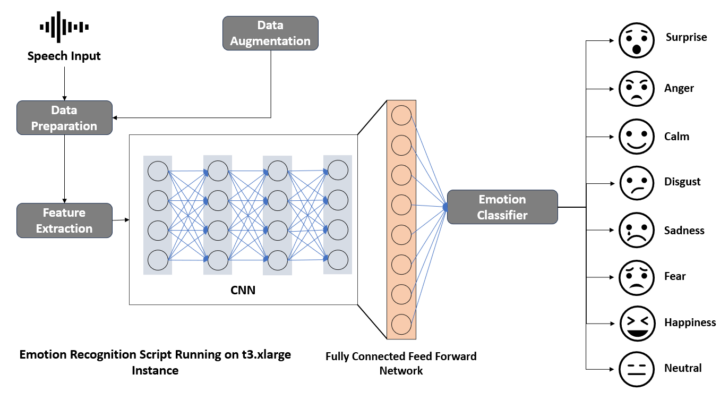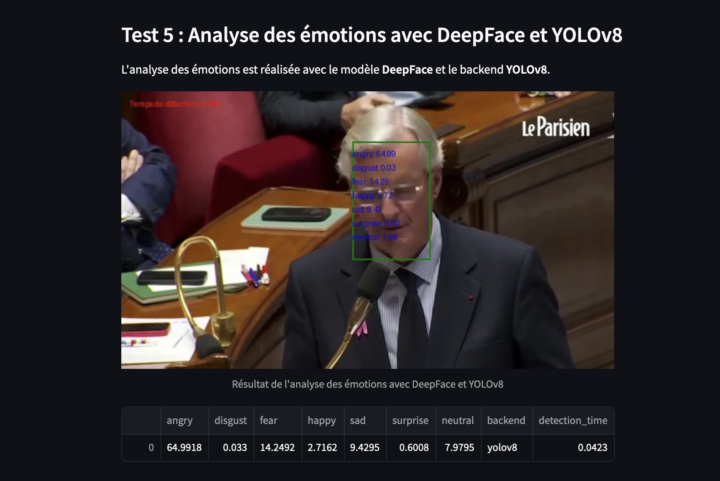
Dans le cadre de l’analyse multimodale en Sciences Humaines et Sociales, ce script Python propose une méthode pour transformer une vidéo (YouTube ou en local .mp4) en stop motion (animation image par image). Que ce soit depuis un lien YouTube ou un fichier vidéo local au format .mp4, l’utilisateur peut générer une nouvelle version de la vidéo où les images sont extraites à une fréquence...