Reddit est un réseau social d’origine américaine fondé en 2005, qui se distingue des plateformes comme Facebook, X ou Instagram… par son fonctionnement communautaire et thématique. Structuré autour de “subreddits” (forums dédiés à des sujets spécifiques), Reddit permet aux utilisateurs de publier, commenter et voter des contenus textuels, visuels.
Si Reddit occupe une place centrale dans l’écosystème numérique anglophone, il reste encore peu utilisé en France. Notez que le script cible les posts et commentaires en Français uniquement.
Une rapide analyse des messages montre toutefois des posts et des commentaires plutôt bien structurés sur le plan linguistique. Toutefois, même si j’ai créé un compte pour les besoins du développement de l’application, je n’investis pas personnellement ce réseau social pour le moment.
Quelques notions
Sur Reddit, chaque utilisateur possède un profil personnel identifié par un pseudonyme précédé du préfixe u/ (pour “user”) : par exemple u/JeanLeGrand.
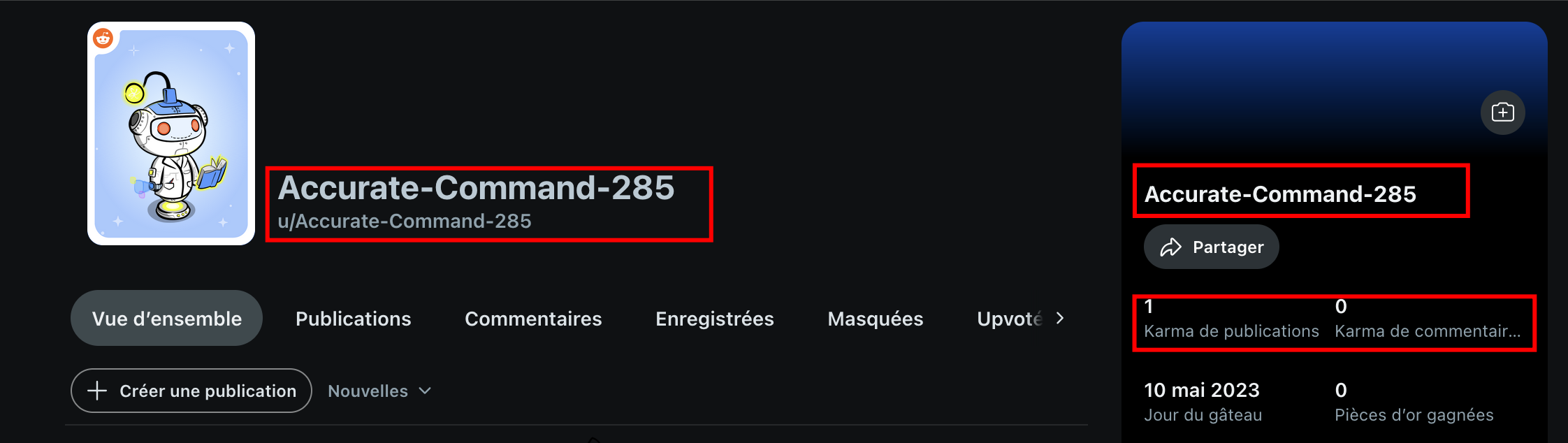
Ce profil permet de consulter l’historique public des publications et commentaires de l’utilisateur, ainsi que son “karma”, un score agrégé reflétant la réception positive ou négative de ses contributions par la communauté.
Les interactions sur Reddit s’articulent principalement autour de trois mécanismes :
- La publication de contenu (texte, lien ou image),
- Les commentaires
- Le vote (positif ou négatif) sur les publications et les commentaires.
Contrairement aux réseaux sociaux traditionnels, Reddit ne repose pas sur un système d’amis ou d’abonnés personnels, mais sur l’abonnement à des communautés thématiques appelées “subreddits“, identifiées par le préfixe r/ (ex : r/France, r/technologie).

Bon, là je suis un peu perdu, car on ne sait pas distinguer le vrai du faux, c’est-à-dire qu’on ne sait pas vraiment si cela correspond à une page officielle… De fait, le script permet de réaliser une recherche par mot-clé, plutôt que de cibler une communauté.
Créer son application
Je passe les détails sur la création d’un compte sur la plateforme Reddit qui est obligatoire avant de passer à la création de son API. L’utilisateur doit donc se connecter à son compte Reddit (avant), puis se rendre sur la page https://www.reddit.com/prefs/apps.
En haut de cette page, il peut créer une nouvelle application en choisissant le type “script”.
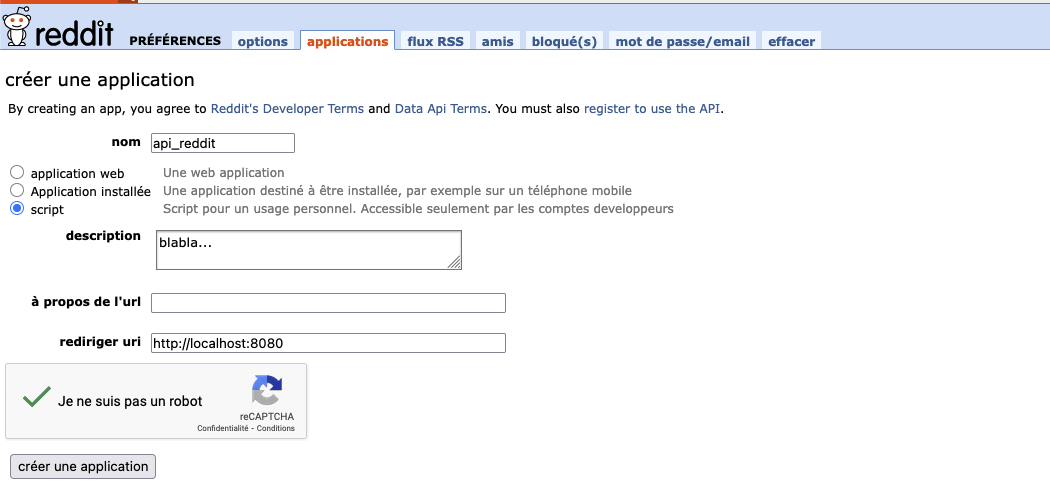
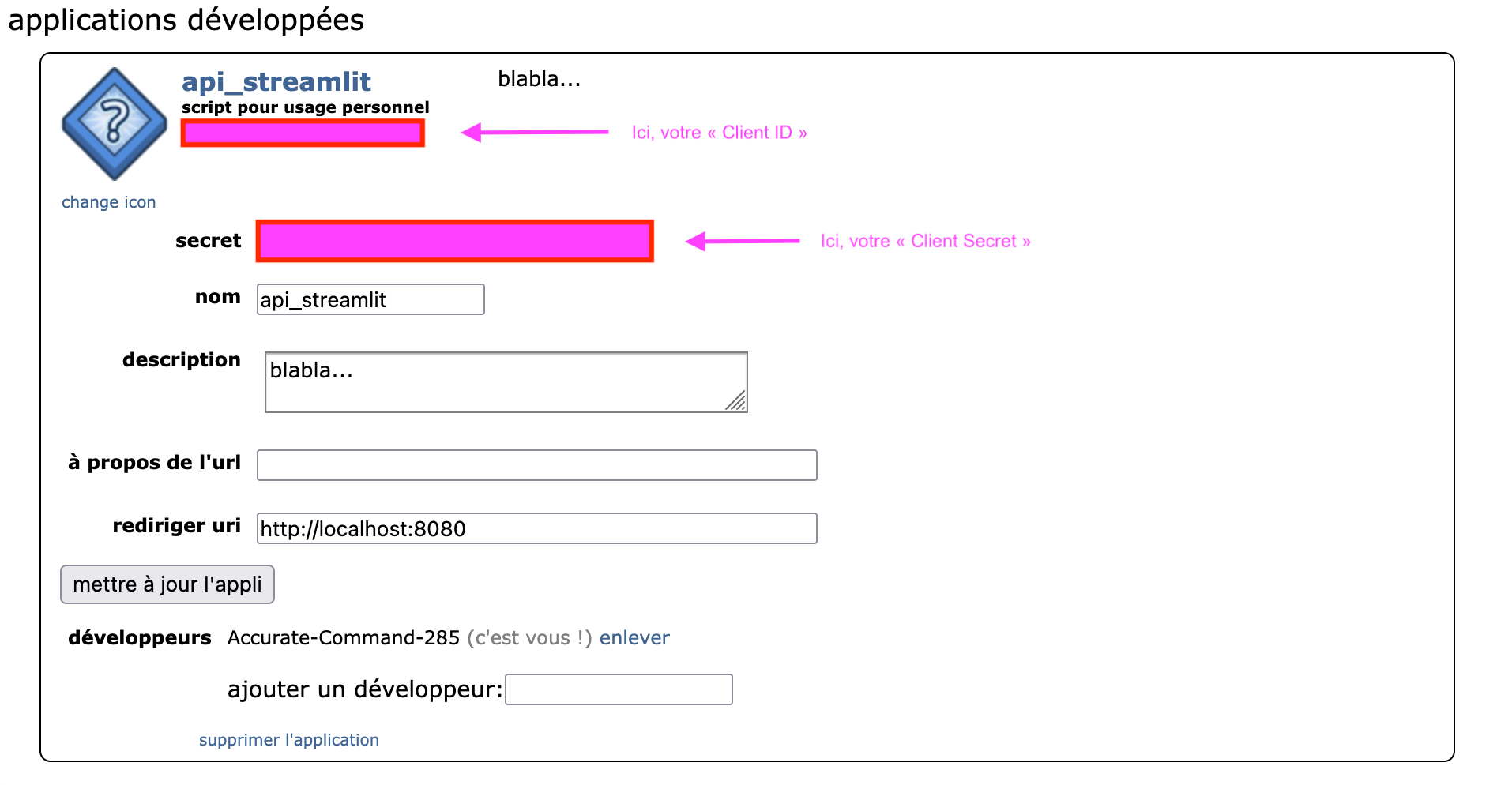
Une fois l’application enregistrée (“créer une application”), Reddit fournit deux éléments essentiels :
- le
client_id(identifiant public de l’application) - le
client_secret(clé privée).
Ces deux paramètres sont requis pour connecter streamlit (le script) avec l’API.
Lorsque vous lancerez l’application streamlit, en plus du “Client ID” et du votre clé “Client secret” vous devrez spécifier un user_agent, afin que Reddit puisse identifier l’application.
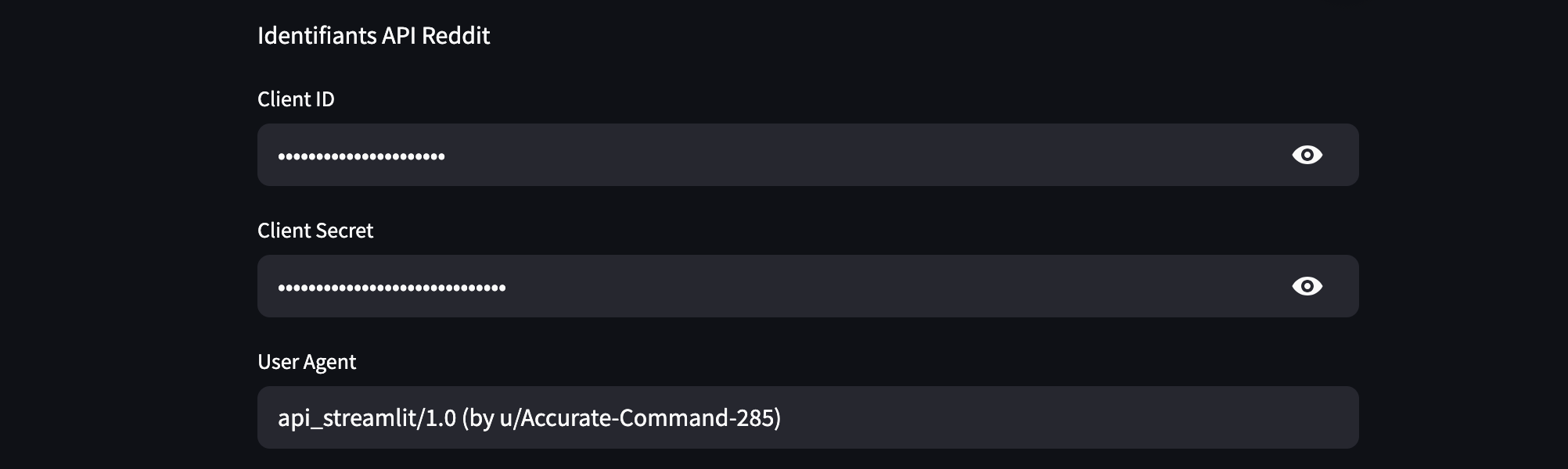
Par convention, cette chaîne doit mentionner le nom de l’application, sa version, ainsi que le pseudonyme Reddit de l’utilisateur, sous une forme telle que : "nom_de_l_application/1.0 (by u/nom_utilisateur)" afin déviter tout blocage de l’API par Reddit.
Elle permet (surtout) à l’équipe de Reddit de repérer d’éventuels problèmes techniques liés à une application spécifique.
Certains utilisateurs intègrent dans leur user_agent des informations très détaillées (comme la version du navigateur ou du système), mais à notre niveau, cela n’est pas nécessaire.
En pratique, la formule : nom_de_l_application/1.0 (by u/nom_utilisateur) suffit amplement.
La recherche par mot-clé
Sur Reddit, il n’existe pas de traitement particulier des hashtags comme on en trouve sur d’autres réseaux sociaux (X). Dans le script, saisissez votre mot clé sans le #.
La recherche avec guillemets : Reddit interprète cela comme une expression exacte (Exemple “Emmanuel Macron”).
Parmi les options, vous pouvez également définir une date de début pour votre requête.
Personnellement, je n’ai pas testé l’application avec des dates antérieures au début de cette année. Reste à savoir si elle fonctionnera correctement avec l’extraction d’un volume de données plus important.
Le code source
Voila vous avez toute les infos pour créer votre API et lancer le script dans votre terminal : streamlit run main.py
Avant de le lancer vous devrez installer trois librairies via la commande pip install streamlit praw langdetect
PRAW (Python Reddit API Wrapper) gère la récupération de données depuis Reddit.
Le script
# pip install streamlit praw langdetect
# python -m streamlit run main.py
import streamlit as st
import praw
from langdetect import detect, LangDetectException
from datetime import datetime
import time
# Détection de la langue
def est_en_francais(texte):
try:
return detect(texte) == 'fr'
except LangDetectException:
return False
# Conversion date -> timestamp
def date_to_timestamp(date_obj):
return int(time.mktime(date_obj.timetuple()))
# Recherche Reddit
def rechercher_posts_depuis_date(mot_cle, client_id, client_secret, user_agent, date_debut_timestamp, filtre_titre_seulement=False):
reddit = praw.Reddit(client_id=client_id,
client_secret=client_secret,
user_agent=user_agent)
posts = reddit.subreddit("all").search(mot_cle, sort="new", limit=None)
resultats = []
total_commentaires = 0
for post in posts:
if post.created_utc < date_debut_timestamp:
break
if filtre_titre_seulement and mot_cle.lower() not in post.title.lower():
continue
contenu_post = f"{post.title} {post.selftext}" if not filtre_titre_seulement else post.title
if est_en_francais(contenu_post):
post_data = {
'titre': post.title,
'auteur': str(post.author),
'score': post.score,
'permalink': f"https://www.reddit.com{post.permalink}",
'subreddit': post.subreddit.display_name,
'corps': post.selftext,
'date': datetime.utcfromtimestamp(post.created_utc),
'commentaires': []
}
try:
post.comments.replace_more(limit=0)
for commentaire in post.comments.list():
if commentaire.body and est_en_francais(commentaire.body):
post_data['commentaires'].append({
'auteur': str(commentaire.author),
'texte': commentaire.body
})
total_commentaires += 1
except Exception as e:
post_data['commentaires'].append({
'auteur': 'erreur',
'texte': f"[Erreur de lecture des commentaires] : {e}"
})
resultats.append(post_data)
return resultats, total_commentaires
# Génération du fichier texte complet
def generer_fichier_txt(resultats):
contenu = ""
for post in resultats:
contenu += f"=== POST : {post['titre']} ===\n"
contenu += f"Auteur : {post['auteur']} | Score : {post['score']} | Subreddit : {post['subreddit']}\n"
contenu += f"Lien Reddit : {post['permalink']}\n"
contenu += f"Date : {post['date']}\n\n"
contenu += f"{post['corps']}\n\n"
contenu += "--- Commentaires ---\n"
for com in post['commentaires']:
contenu += f"*{com['auteur']} : {com['texte']}\n"
contenu += "\n===============================\n\n"
return contenu
# Interface utilisateur Streamlit
st.title("Scraper Reddit : posts et commentaires en français")
st.markdown("www.codeandcortex.fr")
st.markdown("Identifiants API Reddit")
client_id = st.text_input("Client ID", type="password")
client_secret = st.text_input("Client Secret", type="password")
user_agent = st.text_input("User Agent", value="api_streamlit/1.0 (by u/Accurate-Command-285)") # a remplacer par le nom de votre api et le nom de votre compte
st.markdown("Paramètres de recherche")
mot_cle = st.text_input("Mot-clé à rechercher", value="Exemple : Trump")
date_debut = st.date_input("Date de début (UTC)", value=datetime(2024, 1, 1))
filtre_titre = st.checkbox("Rechercher uniquement dans le titre")
# Lancement de la recherche
if st.button("Lancer la recherche"):
if not all([client_id, client_secret, user_agent, mot_cle]):
st.warning("Merci de remplir tous les champs.")
else:
try:
date_timestamp = date_to_timestamp(date_debut)
with st.spinner("Recherche en cours..."):
resultats, total_commentaires = rechercher_posts_depuis_date(
mot_cle, client_id, client_secret, user_agent, date_timestamp, filtre_titre
)
if resultats:
st.session_state["resultats"] = resultats
st.session_state["contenu_txt"] = generer_fichier_txt(resultats)
st.session_state["total_commentaires"] = total_commentaires
st.session_state["recherche_effectuee"] = True
else:
st.warning("Aucun post trouvé pour ce mot-clé et cette date.")
except Exception as e:
st.error(f"Erreur : {e}")
# Affichage des résultats après recherche
if st.session_state.get("recherche_effectuee"):
resultats = st.session_state["resultats"]
total_commentaires = st.session_state["total_commentaires"]
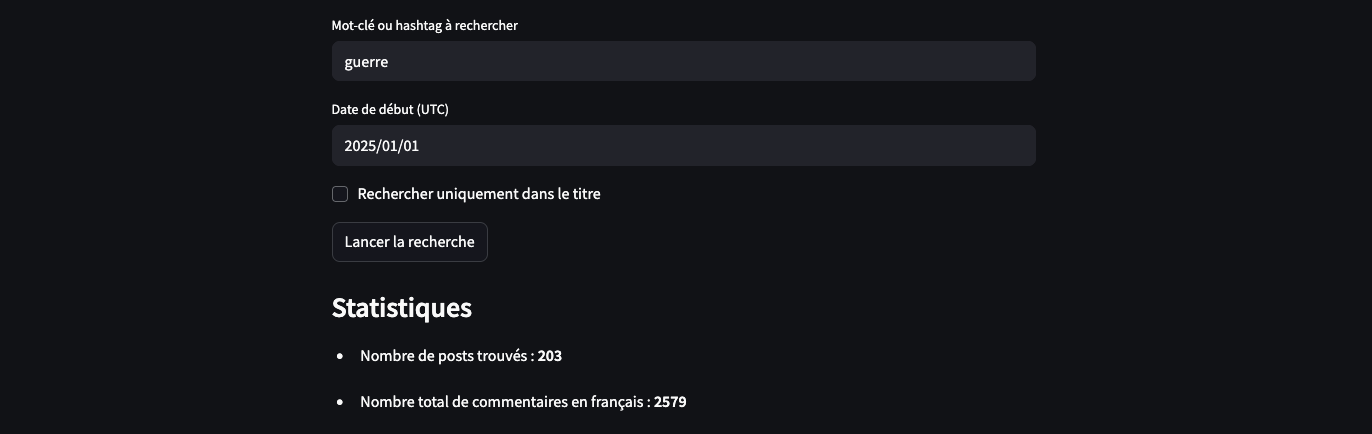
st.subheader("Statistiques")
st.markdown(f"Nombre de posts trouvés : **{len(resultats)}**")
st.markdown(f"Nombre total de commentaires en français : **{total_commentaires}**")
for i, post in enumerate(resultats[:2], start=1):
st.markdown(f"### Post {i}")
st.markdown(f"**{post['titre']}**")
st.markdown(f"Auteur : {post['auteur']} | Score : {post['score']}")
st.markdown(f"Subreddit : {post['subreddit']} | Date : {post['date']}")
st.markdown(f"[Lien vers le post Reddit]({post['permalink']})")
extrait = post['corps'][:500] + ("..." if len(post['corps']) > 500 else "")
if extrait:
st.markdown(f"Extrait : {extrait}")
st.markdown("5 premiers commentaires en français :")
for com in post['commentaires'][:5]:
st.markdown(f"*{com['auteur']}* : {com['texte']}")
st.download_button(
label="Télécharger tous les résultats (.txt)",
data=st.session_state["contenu_txt"],
file_name="reddit_resultats.txt",
mime="text/plain"
)