
Il ne faut pas s’attendre à un miracle !
Penser qu’un LLM est en capacité de réaliser une analyse fine d’une CHD, c’est un peu comme croire à son horoscope.
Ce script s’inscrit dans une démarche expérimentale et constitue un exercice purement technique.
Il convient de rappeler également qu’un modèle de langage (LLM) n’a aucune capacité cognitive : il ne comprend rien, ne pense pas, n’a pas d’intentionnalité ni de conscience du contexte (c’est une IA faible vs IA forte).
Il repose exclusivement sur des calculs statistiques, des mécanismes de vectorisation de tokens et de similarité dans des espaces d’embedding.
À elle seule, cette petite expérimentation démontre qu’un LLM, même si dans certaines configurations (le modèle o4mini d’OpenAI, par exemple, affiche « raisonnement » lorsqu’il prépare sa réponse à un prompt), ne fait qu’illusion et manque de consistance dans ses réponses.
Ce prétendu « raisonnement » ne renvoie en réalité qu’à sa capacité d’attention, c’est-à-dire à son aptitude à remonter dans les échanges précédents pour en extraire des éléments. Rien de plus !
1. Résultats
Autant le dire immédiatement : le script est fonctionnel. L’analyse des segments de texte, croisée avec un fichier CSV contenant la fréquence des termes par classe et leur chi2 (et d’autres paramètres non exploités ici), fonctionne correctement.
Mais allons directement à la conclusion : le système est fondamentalement limité par la longueur maximale de la réponse (le nombre de tokens autorisés).
Surtout, la nature même de la réponse produite par le modèle s’apparente à une forme de paraphrase. Ce constat rejoint ce qui est dit en préambule : un LLM n’a aucune capacité de raisonnement.
On peut parler ici de réponse paraphrasée, au sens où un LLM ne fait qu’une projection dans un espace d’embeddings pour prédire le mot suivant le plus probable. Il ne construit pas d’analyse, il ne formule pas d’hypothèses, il reformule avec une cohérence apparente, guidée par des probabilités.
2. Objectifs
L’objectif de ce script est de croiser les résultats d’une classification hiérarchique descendante (CHD) réalisée avec rainette avec d’une part, la répartition des segments de texte des différentes classes, et d’autre part, l’extraction des mots discriminants selon des mesures de fréquence brute et de chi2.
Une fois cette base statistique constituée, il s’agit d’y « greffer » un LLM pour tester la manière dont il analyserait chaque classe.
3. La méthode
Je tiens à faire un “disclaimer” concernant les corpus utilisés pour élaborer ce script. Le premier provient de la transcription automatique d’une vidéo via Whisper, sans aucun contrôle a posteriori ni nettoyage manuel : ni corrections, ni ponctuation révisée…
Le second corpus est constitué d’articles de presse issus d’Europresse, intégrés tels quels, là encore sans traitement linguistique approfondi.
Mon objectif ici est strictement technique : il s’agit de tester un script mais pas de proposer une analyse sémantique autour du surtourisme.
Vous trouverez donc, sur certaines captures d’écran, des erreurs de grammaire, ou des formulations approximatives. Ces défauts biaisent évidemment l’interprétation, mais ce n’est pas l’objet de cet article.
Le script repose sur une classification hiérarchique descendante (CHD) réalisée avec le package rainette en R.
Toutefois, cette version du script reste expérimentale, en particulier sur le plan de la lemmatisation. Il est disponible dans son intégralité ici. Vous aurez besoin de ce script pour produire le fichier csv.
La lemmatisation repose dans ce script sur l’outil UDPipe, (j’avais cru trouver mon bonheur avec un dictionnaire de lemmes en Français – Lefff… mais j’obtiens une erreur “403 – Forbidden” quand je veux le télécharger) dont les performances sont limitées.
Une amélioration future consistera à tester un “pipeline” entièrement basé sur des fichiers produit à l’aide du logiciel IRaMuTeQ.
Pour activer l’analyse avec un modèle de langage, il est nécessaire d’utiliser LM Studio, un logiciel permettant de faire tourner localement un LLM, sans connexion aux serveurs d’Hugging Face.
Pour ce projet, j’ai utilisé le modèle Nous-Hermes 2 – Mistral 7B (on commence “petit”) un modèle comptant environ 7 milliards de paramètres, fondé sur l’architecture Mistral.
4. Le fonctionnement du script
4.1 Paramètres généraux du LLM local
LMSTUDIO_API_URL = "http://localhost:1234/v1/chat/completions" LMSTUDIO_MODEL = "local-model" MAX_TOKENS_PROMPT = 3500 MAX_TOKENS_RESPONSE = 5000
Ce bloc définit l’URL de l’API de LM Studio (local), ainsi que les limites en nombre de tokens pour le prompt et la réponse.
Le modèle doit être directement téléchargé à partir de LM Studio.
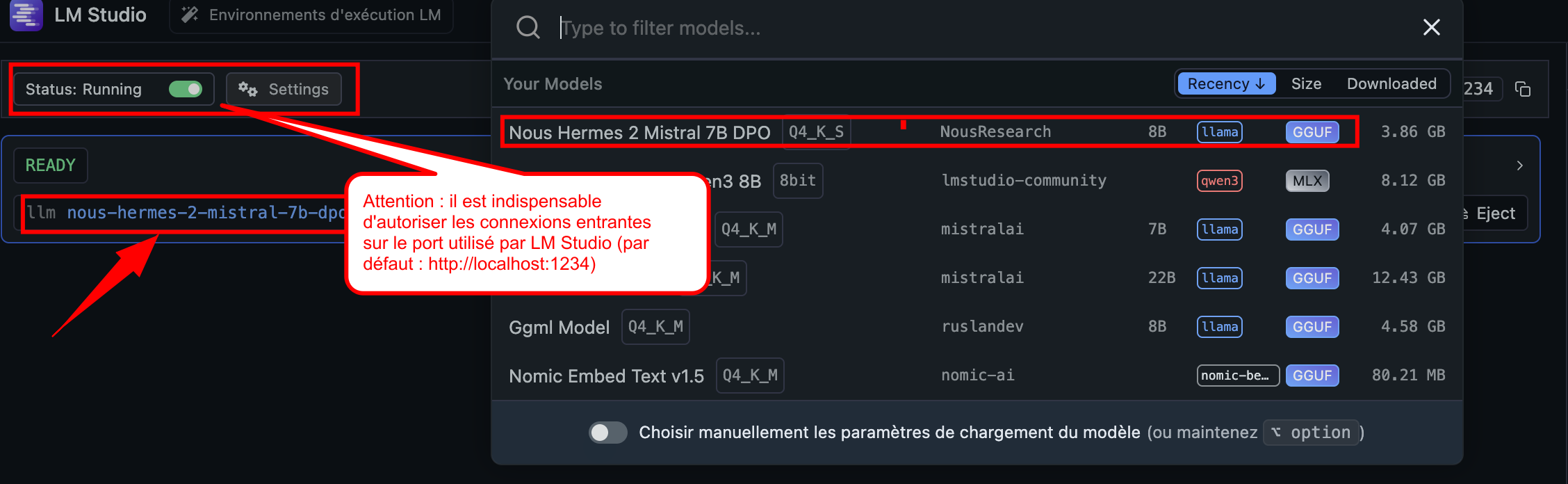
4.2 Configurer LM Studio pour permettre la communication avec le script
Pour que le script Python puisse interagir avec le modèle local via LM Studio, il est indispensable d’autoriser les connexions entrantes sur le port utilisé par LM Studio (par défaut : http://localhost:1234).
4.3 Croisement entre les segments textuels et les données statistiques
Le script repose sur un fichier CSV structuré, issu d’une étape précédente d’analyse statistique (notamment CHD et mesures de Chi2).
Ce fichier contient, pour chaque mot considéré comme discriminant, sa classe d’appartenance (issue de la classification hiérarchique), sa valeur de Chi2, sa fréquence, et surtout, les segments de textes dans lesquels il apparaît.
Les colonnes attendues sont : Mot, Classe, Segment, Nom_Segment, Chi2, p_value, Frequence.
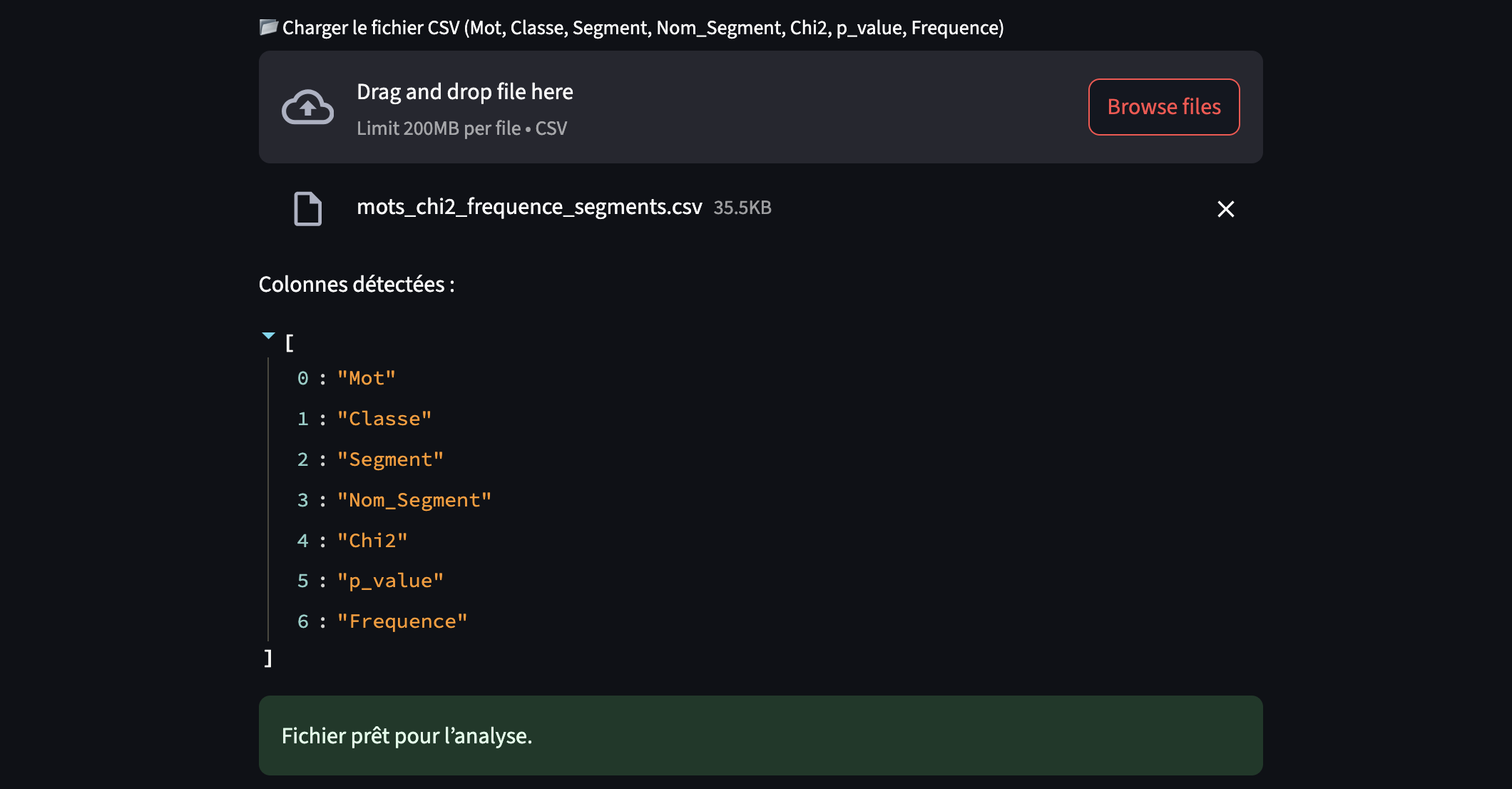
Lors du chargement, le script effectue alors deux opérations de croisement :
- Il construit un tableau des mots (
Mot,Chi2,Frequence), - Il extrait les segments textuels associés à cette classe (colonne
Segment) et y surligne les mots de la colonneMot.
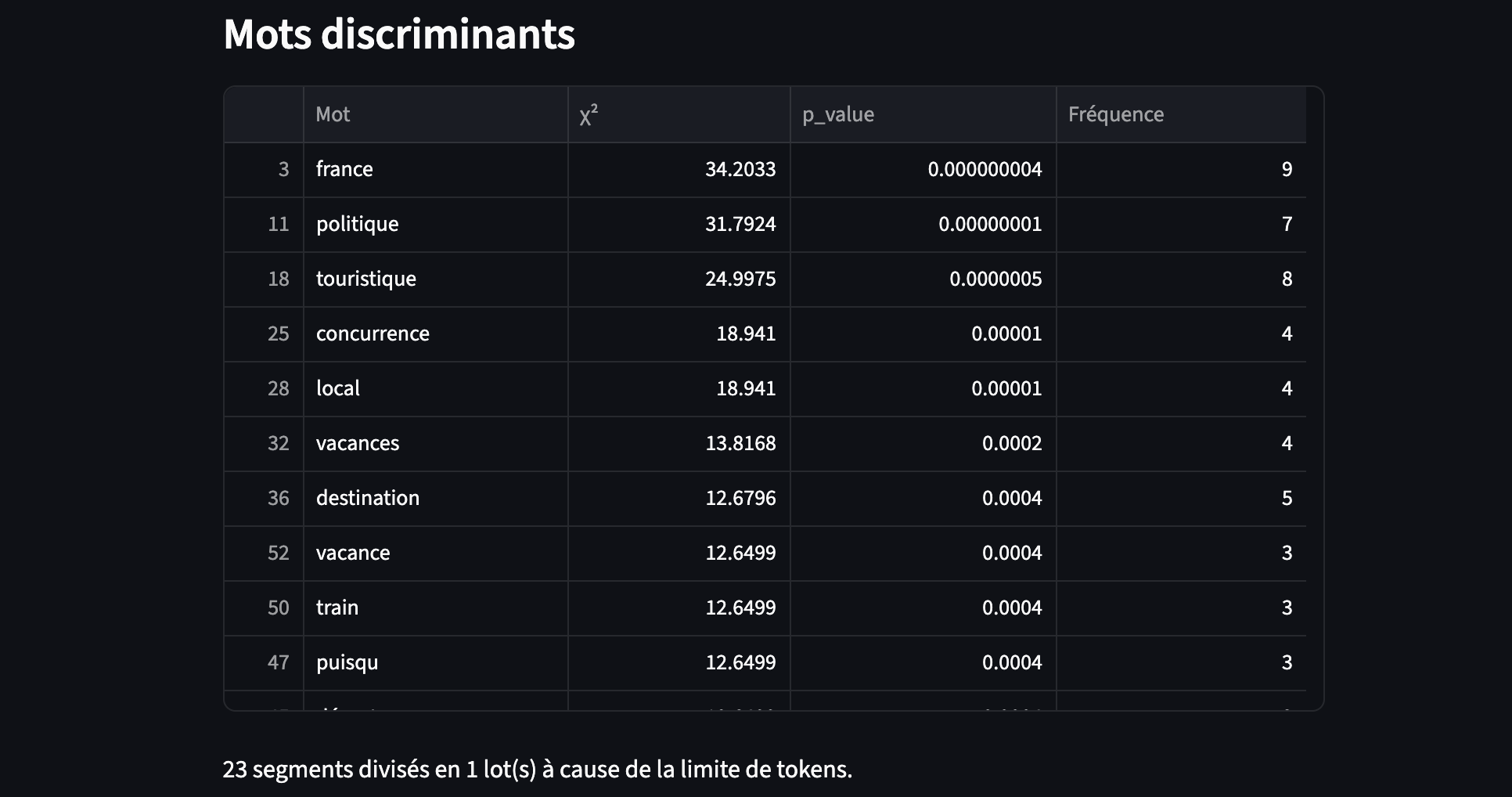
Chaque segment affiché est lié aux mots discriminants (sur-fréquent dans une classe).

Bien que la colonne p_value soit chargée depuis le CSV, elle n’est actuellement pas utilisée par le script pour l’analyse.
Le script est paramétré avec un prompt prédéfini, que vous pouvez modifier uniquement dans le code Python (et non via l’interface Streamlit). C’est sur la base de ce prompt que la classe sélectionnée et les segments associés — extraits du fichier CSV — sont soumis à l’analyse par le modèle de langage local.
# Construction base du prompt
base_prompt = f"""
Tu es un expert en analyse sémantique appliquée à un corpus sur le surtourisme.
Lors de l’analyse des segments, accorde une attention particulière à la fréquence des mots qui sur représente chaque classe
et à leur association avec les idées exprimées.
Tu dois analyser la classe {classe_choisie}. Voici les **mots discriminants** avec leur fréquence et chi² :
{chr(10).join([
f"- {row['Mot']} (χ²={round(row['Chi2'], 2)}, fréquence={int(row['Frequence'])})"
for _, row in mots_info.iterrows()
])}
Ta tâche :
1. Identifier les **thèmes dominants** en croisant ces mots avec les segments textuels
2. Analyser le rôle sémantique des mots dans les segments
3. Proposer une **synthèse structurée** de la classe
4. Donner un **titre sémantique pertinent**
Voici les segments :""".strip()
Ce bloc construit un prompt en injectant les mots discriminants (avec chi² et fréquence) pour une classe donnée, et ajoute ensuite les segments textuels.
C’est cette base textuelle qui est transmise à chaque lot du LLM pour analyse.
4.5 Sur la limite de tokens avec Nous-Hermes 2 – Mistral 7B
Le modèle utilisé dans ce script — Nous-Hermes 2, basé sur Mistral 7B — est limité par une fenêtre de contexte maximale de 8192 tokens.
Cette limite correspond au nombre total de tokens que le modèle peut traiter simultanément, en additionnant les tokens entrants (le prompt) et les tokens sortants (la réponse générée).
Par exemple, si le prompt occupe 3000 tokens, la réponse générée ne pourra pas dépasser 5192 tokens. Si la réponse attendue est très longue et donc si cette limite est dépassée, le modèle peut : tronquer le prompt et interrompre la réponse avec un message d’erreur explicite.

Dans ce script, la synthèse finale (puisque le script fonctionne par “lot” (découpage des segments de texte de la classe) pour esquiver ce probleme de fenêtre contextuelle) est particulièrement exposée à cette contrainte : en concaténant tous les résumés intermédiaires, la synthèse devient (parfois) trop longue. Cela explique pourquoi certaines synthèses échouent, même si l’analyse par lots fonctionne parfaitement.
Pour des usages plus ambitieux, il serait nécessaire soit de réduire la taille des entrées, soit d’utiliser un modèle avec une fenêtre de contexte élargie, si les ressources machines le permettent.
# Configuration de l'API LM Studio LMSTUDIO_API_URL = "http://localhost:1234/v1/chat/completions" LMSTUDIO_MODEL = "local-model" MAX_TOKENS_PROMPT = 1500 MAX_TOKENS_RESPONSE = 6500
Ces deux constantes définissent :
MAX_TOKENS_PROMPT: taille maximale que le prompt peut occuper,MAX_TOKENS_RESPONSE: taille maximale que la réponse générée est autorisée à atteindre.
4.6 La technique par lot pour outrepasser la limite des tokens
Si on dépasse cette limite (8000 tokens), le modèle tronque le contenu, ou l’API retourne une erreur.
Pour interroger le LLM avec plus de segments il faut découper le corpus en sous-ensembles (“lots”), chacun respectant cette limite.
On parle de batching ou de prompt chunking.

On peut remarquer, dans la capture d’écran ci-dessus/dessous, que la synthèse est répétitive… Les deux textes mériteraient même d’être passés au crible de l’analyse statistique (similarité cosinus, fréquence,..).
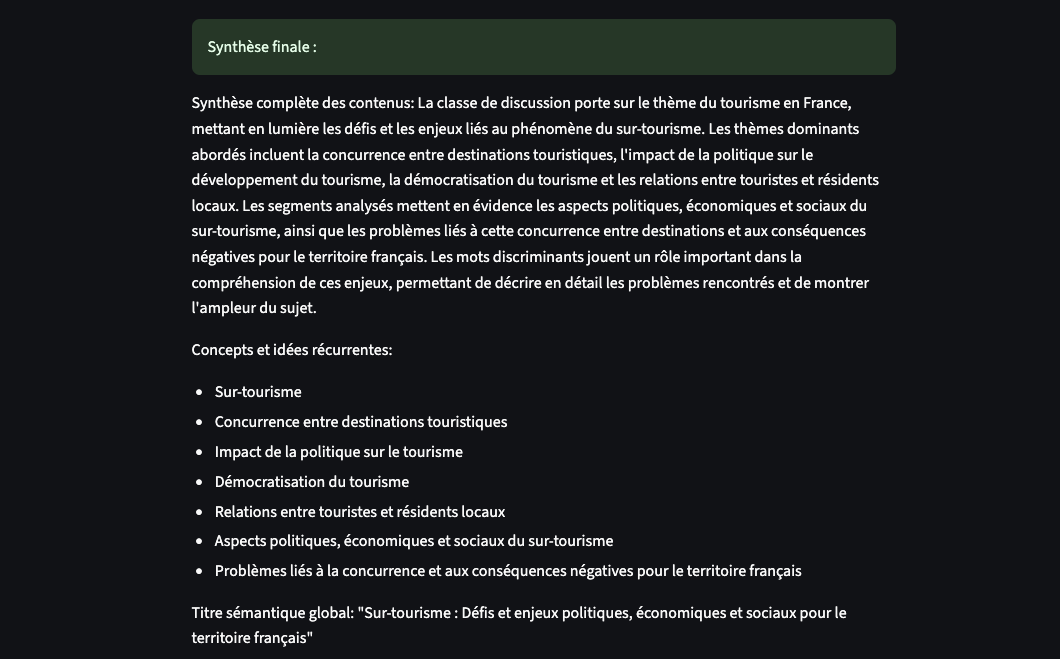
Chaque lot est traité séparément par le LLM, et ses réponses sont ensuite concaténées pour former une synthèse finale.
lots = []
current_lot = []
tokens_actuels = estimer_tokens(base_prompt) # Estime la taille du prompt initial (instructions + mots)
for segment in segments_uniques:
ligne = f"- {segment}" # Chaque segment est ajouté précédé d’un tiret
tokens_seg = estimer_tokens(ligne) # On estime le coût en tokens de ce segment
if tokens_actuels + tokens_seg >= MAX_TOKENS_PROMPT:
# Si on dépasse le seuil autorisé : on termine le lot courant
lots.append(current_lot)
current_lot = [ligne] # On commence un nouveau lot avec ce segment
tokens_actuels = estimer_tokens(base_prompt) + tokens_seg # Réinitialise le compteur
else:
current_lot.append(ligne) # On ajoute ce segment au lot courant
tokens_actuels += tokens_seg # On augmente le compteur de tokens
# Si un lot reste en attente, on l’ajoute
if current_lot:
lots.append(current_lot)
4.8 Le paramètre “Température”
La température est un hyperparamètre dans les LLM qui contrôle le niveau de variabilité, de créativité ou d’aléatoire dans les réponses générées par le modèle.
Lorsqu’un LLM prédit le mot suivant, il le fait en choisissant parmi une distribution de probabilités. La température agit sur cette distribution :
-
Température “basse” (ex. : 0.1 … 0.3). Ici, le modèle est “plus déterministe” : il choisit quasi systématiquement le mot le plus probable, la réponse plus est rigide, plus cohérente, mais moins “originale”.

-
Température “haute” (ex. : 1, 1.5…). Le modèle prend plus de “risques”, choisit parfois des mots moins probables. Les réponses sont plus “créatives”, mais potentiellement incohérentes.


La température utilisée dans les LLM est liée à la notion d’entropie de Shannon en théorie de l’information.
Vous pouvez modifier la valeur “température” directement dans le script.
Conclusion et pistes d’amélioration
Cette première version du script fonctionne, mais reste largement perfectible. De nombreux paramètres restent à tester, affiner, ou étendre, tant du point de vue technique que méthodologique.
1. Tester un modèle plus puissant
L’utilisation d’un modèle plus performant (plus de paramètres) permettrait d’obtenir des réponses plus nuancées, mieux structurées, et plus cohérentes sur le plan thématique.
En contrepartie, cela impose des ressources machines nettement plus importantes (dans mon exemple j’utilise un Mac – M2 – 64go). Le choix du modèle reste donc un équilibre entre puissance, stabilité et faisabilité locale.
2. Rendre le prompt modifiable depuis l’interface
Actuellement, le prompt est codé en dur dans le script. Une amélioration immédiate consisterait à permettre à l’utilisateur de rédiger un prompt personnalisé directement dans l’interface Streamlit.
3. Guider l’analyse par des références théoriques
Dans la logique d’un prompt enrichi, il serait pertinent de permettre à l’utilisateur d’insérer une ou plusieurs références théoriques (notions-clés, concepts, approches théoriques) pour orienter l’analyse.
4. Pondérer les mots discriminants selon leur fréquence et leur valeur de χ², afin d’indiquer clairement au LLM quels termes sont les plus significatifs dans l’analyse sémantique (et potentiellement adapter le prompt en conséquence).
5. Injecter des documents comme contexte (vers une logique RAG (à la mode !))
Enfin, une évolution plus ambitieuse consisterait à permettre l’ajout de documents de référence. Cette approche s’apparente à celle d’un dispositif RAG (Retrieval-Augmented Generation), où le LLM ne répond pas « uniquement à partir de sa base d’entrainement », mais s’appuie sur un ensemble de documents injectés dans le contexte. Cela permettrait d’ancrer l’analyse dans un corpus secondaire structurant (cadres conceptuels, corpus de référence, éléments théoriques…).
6. Tracer les décisions du LLM
Actuellement, on obtient une réponse, mais on pourrait vérifier sur quoi elle s’appuie précisément. Ainsi on pourrait construire un “mécanisme de justification” (ex. : “sur quels mots ou expressions vous appuyez-vous ?”), comparer les sorties du LLM à celles d’un expert ou d’un modèle classique et confronter les synthèses obtenues.
Ces éléments permettront sans doute d’apporter une réponse plus consistante.
Cela dit, comme le rappelle Yann LeCun, “aucune IA actuelle n’est plus intelligente qu’un chat de gouttière”.
On ne pourra réellement parler d’intelligence artificielle “forte” que lorsque les modèles seront capables de se forger une représentation du monde, c’est-à-dire de comprendre, percevoir, et apprendre au-delà de la simple prédiction de tokens.