants doivent dire si c’est la même phrase ou une phrase modifiée, si l’ordinateur l’a sauvegardée ou effacée, et, si l’ordinateur l’a sauvegardée, dans quel dossier il l’a enregistrée.
Ici, la nuance est la suivante : les participants peuvent relativement bien retenir le “statut” (sauvegardé/effacé), mais ils ne sont pas forcément très bons pour retenir le nom exact du dossier.
3.4 Expérience n°4
Dans cette variante, les chercheurs demandent aux participants de retenir non seulement les énoncés, mais aussi l’emplacement informatique (le nom du dossier) où ils stockent chaque information.
On réalise auprès des participants deux tests, l’un après l’autre. D’abord un rappel libre des faits/informations eux-mêmes (écrire tout ce dont on se souvient, sans aide). Ensuite, les chercheurs testent le rappel de l’emplacement: ils donnent un indice qui rappelle de quelle information ou de quel énoncé il s’agit, puis ils demandent dans quel dossier les participants l’ont rangé.
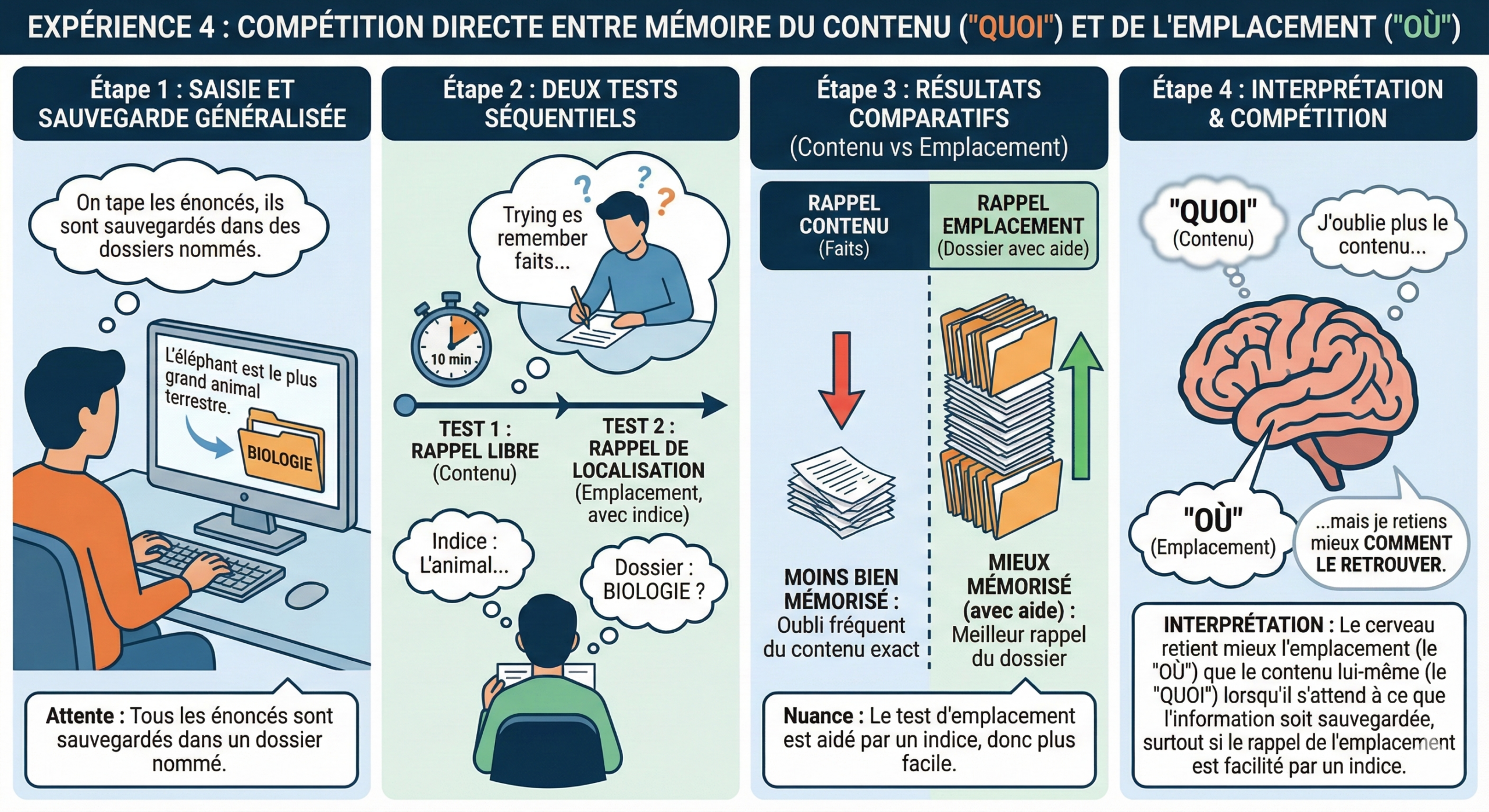
Dans ce dispositif, les participants retrouvent plus souvent le dossier que le fait. ll faut garder une nuance méthodologique: les chercheurs aident le rappel du dossier (“où”) en fournissant un indice ; ce rappel devient donc plus facile que le rappel libre du contenu, ce qui explique en partie pourquoi l’emplacement peut paraître “mieux mémorisé” dans cette expérience.
4. Le test de Stroop
Un test de Stroop est une tâche en psychologie cognitive qui sert à mesurer l’attention et le contrôle inhibiteur, c’est-à-dire la capacité à résister à une réponse automatique. Les auteurs utilisent le test de Stroop uniquement dans l’expérience n°1, sous une forme modifiée : les participants doivent nommer la couleur (rouge/bleu) de mots “informatiques” ou “non informatiques” afin d’évaluer si les termes liés à l’ordinateur deviennent plus saillants.
Dans sa version la plus connue du test, on montre des mots qui sont des noms de couleurs. Le mot est écrit dans une couleur qui correspond ou non au mot. Par exemple, le mot « ROUGE » peut être écrit en bleu. La consigne est de dire la couleur de l’encre (bleu), et non de lire le mot (rouge). Quand il y a conflit (mot et encre ne correspondent pas), les gens mettent plus de temps et font plus d’erreurs, parce que lire le mot est une réponse très automatique qu’il faut inhiber.
5. Des conclusions à relativiser
Une piste pour relativiser l’effet Google réside dans la nature même des contenus consultés en ligne.
L’étude de 2011 reposait sur du texte. Or, le web est un univers multimédia mêlant images, vidéos et sons… et textes.
![]()
La psychologie cognitive, notamment à travers la théorie du double codage d’Allan Paivio (1971), démontre que l’association d’une information textuelle à un support visuel ou auditif facilite grandement l’ancrage mémoriel.
Conclusion
Les implications de cet effet redéfinissent notre rapport au savoir et à l’apprentissage. En externalisant le stockage des informations, le cerveau libère une charge cognitive, ce qui pourrait en théorie permettre de se concentrer sur d’autres tâches.
Cependant, cette application présente un revers important : l’intégration profonde des connaissances.
Pour qu’une pensée complexe puisse émerger, le cerveau a besoin de manipuler des informations déjà stockées dans sa structure interne.