Ce script Python permet d’effectuer une recherche de vidéos sur YouTube à partir d’un mot-clé, tout en appliquant divers filtres tels que la langue, la région, l’année de publication, ainsi que le nombre de vues, de likes et de commentaires.
Les métadonnées des vidéos récupérées sont ensuite exportées au format Excel.
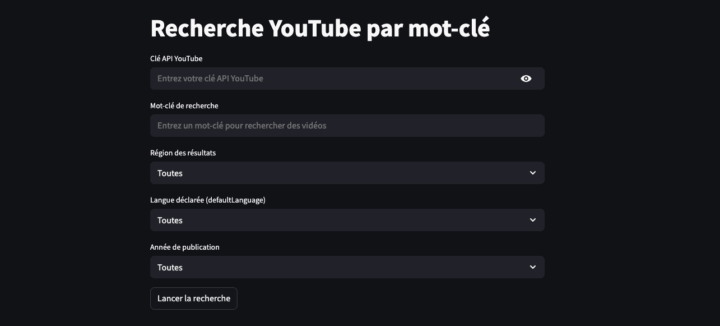
L’interface utilise Streamlit, accessible via le navigateur.
1. Clé API YouTube
Pour interroger l’API YouTube, une clé API est obligatoire. Elle doit être générée via Google Cloud en activant le service YouTube Data API v3.
Je ne vais pas rentrer dans le détail de la création de cette clé API. Si vous avez besoin d’aide n’hésitez pas à écrire un commentaire en bas de page.
Par défaut, chaque projet Google Cloud disposant de l’API YouTube Data activée bénéficie de 10 000 unités par jour. Ce quota est généralement suffisant pour la majorité des applications.
L’API YouTube Data utilise un système de quota pour réguler l’usage du service, éviter les abus et garantir un accès équitable à tous les développeurs. Chaque requête, y compris les requêtes incorrectes ou échouées, consomme une/des unité(s) de quota.

L’API YouTube Data utilise un système de quota pour réguler l’usage du service. Chaque requête, y compris les requêtes incorrectes ou échouées, consomme une/des unité(s) de quota.
En raison des limitations imposées par l’API YouTube Data, il est difficile d’extraire l’ensemble des résultats correspondant à une requête donnée.
En effet, même si le quota quotidien autorise l’envoi d’un nombre de requêtes (jusqu’à 10 000 unités par jour), l’API ne permet généralement de récupérer qu’un nombre limité de résultats par requête, notamment dans le cas de la recherche de vidéos, souvent restreint à environ 500 éléments.
Pour contourner cette contrainte, une solution consisterait à planifier une tâche récurrente (tache de type “cron”) permettant d’automatiser la collecte de données journalière. Cela fera l’objet d’un prochain article.
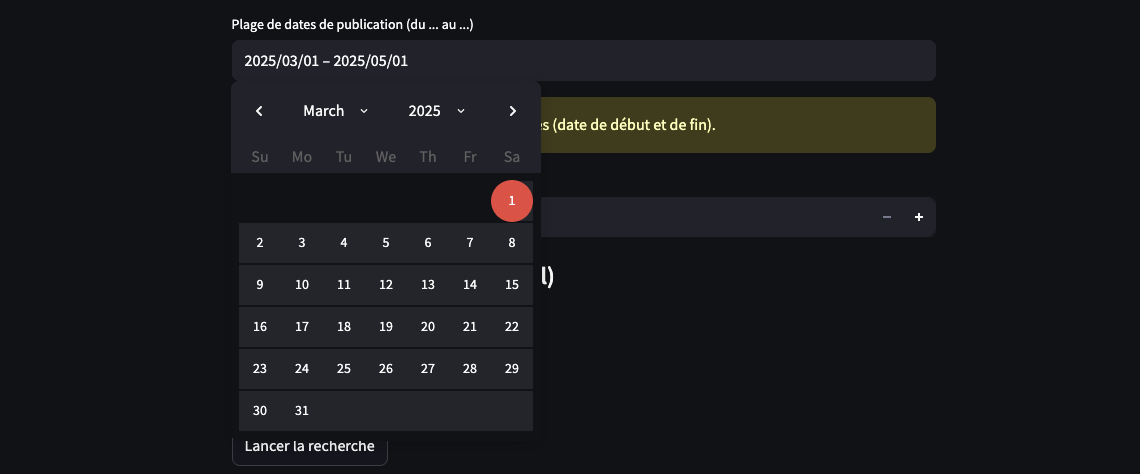
Initialement, le script était conçu pour effectuer des recherches par année.
Toutefois, face aux limitations imposées par le quota et le nombre restreint de résultats retournés, j’ai ajouté la possibilité de spécifier une plage de dates plus précise afin d’améliorer la pertinence et la couverture des données récupérées.
2. Interface Streamlit
L’utilisateur est invité à saisir :
- sa clé API YouTube
- un mot-clé de recherche
- une région (France, États-Unis ou toutes)
- une langue déclarée (
defaultLanguage) - une plage de dates de publication
De plus, un filtre est disponible pour extraire les vidéos en fonction du nombre de vues, de likes ou de commentaires. Ce filtre peut être croisé avec l’année de publication des vidéos.
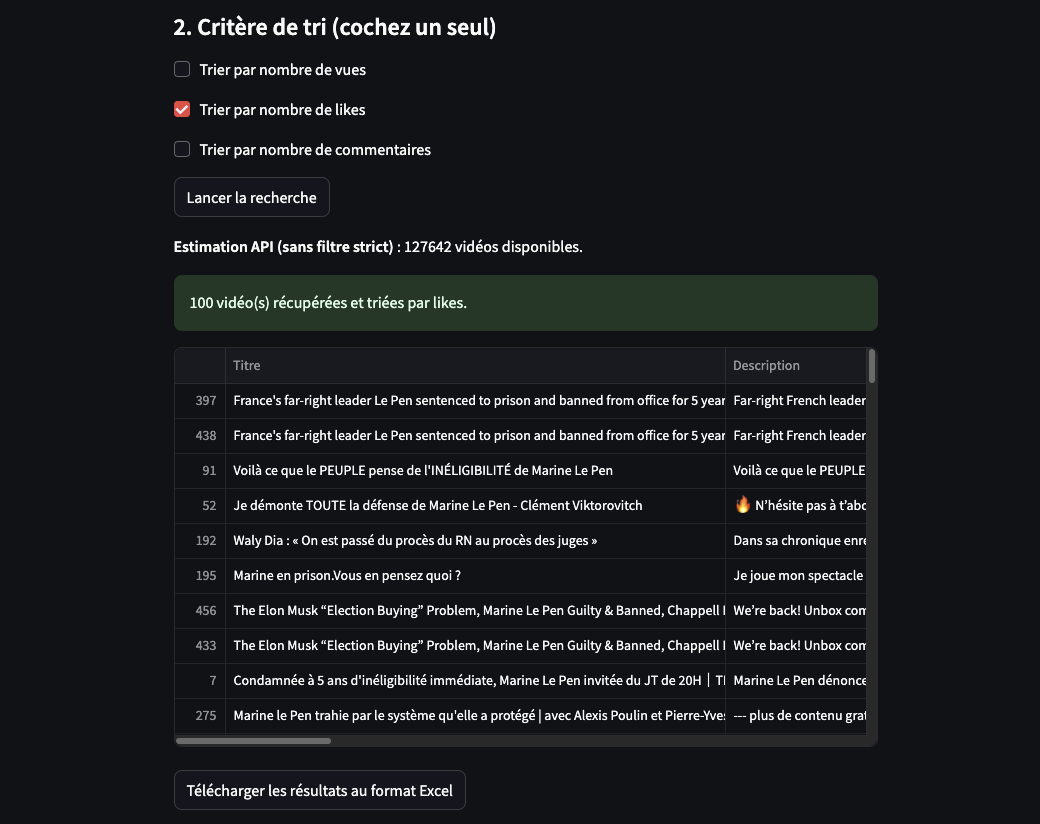
La dataframe affichée dans Streamlit montre les 10 premiers résultats, mais si vous avez sélectionné 100 résultats, l’ensemble des données sera disponible dans le fichier Excel (.xlsx).
3. Récupération des métadonnées
Le script récupère les “métadonnées” suivantes pour chaque vidéo :
- Titre
- Description de la vidéo
- Date de publication
- URL de la vidéo (permet de consulter facilement la vidéo par copier/coller)
- ID et titre de la chaîne
- Catégorie
- Nombre de vues, de likes, de commentaires
- L’Indicateur des commentaires désactivés (marche pas…)
- Langue déclarée (
defaultLanguage) - Langue audio (
defaultAudioLanguage).
Code source
Avant de lancer le script, il est nécessaire d’installer les bibliothèques suivantes :
pip install streamlit pandas google-api-python-client XlsxWriter
streamlit: pour l’interface webpandas: pour manipuler les données (DataFrame)google-api-python-client: l’API YouTube Data v3XlsxWriter: les résultats au format Excel.xlsx
# extraction des infos Youtube par mot clé : titre, description, chaine, nombre de vues, likes, commentaires...
# pip install streamlit pandas google-api-python-client XlsxWriter
# python -m streamlit run main.py
import streamlit as st
import pandas as pd
import io
from datetime import datetime, date
from googleapiclient.discovery import build
# Fonction de comptage estimation API
def compter_videos_youtube(cle_api: str, mot_cle: str, region: str = None, published_after: str = None, published_before: str = None) -> int:
youtube = build('youtube', 'v3', developerKey=cle_api)
params = {
'q': mot_cle,
'part': 'snippet',
'type': 'video',
'maxResults': 1
}
if region:
params['regionCode'] = region
if published_after:
params['publishedAfter'] = published_after
if published_before:
params['publishedBefore'] = published_before
requete = youtube.search().list(**params)
reponse = requete.execute()
return reponse.get('pageInfo', {}).get('totalResults', 0)
# Fonction principale de récupération
def rechercher_videos_youtube(
cle_api: str,
mot_cle: str,
region: str = None,
langue: str = None,
published_after: str = None,
published_before: str = None,
max_videos: int = 100,
critere_tri: str = "Vues"
) -> pd.DataFrame:
"""
Recherche des vidéos YouTube avec tri, plage de dates stricte et filtrage post-API.
"""
youtube = build('youtube', 'v3', developerKey=cle_api)
# Préparer la correspondance des catégories par région
mapping_categories = {}
if region:
cats = youtube.videoCategories().list(part='snippet', regionCode=region).execute()
for cat in cats.get('items', []):
mapping_categories[cat['id']] = cat['snippet'].get('title', '')
page_token = None
items = []
while True:
# Paramètres de recherche
params = {
'q': mot_cle,
'part': 'snippet',
'type': 'video',
'maxResults': 50,
'pageToken': page_token,
'order': 'date' # Important : trie les résultats par date de publication
}
if region:
params['regionCode'] = region
if published_after:
params['publishedAfter'] = published_after
if published_before:
params['publishedBefore'] = published_before
# Appel à l’API YouTube
search_resp = youtube.search().list(**params).execute()
# Sécurité sur les videoId
video_ids = []
for item in search_resp.get('items', []):
if item.get("id", {}).get("videoId"):
video_ids.append(item["id"]["videoId"])
if not video_ids:
page_token = search_resp.get('nextPageToken')
if not page_token:
break
else:
continue
# Récupération des détails des vidéos
vids_resp = youtube.videos().list(
part='snippet,statistics',
id=','.join(video_ids)
).execute()
for video in vids_resp.get('items', []):
snippet = video['snippet']
stats = video.get('statistics', {})
vid = video['id']
titre = snippet.get('title', '')
description = snippet.get('description', '')
date_iso = snippet.get('publishedAt', '')
try:
date_fmt = datetime.fromisoformat(date_iso.replace('Z', '+00:00')).strftime('%Y-%m-%d %H:%M:%S')
except Exception:
date_fmt = date_iso
channel_id = snippet.get('channelId', '')
channel_title = snippet.get('channelTitle', '')
cat_id = snippet.get('categoryId', '')
cat_label = mapping_categories.get(cat_id, '')
view_count = int(stats.get('viewCount', 0))
like_count = int(stats.get('likeCount', 0))
comment_count = int(stats.get('commentCount', 0))
comment_disabled = 'commentCount' not in stats
lang_def = snippet.get('defaultLanguage', None)
audio_lang = snippet.get('defaultAudioLanguage', None)
url = f"https://www.youtube.com/watch?v={vid}"
items.append({
'Titre': titre,
'Description': description,
'Date de publication': date_fmt,
'Date ISO': date_iso,
'URL': url,
'Channel ID': channel_id,
'Channel titre': channel_title,
'Catégorie': cat_label,
'Vues': view_count,
'Likes': like_count,
'Commentaires': comment_count,
'Commentaire désactivés': comment_disabled,
'Langue par défaut': lang_def,
'Langue audio par défaut': audio_lang
})
page_token = search_resp.get('nextPageToken')
if not page_token or len(items) >= 500:
break
# Création du DataFrame
df = pd.DataFrame(items)
# Filtrage par langue
if langue:
df = df[df['Langue par défaut'] == langue]
# Filtrage strict par date ISO (après récupération)
if published_after and published_before:
df['Date ISO'] = pd.to_datetime(df['Date ISO'], errors='coerce')
df = df[
(df['Date ISO'] >= pd.to_datetime(published_after)) &
(df['Date ISO'] <= pd.to_datetime(published_before))
]
# Tri par critère sélectionné
if critere_tri in df.columns:
df = df.sort_values(by=critere_tri, ascending=False)
# Limitation au nombre demandé
if len(df) > max_videos:
df = df.iloc[:max_videos]
return df
# --- Interface Streamlit ---
st.title("Exploration de vidéos YouTube par mot-clé")
st.markdown("#### 1. Paramètres de base")
cle_api_input = st.text_input("Clé API YouTube", placeholder="Entrez votre clé API", type="password")
mot_cle_input = st.text_input("Mot-clé de recherche", placeholder="Ex : ukraine, Picasso, IA...")
region = st.selectbox("Région des résultats", ["Toutes", "France", "États-Unis"], index=0)
region_code = {'France': 'FR', 'États-Unis': 'US'}.get(region)
langue_input = st.selectbox("Langue déclarée", ["Toutes", "fr", "en"], index=0)
langue_code = langue_input if langue_input in ["fr", "en"] else None
plage_dates = st.date_input(
"Plage de dates de publication (du ... au ...)",
[date.today().replace(month=1, day=1), date.today()]
)
# Sécurité : vérifier que deux dates sont bien sélectionnées
if isinstance(plage_dates, list) and len(plage_dates) == 2:
published_after = plage_dates[0].strftime('%Y-%m-%dT00:00:00Z')
published_before = plage_dates[1].strftime('%Y-%m-%dT23:59:59Z')
else:
published_after = None
published_before = None
st.warning("Veuillez sélectionner une plage de deux dates (date de début et de fin).")
max_videos = st.number_input("Nombre de vidéos à extraire (max effectif : 500)", min_value=1, value=100, step=10)
st.markdown("#### 2. Critère de tri (cochez un seul)")
tri_vues = st.checkbox("Trier par nombre de vues")
tri_likes = st.checkbox("Trier par nombre de likes")
tri_commentaires = st.checkbox("Trier par nombre de commentaires")
criteres_coches = [tri_vues, tri_likes, tri_commentaires]
nb_criteres = sum(criteres_coches)
if st.button("Lancer la recherche"):
if not cle_api_input or not mot_cle_input:
st.error("Veuillez renseigner la clé API et le mot-clé.")
elif nb_criteres > 1:
st.error("Veuillez cocher un seul critère de tri à la fois.")
else:
critere = "Vues"
if tri_likes:
critere = "Likes"
elif tri_commentaires:
critere = "Commentaires"
with st.spinner("Recherche des vidéos en cours..."):
pass # estimation supprimée volontairement
with st.spinner(f"Recherche des vidéos triées par {critere.lower()}..."):
try:
df_resultats = rechercher_videos_youtube(
cle_api=cle_api_input,
mot_cle=mot_cle_input,
region=region_code,
langue=langue_code,
published_after=published_after,
published_before=published_before,
max_videos=max_videos,
critere_tri=critere
)
st.success(f"{len(df_resultats)} vidéo(s) récupérées et triées par {critere.lower()}.")
st.dataframe(df_resultats)
buffer = io.BytesIO()
with pd.ExcelWriter(buffer, engine='xlsxwriter') as writer:
df_resultats.to_excel(writer, index=False, sheet_name='Résultats')
buffer.seek(0)
nom_fichier = f"youtube_{mot_cle_input}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx"
st.download_button(
label="Télécharger les résultats au format Excel",
data=buffer,
file_name=nom_fichier,
mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
)
except Exception as e:
st.error(f"Erreur lors de la récupération des vidéos : {e}")