
RapidFuzz est une bibliothèque Python conçue pour effectuer de la correspondance de chaînes de caractères, ce qui signifie qu’elle compare des textes et évalue à quel point ils sont similaires, même si des fautes de frappe ou des différences existent.
L’objectif de cet article est de simuler un chatbot utilisant la librairie RapidFuzz afin de tester la pertinence des réponses par rapport au texte saisi, et ce, même si la requête comporte des fautes.
L’application no code sur stremlitcloud : https://spacy-chatbot.streamlit.app/
Le code source sur Github pour tester en local
Le ChatBot répond à des questions sur les lacs et étangs du territoire touristique du Couserans. Les informations intégrées sont volontairement limitées, car il s’agit simplement d’une démonstration.
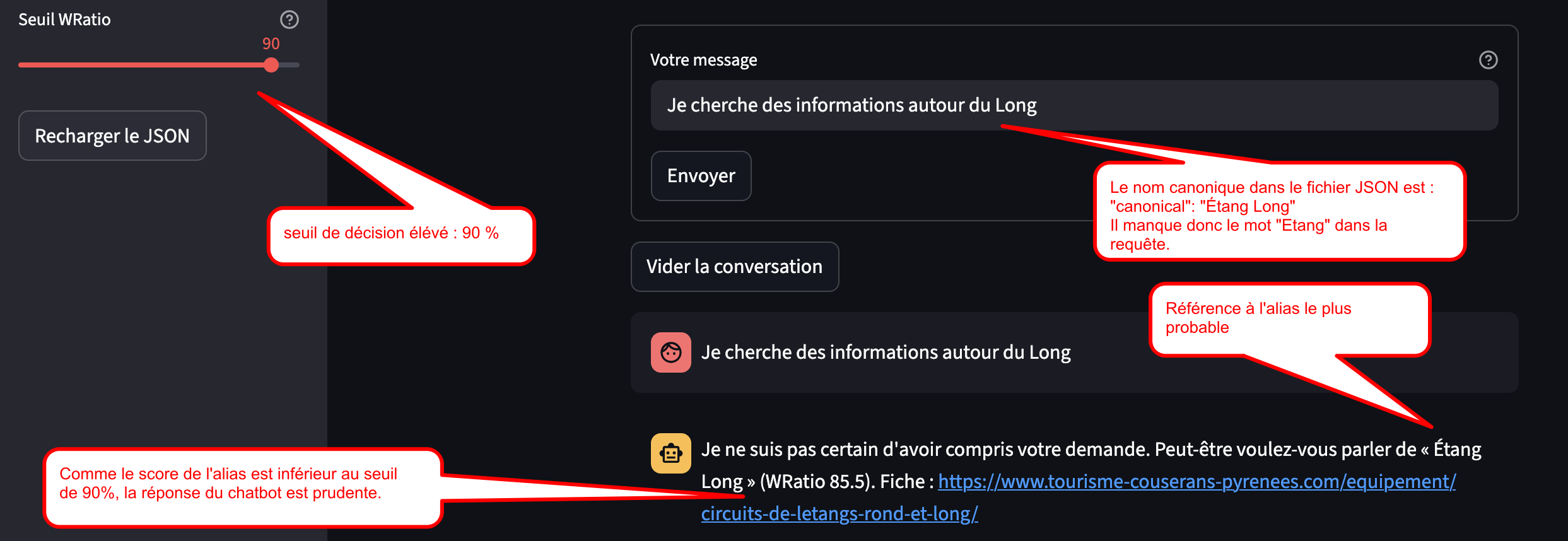
Comme il est probable que vous ne connaissiez pas cette région, l’application affiche, juste sous le titre, la liste des lacs présents dans le fichier JSON. Cela vous permet de formuler vos propres requêtes et, si vous le souhaitez, de tester la robustesse du chatbot en introduisant volontairement des fautes dans vos questions.

La requête est donc comparée à ce dictionnaire (JSON) pour tolérer les fautes (accents manquants, faute de frappe, langage “SMS”,…).
La réponse du ChatBot est conditionnelle selon un seuil WRatio (par défaut 80, modifiable dans la barre latérale de l’interface Streamlit).
requête (normalisée) ├─ WRatio vs aliases (normalisés) │ ├─ Score différenciateur (pour départager les ex-aequo) │ └─ Seuil : ≥ seuil → réponse affirmative < seuil → réponse prudente (+ garde-fou : s’il n’y a ni canonical, ni alias, ni toponyme → “Je n’ai pas compris”)
Le chatbot applique trois niveaux de réponse :
-
Affirmation — Score supérieur ou égal au seuil
Le meilleur score WRatio (après agrégation par nom canonique, et éventuel boost toponymique) est ≥ seuil => “Je comprends que votre demande concerne “…”. » -
Suggestion “prudente” — Score inférieur au seuil
Le meilleur score est < seuil => “Je ne suis pas certain… peut-être voulez-vous parler de “…”. »
- “Garde-fou”
La requête ne contient aucune trace d’un nom du JSON (ni canonical, ni alias, ni toponyme, même tronqué) => “Je n’ai pas compris votre question.”
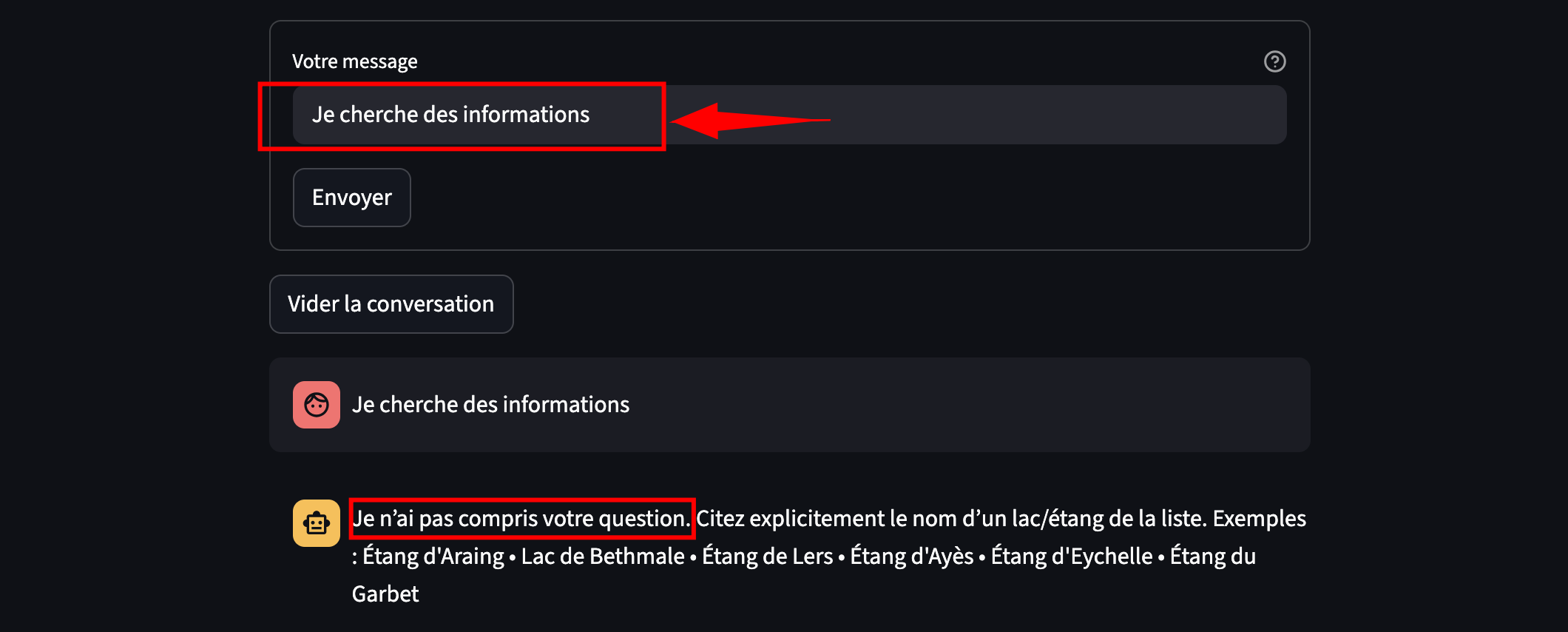
La réponse du chatbot est ici accessoire : elle reste conditionnelle et incomplète. Son rôle est surtout d’illustrer la manière dont la décision repose sur l’utilisation de RapidFuzz.
1. Fonctionnement théorique
RapidFuzz utilise des algorithmes optimisés pour comparer des chaînes efficacement, en s’appuyant sur la distance de Levenshtein et d’autres métriques de similarité. Ces algorithmes sont principalement implémentés en C++ pour la rapidité.
1.1 ratio
Compare les deux chaînes en entier, caractère par caractère.
from rapidfuzz import fuzz
score = fuzz.ratio("Lac de Bethmale", "cascade d'ars")
print("Score ratio:", score)
# résultat 40% de similitude
1.2 partial_ratio
Recherche la partie la plus similaire entre les deux chaînes.
from rapidfuzz import fuzz, utils
score_partial = fuzz.partial_ratio("Lac de Bethmale", "cascade d'ars", processor=utils.default_process)
print("partial_ratio (insensible casse) :", score_partial)
# résultat : 50% de similitude
1.3 token_sort_ratio
Trie les mots dans chaque chaîne puis compare la similarité, insensible à la casse.
score_token_sort = fuzz.token_sort_ratio("Lac de Bethmale", "cascade d'ars", processor=utils.default_process)
print("token_sort_ratio (insensible casse) :", score_token_sort)
# résultat 50 % de similitude
1.4 token_set_ratio
Compare les ensembles de mots communs dans les chaînes, insensible à la casse.
score_token_set = fuzz.token_set_ratio("Lac de Bethmale", "cascade d'ars", processor=utils.default_process)
print("token_set_ratio (insensible casse) :", score_token_set)
# resultat 35.71 % de similitude
1.5 Score WRatio
Le score WRatio est utilisé dans le script pour évaluer la similarité en combinant plusieurs méthodes de comparaison.
La méthode WRatio est donc hybride : WRatio combine automatiquement plusieurs scores selon la situation (notamment ratio, partial_ratio, token_sort_ratio, token_set_ratio) pour obtenir le score de similarité (matching) le plus fiable possible.
Bon, ça, c’est pour la théorie !
On constate rapidement que ces quatre fonctions vont nous aider, mais qu’il va falloir ruser pour optimiser le “matching” afin de répondre aux contraintes d’un chatbot destiné à un site internet, où les requêtes sont souvent formulées dans un français « de bistrot » 😉 , spontané et parfois (très) approximatif.
2. L’architecture du script
L’architecture repose sur un “dictionnaire” stocké au format JSON, que l’on peut enrichir facilement.
Chaque entrée décrit un lieu via un nom canonique (forme de référence), une liste d’aliases (variantes d’écriture, accents, fautes…) et, séparément, des toponymes (utilisés comme garde-fou).
Des métadonnées optionnelles (label, catégorie, URL) complètent la fiche.
L’application charge ce JSON, construit un index (aliases => canonique) et effectue le matching WRatio uniquement sur les aliases, tandis que les toponymes servent à filtrer les requêtes “hors sujet”.
Cette séparation “données (JSON) / logique (app.py)” permet à un utilisateur non développeur d’ajouter facilement de nouveaux lieux ou variantes.
# exemple de contenu dans le fichier JSON
{
"canonical": "Étang de Lers",
"aliases": ["Etang de Lers", "Lac de Lers", "Lers", "l'hers", "Lhers", "Hers"],
"toponyms": ["lers", "hers"],
"label": "LAC",
"category": "couserans",
"url": "https://www.tourisme-couserans-pyrenees.com/patrimoine-naturel/etang-de-lers/"
},
Un script est en préparation pour générer automatiquement des alias à partir d’un nom canonique (variantes sans accents, apostrophes, tirets, inversions et fautes usuelles…), afin d’accélérer l’enrichissement du JSON.
3. Expérimentation et amélioration
Le script va suivre le processus suivant :
- Préparation des données : Charger les entrées (fichier JSON) : nom canonique, aliases, toponymes
- Normalisation de la requête (minuscules,..)
- Calculer le WRatio
- Départager les éventuels ex æquo (score différenciateur)
- Garde-fous : Si l’on ne détecte ni canonical, ni alias, ni toponyme pertinents (zéro “match”)
3.1 Le nom canonique
Dans un dictionnaire, le nom canonique est la forme de référence d’un objet : celle qu’on affiche et à laquelle on rattache tout le reste (métadonnées, catégorie, URL, …). Exemple : « Lac de Bethmale » : C’est l’identifiant de référence de ce lieu, même si le public l’écrit de mille façons.
3.2 Le rôle des aliases dans le matching
Un alias est toute variante d’écriture utilisée par les internautes : fautes, accents manquants, tirets, fautes de frappe, abréviations, langage “texto”… Exemple pour “Bethmale” : “lac betmale”, “Baithmale”, “bethmmale”...
Dans le script, le matching fonctionne ainsi : la requête est normalisée (minuscules,…), puis comparée avec toutes les formes d’alias via WRatio. Chaque alias renvoie vers un nom canonique et on garde le meilleur score obtenu par l’un de ses aliases.
Résultat : même si l’utilisateur n’écrit pas la forme “officielle”, il y a de fortes chances qu’au moins une variante corresponde.
3.3 Fonction de normalisation
La normalisation “légère” du script rend le matching beaucoup plus robuste face aux accents manquants, aux variantes de casse et à la ponctuation. On ne fait ni stemming ni suppression des stopwords — c’est volontairement minimaliste. En revanche, cette normalisation devrait, en principe, éviter de décliner les alias selon la ponctuation ou la casse (majuscules/minuscules). Mais cette fonction a été ajoutée après coup dans le script, c’est pourquoi vous trouverez encore une déclinaison des alias selon leur ponctuation.
import re, unicodedata
def normaliser(s: str) -> str:
"""
- minuscules
- suppression des accents
- petite ponctuation -> espace (- _ ’ ' . , /)
- espaces compactés
"""
if not s:
return ""
s = s.lower()
s = unicodedata.normalize("NFKD", s)
s = "".join(ch for ch in s if not unicodedata.combining(ch))
s = re.sub(r"[-_’'.,/]+", " ", s)
s = re.sub(r"\s+", " ", s).strip()
return s
3.4 Fonction de toponymie
La toponymie, c’est tout simplement l’art de s’appuyer sur le vrai nom propre du lieu (le mot distinctif) : Garbet, Bethmale, Lers, etc…
Dans une requête contenant « Étang du Garbet », les mots « étang / du » sont “génériques” et se retrouvent partout ; le mot utile ici c’est “Garbet”.
Quand un utilisateur écrit « etan garbe » (avec fautes), on veut tout de même comprendre qu’il parle de “Garbet” grâce à cette partie distinctive du nom.
Concrètement, après avoir calculé les scores de similarité, on regarde si la requête ressemble à un toponyme ; si oui, on “match” ce lac dans les résultats.
3.5 Le “garde-fou”
On recherche dans le dictionnaire JSON (le nom canonique, l’alias, le toponyme) , et si rien n’est trouvé on répond simplement qu’on n’a pas compris la question.
3.6 Le score “différenciateur”
Quand deux (ou plusieurs) lacs obtiennent le même score WRatio avec la requête complète, on calcule un deuxième score (non affiché) sur des versions “sans stopwords“ de la requête et de chaque alias. Ainsi on applique toujours la normalisation et on retire les mots génériques (stopwords spécifiques à notre analyse : “lac”, “étang”, “de/du/des”, “le/la/les”, “sur”, …) ;
# Mots très génériques (pour ignorer les tokens sans valeur sémantique et départager les ex-aequo)
GENERIC = {"lac","lacs","etang","étang","etangs","étangs","de","du","des","la","le","les","l","d","sur","aux","au"}
Ce score “différenciateur” ne remplace pas le score principal : il sert uniquement à trier les “candidats” qui avaient le même score WRatio. Autrement dit, on garde le score affiché tel quel, mais on réordonne les ex æquo grâce au score différenciateur.
Conclusion
L’article est long et plutôt technique. On aurait pu, à titre d’expérimentation, intégrer des règles Regex (mais cela n’aurait pas été dans un fichier JSON) ou encore des stopwords directement dès le début des calculs.
Ici, l’objectif était plutôt de construire une interface reposant sur RapidFuzz et un fichier JSON facile à alimenter en données. Il n’est pas simple de trouver le bon paramétrage de RapidFuzz, mais l’exemple présenté ici est plutôt concluant.