ORANGE DATA MINING est un logiciel libre et gratuit dédié à l’analyse de données et au text mining.
Il se distingue par son interface simple et visuelle qui repose sur un système de widgets qu’il suffit de glisser / déposer et paramétrer pour construire un flux de traitement.
Cette approche modulaire permet de construire un workflow/pipeline sans avoir à écrire du code Python.
Chaque noeud (widget) peut effectuer une tâche spécifique, allant de la lecture de données à partir d’un fichier csv, texte, copier/coller…, à la normalisation (vue ici dans un précédent article) de ces données puis au traitement statistique.
Sur ces pages vous trouverez des exemples de workflow.

Toutefois, vous ne trouverez pas dans Orange Data Mining de widget permettant de réaliser une AFC, et encore moins un CHD (méthode Reinert), qui restent des approches largement utilisées dans le monde universitaire en sciences sociales.
En revanche, Orange met à disposition tout l’arsenal des algorithmes employés dans le domaine du Deep Learning. On y retrouve notamment des tests comme LDA, K-means, t-SNE, …
A noter que le logiciel KNIME est similaire à Orange Data Mining est semble plus puissant.
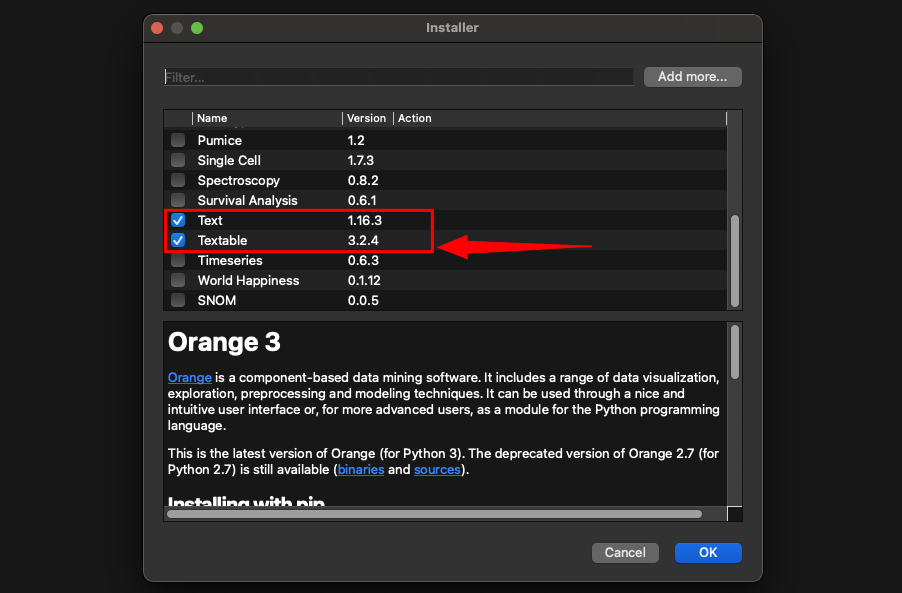
Dans cet article, nous allons nous concentrer sur le module de prétraitement, adapté aux données textuelles (La doc du widget ICI).
Avant toute chose vous devez installer ce module (barre du haut => Add-on => “textable”) :
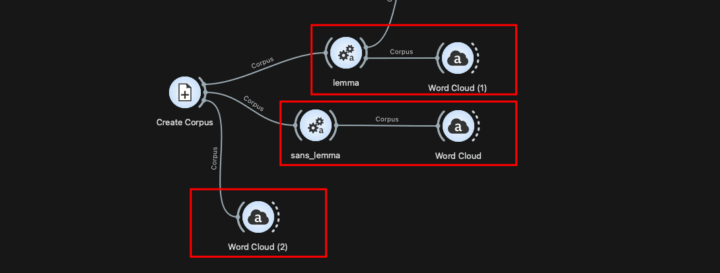
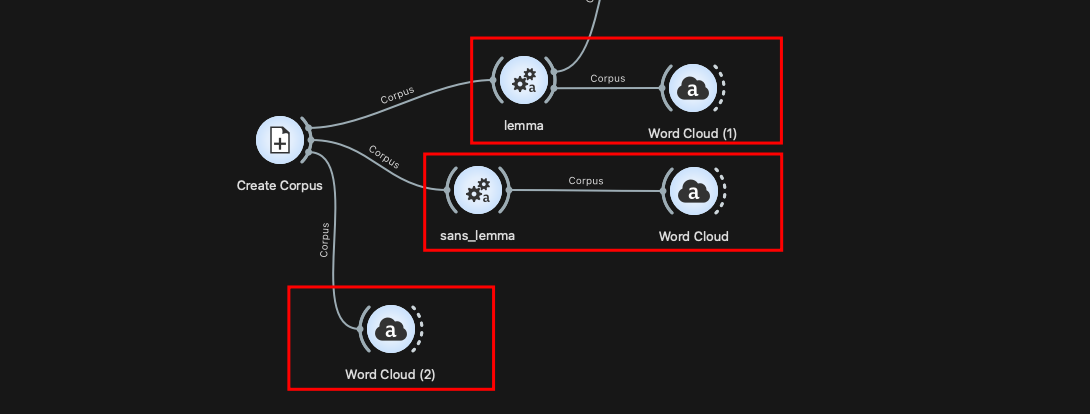
Le widget “Preprocess text“ permet de définir les règles de transformation et de normalisation appliquées à un corpus.
Avant d’y recourir, il faut au préalable créer un corpus de textes, puis appeler le widget “Preprocess text” pour choisir et paramétrer les opérations de nettoyage, de normalisation ou encore de filtrage.

Dans le module/widget “preprocess text” de Orange Data Mining vous retrouverez sur votre gauche de l’écran (un peu caché) les onglets de paramètres.
1. Onglet : Transformation
Ici on retrouve :
- Lowecase : Transformation en minuscules du texte
- Remove accents : Élimine les accents du texte.
- Parse html : Analyse des balises html contenant du texte.
- Remove urls : Supprime les URL supprimera les URL du texte.
![]()
2. Onglet : Tokenisation
Ici, cela diffère un peu en termes de définition par rapport aux scripts python de normalisation que nous avons vu. Tokeniser un texte signifie le diviser en unités plus petites, appelées tokens.
Ces tokens peuvent être des mots, des phrases, ou d’autres éléments significatifs du texte et Orange vous laisse le choix entre plusieurs options.

2.1 Word ponctuation – Mot et ponctuation
Ce type de tokenisation découpe le texte en mots tout en conservant la ponctuation comme des tokens séparés. Par exemple, chaque mot ainsi que chaque symbole de ponctuation (virgule, point, parenthèses, etc.) sera un token distinct.
Exemple : “Ceci est un exemple.”
Après tokenisation :
‘Ceci’, ‘est’, ‘un’, ‘exemple’, ‘.’
Les mots sont séparés par des espaces et chaque signe de ponctuation (virgule, point, parenthèses, etc…) est aussi traité comme un token.
2.2 Whitespace (Espace (vide/blanc)
Ici, la tokenisation se fait uniquement sur la base des espaces. Chaque séquence de caractères séparée par un espace sera traitée comme un token, mais les signes de ponctuation sont ignorés.
Exemple : “Ceci est un exemple.”
Après tokenisation :
‘Ceci’, ‘est’, ‘un’, ‘exemple’ (sans le point)
Les espaces vides servent à séparer les tokens, mais les signes de ponctuation ne sont pas extraits.
2.3 Sentence (Phrase)
Cette méthode décompose le texte en phrases complètes. La tokenisation s’arrête à chaque ponctuation qui marque la fin d’une phrase (par exemple, les points, points d’exclamation, etc…). Chaque phrase devient un token.
Exemple : “Ceci est un exemple. Un autre exemple.”
Après tokenisation :
‘Ceci est un exemple.’, ‘Un autre exemple.’
Le texte est divisé en phrases complètes.
2.4 RegExp (Regular Expression)
Si vous cochez cette option, Par défaut, la séparation du texte en mots se fait à l’aide de la règle \w+, qui correspond à toute séquence de caractères alphanumériques (lettres, chiffres, soulignés).
Autrement dit, cette règle identifie les « mots » du texte. Il ne faut pas confondre cette option qui se situe dans l’onglet Tokenisation et l’option Regex dans l’onglet Filtering.

Voici à quoi ce la correspond quand on test l’expression dans l’interface du site https://regex101.com.
Les expressions surlignées en bleu sont conservées/détectées et tokenisées.

3. Onglet : filtering
3.1 Stopwords (Mots vides)
L’étape incontournable… Les stopwords sont des mots courants dans une langue, mais qui n’apportent pas d’information pour l’analyse.
Ce sont généralement des mots comme “et”, “le”, “dans”, “si”, “à”, … Ces mots sont souvent éliminés lors du prétraitement du texte.
Option : “Stopwords” : Lorsque vous activez cette option, vous éliminez les mots vides de votre texte.
Vous pouvez sélectionner un fichier externe contenant une liste de stopwords personnalisée (par exemple un fichier .txt avec un mot par ligne.).
Exemple : “Le chat est dans le jardin.”
Après filtrage des stopwords : “chat jardin”
3.2 Lexicon (Lexique)
Le “lexique” vous permet de filtrer le texte pour ne conserver que les mots présents dans un fichier spécifique (dictionnaire). Vous devrez charger un fichier .txt qui contient un mot par ligne.
Seuls les mots présents dans ce fichier seront conservés dans le texte.
Cela peut être utile si vous voulez travailler avec un vocabulaire spécifique (par exemple, des mots du domaine domaine médical).
3.3 Les règles personnalisées : Regex
L’Expression (regex) est un “motif” de recherche que l’on applique pour extraire des chaînes spécifiques.
Par défaut l’interface propose le mode reg/w+ qui correspond à la méthode d’extraction des tokens la plus souvent utilisée.
Mais dans l’onglet “Filtering” vous pouvez adapter/créer vos règles.

L’option Regexp permet donc de définir une expression régulière personnalisée.
Par défaut, cet onglet est configuré pour SUPPRIMER une liste de ponctuations et symboles spéciaux, mais vous pouvez personnaliser l’expression régulière selon vos besoins.
r'\.|,|:|;|!|\?|\(|\)|\||\+|\'|\"|‘|’|“|”|\'|\’|…|\-|–|—|\$|&|\*|>|<|\/|\[|\]'
Voici le détail :
\.→ le point.,→ la virgule: ;→ deux-points et point-virgule! \?→ point d’exclamation et point d’interrogation\(|\)→ parenthèses ouvrante et fermante\|→ la barre verticale|\+→ le signe plus+\'|\"→ l’apostrophe'et les guillemets"‘|’|“|”|\'|\’→ différentes variantes d’apostrophes et de guillemets…→ les points de suspension\-|–|—→ tiret simple, tiret demi-cadratin et tiret cadratin\$→ le signe dollar&→ l’esperluette&\*→ l’astérisque*>|<→ les chevrons>et<\/→ la barre oblique/\[|\]→ crochets[et]
Vous remarquerez que dans la liste des caractères, certains sont précédés d’un antislash \.
En expressions régulières (ReGex), ce préfixe est nécessaire lorsqu’un caractère possède une fonction particulière (par exemple ., ?, +, *, |, (), [], {}, $, ^). L’antislash permet alors d’indiquer que l’on souhaite traiter ce caractère au sens ordinaire, et non comme un opérateur.
En revanche, il n’est pas nécessaire d’échapper les caractères « ordinaires », tels que les lettres, les chiffres ou certaines ponctuations simples (comme ,, :, ;, !).
3.4 Onglet Filtering (Filtrage des mots)
Le filtrage par “Document Frequency” permet de garder uniquement les mots qui apparaissent dans un certain nombre ou pourcentage de documents.
Le filtre “Document Frequency” permet de repérer et conserver uniquement les mots qui apparaissent dans un certain nombre ou pourcentage de ces documents.

Imaginons que vous travaillez sur un corpus de 20 articles de presse consacrés aux enjeux environnementaux.
- Certains mots comme “climat, transition ou énergie” apparaissent dans presque tous les articles. Ils sont trop fréquents et n’apportent pas d’information discriminante.
- D’autres termes comme “biodiversité, sécheresse ou pesticides” apparaissent dans quelques articles seulement. Ils sont (plus) intéressants car ils permettent de différencier certains textes des autres.
- Enfin, des mots très spécifiques comme “Loi_Grenelle_II” n’apparaissent que dans un seul article : ils sont trop rares pour être utiles dans une analyse globale.
Grâce au filtrage par “Document Frequency” :
- En fréquence absolue, vous pourriez décider de garder uniquement les mots présents dans au moins 3 articles mais dans au plus 15 articles.
- En fréquence relative, vous pourriez définir un seuil de 20 % à 70 % des documents.
Bon… personnellement, je n’ai pas utilisé cette option, car elle va quelque peu à l’encontre de deux principes.
D’une part, il s’agit de respecter la complexité issue d’un entretien clinique, que l’on cherche généralement à analyser sans opérer de censure sur les données.
Si l’on s’est appliqué à retranscrire fidèlement ce que l’enquêté a déclaré, ce n’est pas pour ensuite supprimer du contenu avant un traitement statistique.
D’autre part, l’utilité de ce type de filtrage reste limitée à des analyses descriptives. En aucun cas un tel prétraitement ne me paraît pertinent pour une analyse de type CHD (Classification Hiérarchique Descendante), par exemple.
3.5 “Most Frequent Tokens” (Les tokens les plus fréquents)
Le filtrage par tokens les plus fréquents vous permet de ne garder que les mots les plus fréquents dans l’ensemble du texte ou du corpus.
Par défaut, le script garde les 100 mots les plus fréquents, ça me semble intéressant dans le cadre de la génération d’un nuage de mots.
3.6 Filtrage par POS Tag (Part-of-Speech Tagging)
Cette option permet de conserver uniquement certains types de mots en fonction de leur catégorie grammaticale (part-of-speech), identifiée automatiquement par le logiciel.
Le POS tagging est une opération qui consiste à attribuer à chaque mot de votre corpus une étiquette grammaticale (nom, verbe, adjectif, adverbe, …).

Par défaut, si “POS tags” est coché, Orange applique un filtrage qui conserve deux catégories de mots : les noms (noun) et les verbes (verb).
Orange s’appuie principalement sur les outils suivants pour l’étiquetage grammatical :
- Averaged Perceptron Tagger de NLTK, développé par Matthew Honnibal (en regardant la doc de NLTK, je ne retrouve pas le même libellé des étiquettes…)
- Treebank POS Tagger (MaxEnt) basé sur un modèle du Penn Treebank

Je n’ai pas trouvé dans la littérature les autres étiquettes grammaticale sur lesquelles l’algorithme se base.
Ce type de filtrage est utile si l’on souhaite réduire le bruit introduit par des mots jugés moins informatifs dans certaines analyses.
4. Onglet : N-grams Range
Dans le module Preprocess Text d’Orange, l’option N-grams Range permet de générer des séquences de mots appelées n-grams.
Un n-gramme se définit comme une séquence contiguë de n tokens, construite en respectant l’ordre du texte, ce qui signifie que l’ordre des mots est toujours préservé.
On les construit généralement à l’intérieur d’une unité de contexte, le plus souvent une phrase, mais l’algorithme ne retient que les suites de mots adjacents.
L’interface permet de définir une plage dans laquelle n varie.
Par exemple, une plage de (1, 2) signifie que l’on génère des unigrams (séquences d’un mot) et des bigrams (séquences de deux mots).
Si vous définissez la plage (1, 2) sur le texte suivant :
« Le chat mange des souris. »
- Unigrams (1-grams) :
Le,chat,mange,des,souris - Bigrams (2-grams) :
Le chat,chat mange,mange des,des souris
Cette approche permet de capturer les petites expressions figées ou associations fréquentes de deux mots.

Différence avec la notion de co-occurrence :
