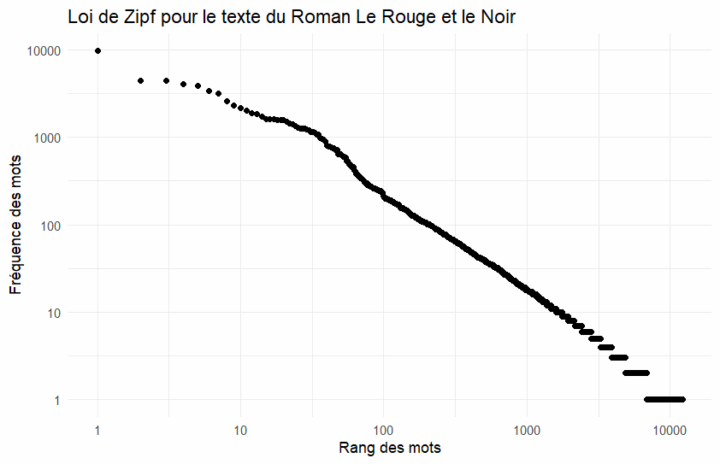
RapidFuzz est une bibliothèque Python conçue pour effectuer de la correspondance de chaînes de caractères, ce qui signifie qu’elle compare des textes et évalue à quel point ils sont similaires, même si des fautes de frappe ou des différences existent. L’objectif de cet article est de simuler un chatbot utilisant la librairie RapidFuzz afin de tester la pertinence des réponses par rapport au...