
Le script présenté ici diffère d’une analyse “classique” de cooccurrences centrée sur un mot pivot.
No Code : https://cooccurrences-arbrecomplet.streamlit.app/
Lorsque vous vous connectez à Streamlit Cloud, l’application est (souvent) en veille : il faut la réactiver, ce qui peut prendre une trentaine de secondes…
Au lieu de partir d’un terme choisi à l’avance et d’observer ses associations dans le texte, l’approche retenue est globale : elle prend en compte l’ensemble des cooccurrences présentes dans le corpus.
1. Définir une “fenêtre”
Il reste (toujours) nécessaire de définir une fenêtre de cooccurrence. Pour mémo, la fenêtre de contexte est l’unité dans laquelle on cherche les cooccurrences.
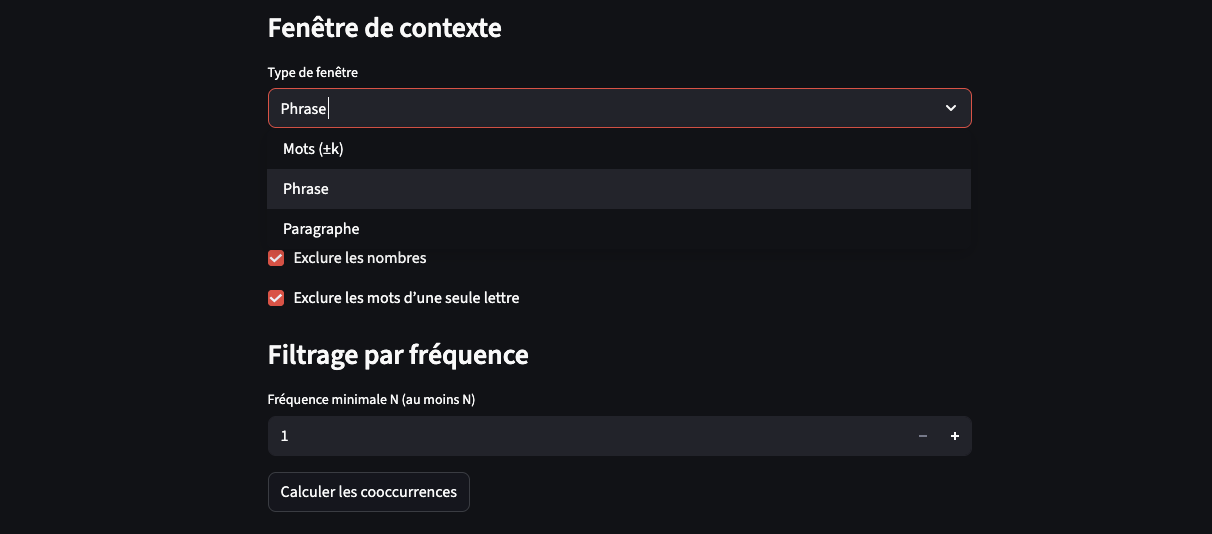
Ici vous retrouvez donc les mêmes fenêtres que dans le précédent script (cooccurrences – mot pivot), trois choix existent et donnent trois découpages des textes : “Mots (±k)” (fenêtre glissante de k mots autour de chaque position), “Phrase” (détection des phrases à partir de la ponctuation) et “Paragraphe” (blocs séparés par une ligne vide).
Attention ! Concernant la règle de détection de la fenêtre “phrase” qui est basée sur la ponctuation. Seul les caractères suivants sont pris en compte : [".", "!", "?", "…"]
# ================================
# IMPORTANT !
# ================================
# fenetre phrase : sentencizer - règle-basée qui PREND LA MAIN sur doc.sents
# Par défaut spaCy coupe sur ".", "!", "?" ; on ajoute "…" et on force le remplacement.
# ==== Sentencizer pour garantir doc.sents ====
if "senter" not in nlp.pipe_names and "sentencizer" not in nlp.pipe_names:
nlp.add_pipe("sentencizer", config={"punct_chars": [".", "!", "?", "…"]})
Deux mots cooccurrent s’ils apparaissent ensemble dans au moins une même fenêtre.
La fréquence de cooccurrence correspond au nombre de fenêtres dans lesquelles la paire de mots (a, b) est présente.
2. Upload des textes
L’interface Streamlit permet d’intégrer plusieurs textes dans une même analyse.
Cela offre la possibilité d’explorer les cooccurrences entre différents documents.
À ce stade, le script a été testé sur deux articles de presse issus de EuroPresse. La robustesse face à un très gros volume de données n’a pas encore été éprouvée… notamment avec l’application sur streamlitcloud (https://cooccurrences-arbrecomplet.streamlit.app/)
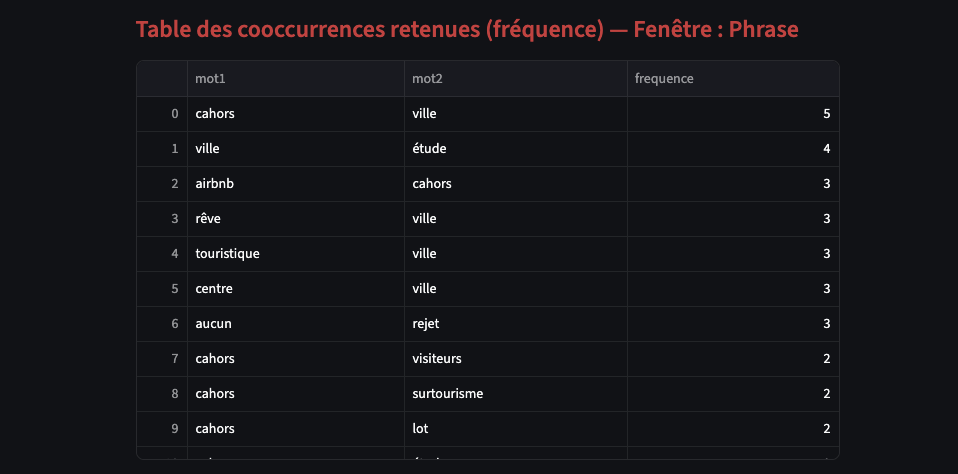
1. Analyse des cooccurrences à partir de la fréquence
Le filtrage par fréquence (seuil N à définir) permet de conserver uniquement les paires de mots (a,b) ≥ N

Ainsi les tableaux, graphes, concordanciers s’appliquent ensuite à ce paramètre.
1.1 Nuage de Mots
Dans le nuage de mots des cooccurrences, la taille est proportionnelle à la fréquence brute de chaque paire (mot1_mot2).

1.2 Représentation en réseau (Librairie python : Pyvis)
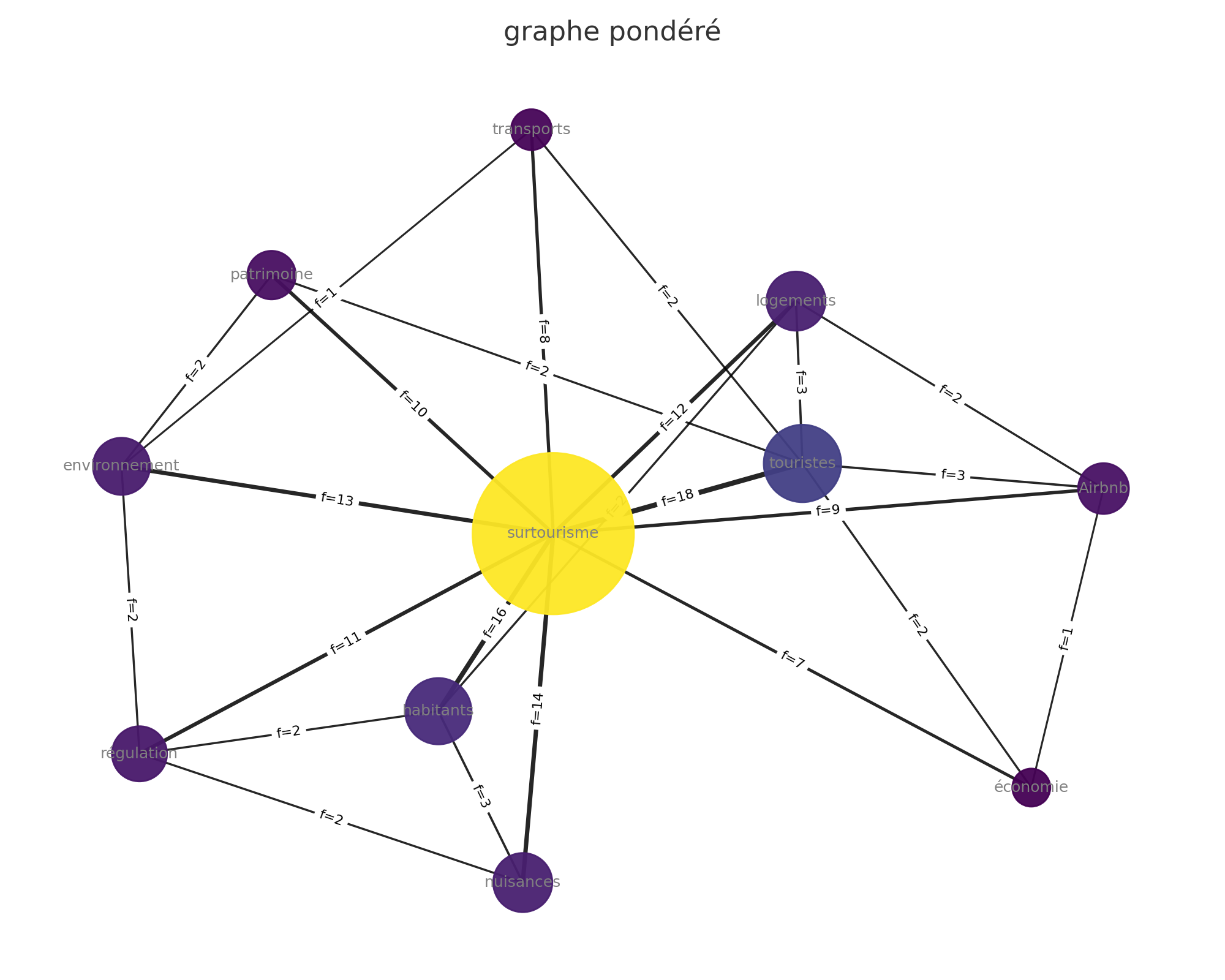
Ici nous évoquons la notion de représentation et non de calcul des cooccurrence. Le graphe Pyvis est calculé à partir des fréquences et d’une pondération.
Dans ce cas, les arêtes reliant deux mots sont proportionnelles au nombre de fois où ils apparaissent ensemble dans la fenêtre.
Ainsi, pour chaque co-apparition ajoute “+1” au lien entre ces deux mots ; le total obtenu est le poids de l’arête.
Vous pouvez faire varier le “seuil N” afin de ne conserver que les paires apparaissant au moins N fois, en fonction de la densité de votre corpus.
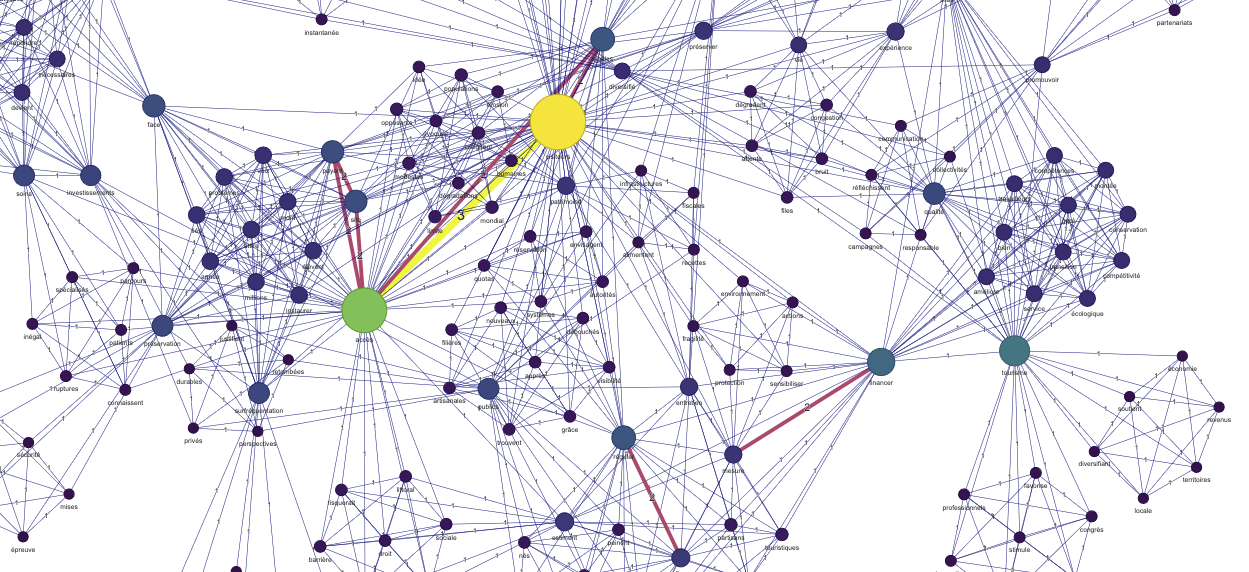
De plus, le degré pondéré d’un nœud est la somme des fréquences de toutes les cooccurrences qui le relient à d’autres mots. Autrement dit : plus un mot apparaît souvent en cooccurrence avec beaucoup d’autres, plus sa “bulle” sur le graphique est grosse.
La pondération d’un noeud “n” est donc obtenue en additionnant toutes les fréquences des cooccurrences entre ce noeud et chacun de ses voisins “v”.
- n : le noeud du graphe, c’est-à-dire un mot du corpus
- v : un voisin de “n”, donc un mot qui est relié à “n” par une arête (parce qu’ils apparaissent en cooccurrence dans une même fenêtre).
- f(n,v) : la fréquence de cooccurrence entre “n” et “v”, c’est-à-dire le nombre de fois où les deux mots apparaissent ensemble dans la fenêtre.
![\[ \text{Pondération}(n) = \sum_{\text{voisin } v} f(n,v) \]](https://www.codeandcortex.fr/wp-content/ql-cache/quicklatex.com-896c1a4b778973475d85d35672d37909_l3.png "Rendered by QuickLaTeX.com")
Prenons l’exemple (cf graphique plus bas) de la pondération du mot « surtourisme » = touristes (f18) + logements (f12) + Airbnb (f9) + nuisances (f14) + habitants (f16) + régulation (f11) + environnement (f13) + transports (f8) + patrimoine (f10) + économie (f7) = 118
Cette pondération permet de distinguer non seulement qui est connecté à qui (simple graphe), mais aussi quelle est l’intensité de ces connexions.
Dans ce cadre, on peut parler de “saillance” dans le sens où, dans le graphe pondéré, un mot avec un degré pondéré élevé (somme des fréquences de toutes ses cooccurrences).
Cette “saillance” est avant tout “relationnelle” : elle signale une forte intensité de co-présence avec d’autres termes.
Cependant, cette “saillance” pondérée ne dit pas tout de la structure : un mot peut être très « lourd » mais surtout connecté à un petit voisinage, tandis qu’un autre, plus léger, relie des communautés différentes.
Dans votre graph, si vous repérez trop “d’îlots” (noeuds non reliés), il est possible que le seuil N soit trop restrictif : essayez de l’abaisser.
Dans le cas du graphe basé sur le log-likelihood, vous devrez agir sur le filtre du test.
2. Analyse avec log-likelihood
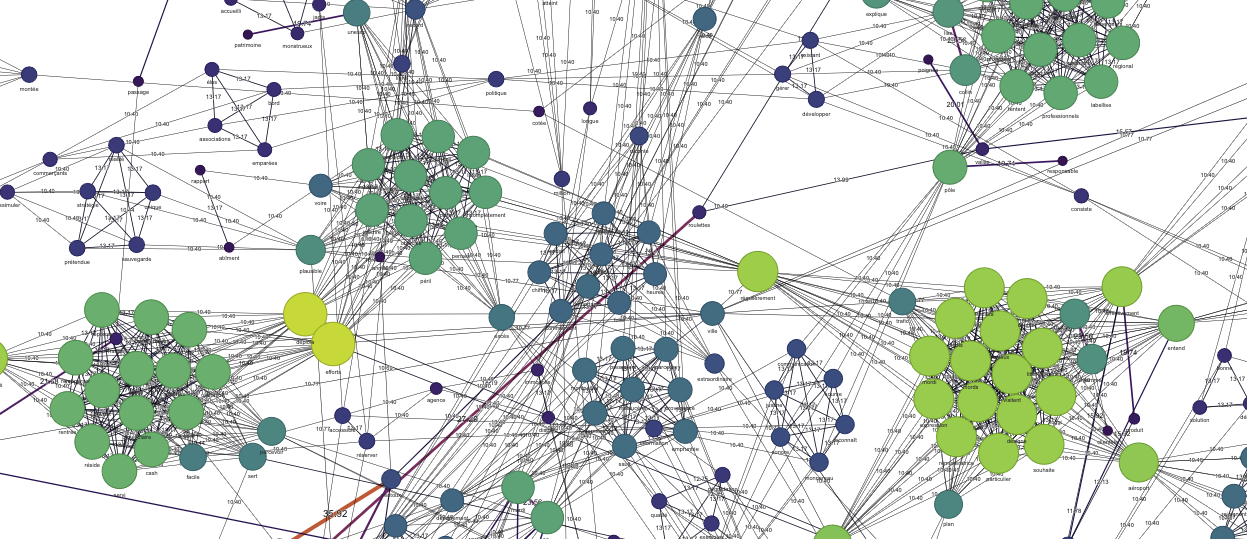
Le graphe Pyvis basé sur le log-likelihood fonctionne différemment : ici, les nœuds ne sont pas pondérés directement par leur fréquence individuelle mais par le score du test de log-likelihood pour chaque paires de mots.
Cette approche révèle les relations significatives plutôt que les simples mots fréquents.
2.1 Nuage de Mots
Comme pour l’analyse en fréquence, la taille du nuage de mots “log-likelihood” est pondérée par le score du log-likelihood.

2.2 Représentation en réseau
La lisibilité du graph avec le log-likelihood est plus “opaque”.
Les résultats produits avec la bibliothèque Pyvis relèvent d’un choix : les graphes sont esthétiques, mais pas toujours très lisibles…
On aurait put envisager de filtrer le graphe selon la valeur p ; c’est en cours de test. Toutefois, selon les corpus, on n’obtient pas toujours une valeur p significative au seuil de 0,05.
Petite astuce : télécharger le graphe au format HTML aide grandement à la lecture (zoom possible et affichage plus grand) des informations ; l’affichage dans Streamlit est nettement moins confortable…
3. Concordancier
Le concordancier reconstruit les segments de texte où les deux mots d’une paire apparaissent dans la même fenêtre, avec surlignage des deux termes.
