Cette application s’inscrit dans une logique de reproductibilité des résultats d’une CHD à partir d’un même corpus texte, en comparaison avec ceux produits par le (vrai) logiciel IRaMuTeQ, (Pierre Ratinaud – Laboratoire d’Études et de Recherches Appliquées en Sciences Sociales (LERASS) – Université Toulouse Jean-Jaurès) – qui reste le logiciel de référence libre dans ce domaine.
L’idée n’est pas de dire que tout est strictement identique, ni de prétendre remplacer le logiciel, mais bien de reprendre au plus près sa logique de calcul pour voir jusqu’où on peut retrouver des résultats proches à partir d’un même corpus. Cette question de la reproductibilité est importante, parce qu’en analyse textuelle les résultats dépendent autant du corpus que de la manière dont on le découpe, le nettoie, le normalise avant la classification.
Au final, au-delà de l’aspect statistique qui permet le découpage des classes, une CHD est aussi une affaire de compromis dans la préparation du corpus et dans les objectifs de l’analyse, selon que l’on cherche à obtenir un découpage avec de nombreuses classes ou inversement.
https://huggingface.co/spaces/stephane09/IRaMuTeQ-lite
Le script IRaMuTeQ-lite est hébergé sur la plateforme gratuite de Hugging Face. C’est à la fois chouette et frustrant, car la version gratuite offre peu de ressources en CPU/RAM.
1. Déterminer les classes… ou pas…
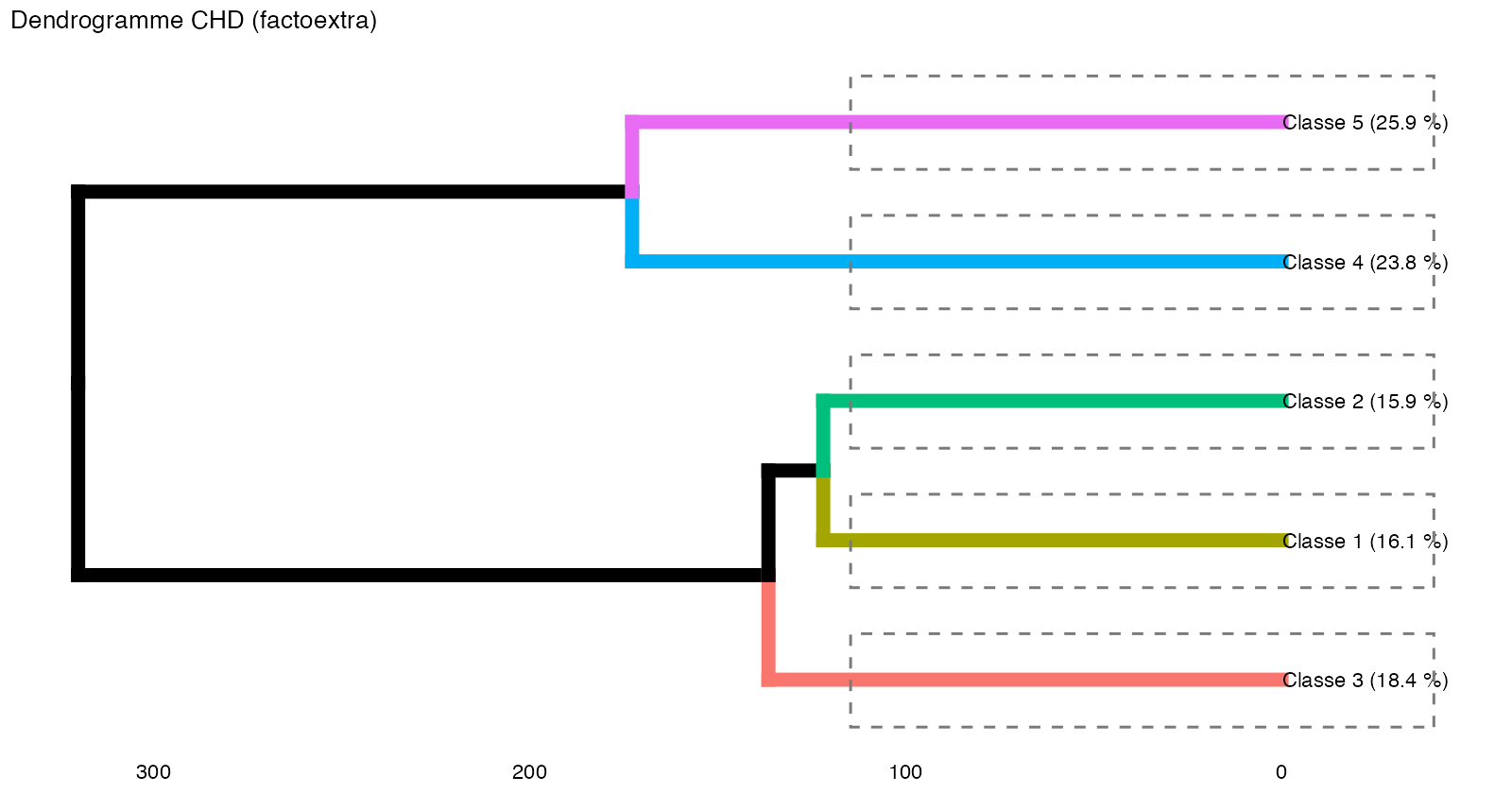
D’un point de vue du calcul, le script reprend une logique de reproduction qui tient notamment au fait que le nombre de classes k n’est pas défini en amont, comme avec Rainette. Dans Rainette, vous pouvez par exemple définir k = 8 (k = classes) et, dans l’interface “rainette_explor” (affichage des résultats), diminuer le nombre de classes afin d’observer la meilleure répartition / segmentation. C’est un peu la logique de tâtonnement avec rainette : il vaut mieux afficher au départ un nombre élevé de clusters ou de classes, puis le réduire ensuite.
Dans mes expériences avec Rainette, j’ai parfois obtenu, sur de très gros corpus de textes (issus de plus de 1000 articles de (Euro)presse), des résultats en 3 classes, avec notamment 1 classe ne contenant que très peu de segments de texte.
On se retrouve parfois avec des classes terminales extrêmement petites composées de seulement deux ou trois segments de texte, soit à peine 1 à 2 % de l’ensemble des segments classés…
2. Le dictionnaire de lemme
La logique de reproduction ne porte pas seulement sur le mode de calcul. Elle repose aussi sur l’usage du même dictionnaire que celui mobilisé dans IRaMuTeQ.
Avec Rainette j’utilisais la bibliothèque spaCy pour filtrer notamment les stopwords, IRaMuTeQ ne fonctionne absolument pas avec une bibliothèque de type spaCy ou quanteda, et encore moins avec une logique binaire du type avec ou sans stopwords.
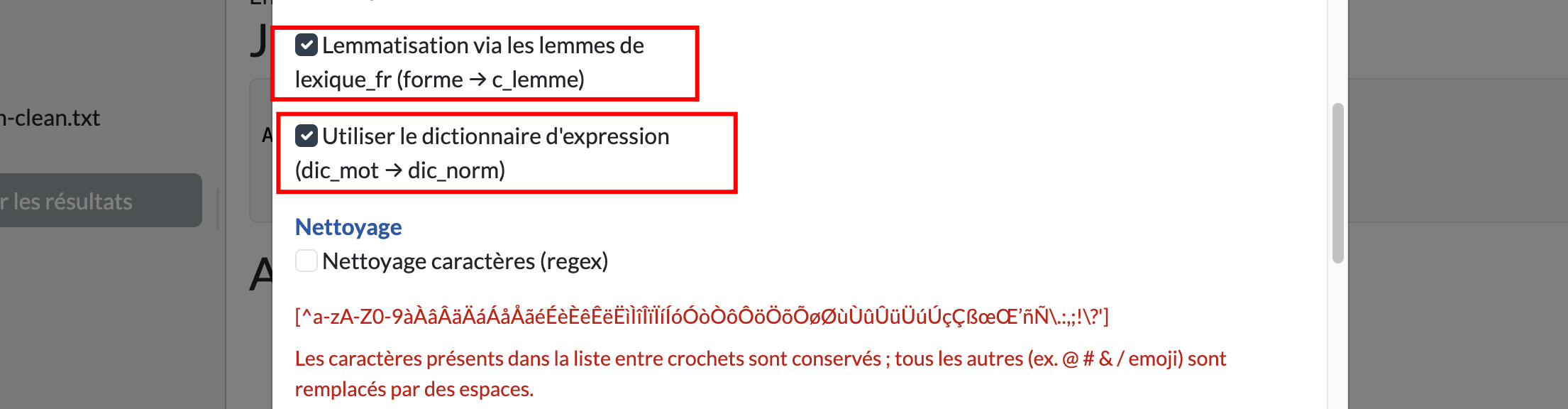
Tout repose sur un dictionnaire renseignant les termes, les lemmes et les catégories morphosyntaxiques, issu d’OpenLexicon. C’est un point important à souligner, car ce dictionnaire est nettement plus précis, en particulier lorsqu’il est complété par le dictionnaire d’expressions, par exemple « aujourd’hui » normalisé en « aujourd_hui ».
Dans le script, vous avez toutefois deux possibilités. Soit vous passez par un filtrage des stopwords, (package utilisé “quandeta”), soit vous entrez dans la logique d’un filtrage morphosyntaxique fondé sur les catégories du dictionnaire lexique_fr, qui constitue une copie du dictionnaire utilisé dans le logiciel IRaMuTeQ.
3. Les clés d’analyse
En revanche, la logique des clés d’analyse actives et supplémentaires, telle qu’elle est encodée dans IRaMuTeQ, n’est pas reprise ici à l’identique (active/supplémentaire).
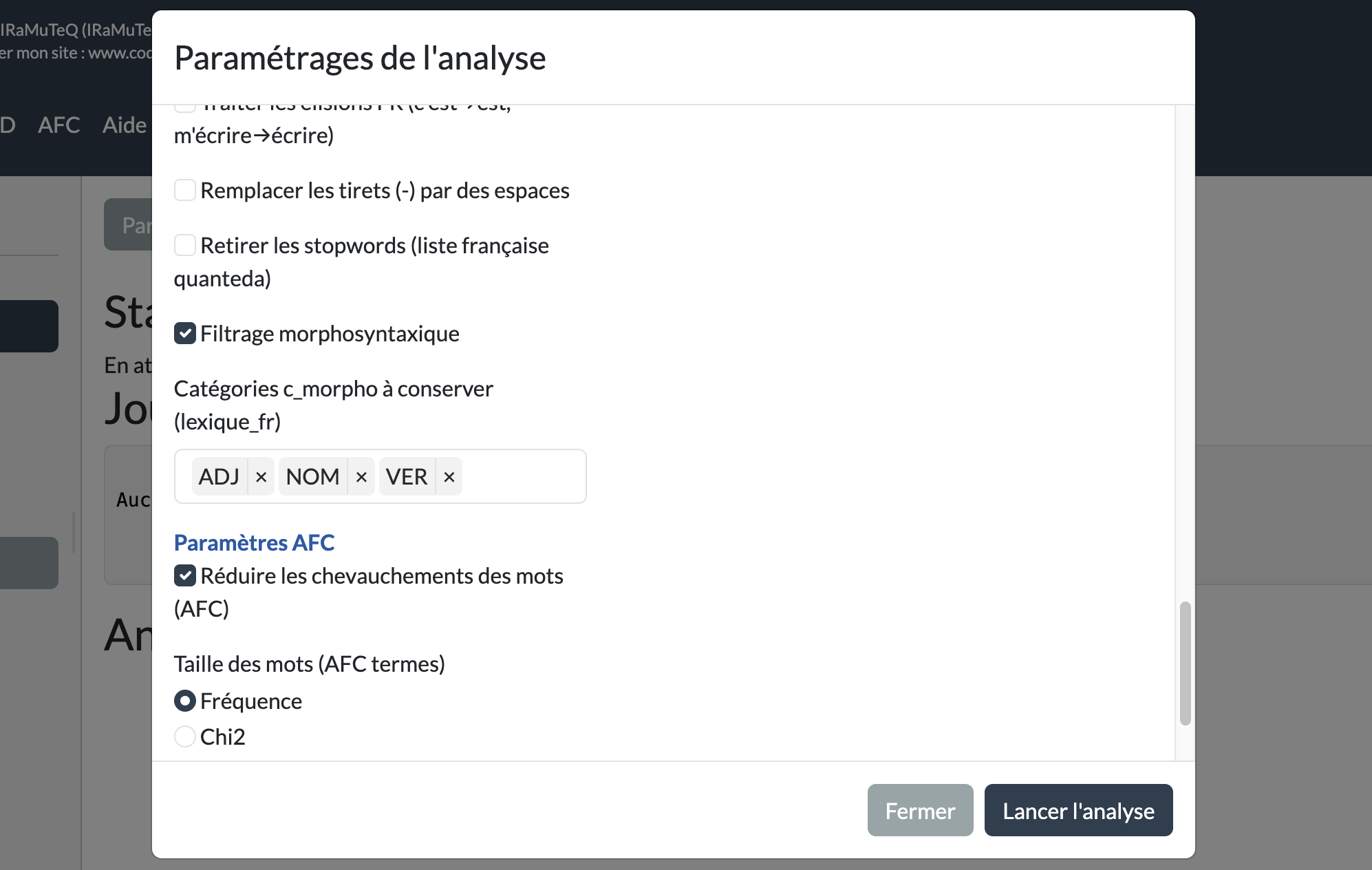
Dans cette application, l’utilisateur choisit directement dans l’interface les catégories morphosyntaxiques qu’il souhaite conserver. On est donc dans une logique binaire de présence ou d’absence des catégories retenues dans le calcul.
Ce fonctionnement diffère du logiciel, où la distinction entre catégories actives et catégories supplémentaires structure plus finement l’analyse, notamment avec deux AFC distinctes, l’une pour les catégories actives et l’autre pour les catégories supplémentaires.
4. Les options de nettoyage
Il existe aussi des écarts sur les options de nettoyage du texte. Elles ne sont pas toutes strictement identiques à celles du logiciel. Par exemple, l’application permet d’activer les stopwords de quanteda, ce qui n’existe pas sous cette forme dans IRaMuTeQ.
Ce simple point peut déjà modifier sensiblement la matrice lexicale produite à partir d’un même corpus.
5. Nombre minimum de segment de texte par classe
Le paramètre “Nombre minimum de segments de texte par classe” (mincl = auto) est un seuil indiquant combien de segments une classe doit contenir au minimum pour être conservée telle quelle dans le résultat final. En mode auto, la valeur de mincl est calculée automatiquement par le moteur (et non saisie par l’utilisateur).
6. Fréquence minimum d’une forme analysée
Cette option permet de fixer un seuil minimal de fréquence pour qu’une forme soit conservée dans l’analyse. En mode automatique, un terme doit apparaître au moins 3 fois pour être retenu dans le calcul.