Avant tout, ce script constitue une approche quantitative pour mesurer la popularité d’une vidéo ciblée sur une chaîne YouTube donnée. Il s’appuie sur trois indicateurs principaux : le nombre de vues, de likes et de commentaires.
L’objectif n’est pas d’apporter une mesure définitive ou automatisée des anomalies, mais plutôt d’offrir un cadre d’observation, permettant par exemple de repérer des comportements suspects, comme l’achat de vues, de likes ou de commentaires, visant à artificiellement booster la visibilité d’une vidéo.
Comme l’illustre très bien un documentaire diffusé sur la chaîne ARTE, ces pratiques sont répandues sur l’ensemble des réseaux sociaux. Même si les plateformes mettent en œuvre des algorithmes de détection des bots, ces derniers sont aujourd’hui extrêmement sophistiqués, capables de contourner le blacklistage des systèmes de modération automatique.
Il ne s’agit donc pas nécessairement ici d’une désinformation dans le contenu (même si cela peut aussi exister), mais plutôt d’une fabrique de visibilité de e-popularité, d’une forme de réalité numérique construite. Ces stratégies participent à ce que je qualifierais de “moi numérique” : un espace où les auteur(e)s utilisent les réseaux sociaux comme un terrain de je(u), pour y façonner une identité différente à leur identité civile ou administrative.
1. Quelques précisions techniques
Ici, nous n’aborderons pas l’analyse des commentaires en tant que contenu. L’approche est uniquement quantitative.
Le script se concentre sur le suivi d’une seule vidéo YouTube. Les données sont accessibles via une interface Streamlit, et pour que cela fonctionne, vous devez disposer d’une clé API YouTube Data.
Les statistiques (vues, likes, commentaires) sont enregistrées quotidiennement grâce à une tâche CRON que vous devrez configurer sur votre machine à partir de votre Terminal (1 ligne de code).
Il est important de préciser que le script ne permet pas de reconstruire l’historique d’une vidéo : vous ne pouvez collecter les données qu’à partir du moment où vous commencez le suivi.
Pour accéder à l’historique complet, il faudrait être propriétaire de la chaîne YouTube. Pour palier à ce probleme vous avez deux solutions simples : effectuer une surveillance continue via un flux RSS ou utiliser les alertes YouTube, dans ce second cas vous devrez vous abonner à la chaîne cibles pour être informé rapidement de la publication d’une nouvelle vidéo.
Le script repose uniquement sur des outils gratuits et open source. Il existe bien sûr des plateformes de scraping payantes qui proposent des services équivalents.
2. Structure des fichiers
Voici les fichiers nécessaires au bon fonctionnement du script qui sont au nombre de 4 (à placer bien entendu dans le même répertoire de travail) :
2.1 main.py
C’est le script principal de l’application, il contient :
- L’interface Streamlit
- La connexion à la base de données SQLite
- L’interrogation de l’API YouTube (keys.toml)
- La sauvegarde et la visualisation des données
# pip install streamlit pandas google-api-python-client XlsxWriter altair
# pip install google-auth-oauthlib
# python -m streamlit run main.py
"""
main.py — YouTube Data v3 • Graph journalier + Deltas
=========================================================================
Affiche, pour chaque jour, le cumul quotidien de vues, likes et commentaires
sous forme de barres, et conserve les deltas
(journaliers) dans la DataFrame/Tableau et le fichier Excel.
"""
import os
import io
import sqlite3
import toml
import pandas as pd
import streamlit as st
import altair as alt
from datetime import datetime
from googleapiclient.discovery import build
# Forcer le répertoire courant (cron)
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# Configuration Streamlit (centrée)
st.set_page_config(page_title='YT v3 • graph journalier', layout='centered')
st.title('YouTube – nbre vues - likes - commentaires')
# Charger les secrets
cfg = toml.load('keys.toml')
CHEMIN_BDD = os.path.abspath(cfg['sqlite']['chemin'])
CLE_API = cfg['youtube']['api_key']
ID_VIDEO = cfg['youtube']['video_id']
# Initialisation SQLite
@st.cache_resource
def init_bdd():
os.makedirs(os.path.dirname(CHEMIN_BDD) or '.', exist_ok=True)
conn = sqlite3.connect(CHEMIN_BDD, check_same_thread=False)
conn.execute(
'CREATE TABLE IF NOT EXISTS cumul(ts TEXT PRIMARY KEY, vues INTEGER, likes INTEGER, commentaires INTEGER)'
)
conn.commit()
return conn
conn = init_bdd()
# Récupérer cumul via API
def recuperer_cumul() -> dict:
yt = build('youtube', 'v3', developerKey=CLE_API)
items = yt.videos().list(part='statistics', id=ID_VIDEO).execute().get('items', [])
if not items:
return {}
s = items[0]['statistics']
return {
'ts': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'vues': int(s.get('viewCount', 0)),
'likes': int(s.get('likeCount', 0)),
'commentaires': int(s.get('commentCount', 0))
}
# Enregistrer en base
def enregistrer_cumul(row: dict):
if not row:
return
conn.execute(
'INSERT OR REPLACE INTO cumul(ts,vues,likes,commentaires) VALUES(?,?,?,?)',
(row['ts'], row['vues'], row['likes'], row['commentaires'])
)
conn.commit()
# Construire DataFrame quotidien + delta en pandas
def obtenir_quotidien() -> pd.DataFrame:
q = '''
SELECT date(ts) AS Jour,
MAX(vues) AS vues,
MAX(likes) AS likes,
MAX(commentaires) AS commentaires
FROM cumul
GROUP BY date(ts)
ORDER BY date(ts);
'''
df = pd.read_sql_query(q, conn)
if df.empty:
return df
# convertir en chaîne pour usage en catégorie
df['Jour'] = pd.to_datetime(df['Jour']).dt.strftime('%Y-%m-%d')
# calcul des deltas
for m in ['vues', 'likes', 'commentaires']:
df[f'{m}_delta'] = df[m].diff().fillna(0).astype(int)
return df
# Tracer barres collées
def tracer_barres(df: pd.DataFrame, metric: str, color: str) -> alt.Chart:
return (
alt.Chart(df)
.mark_bar()
.encode(
x=alt.X('Jour:N', title='Date', axis=alt.Axis(labelAngle=-45),
scale=alt.Scale(paddingInner=0, paddingOuter=0)),
y=alt.Y(f'{metric}:Q', title=metric.capitalize()),
color=alt.value(color),
tooltip=[
alt.Tooltip('Jour:N', title='Date'),
alt.Tooltip(f'{metric}:Q', title=metric.capitalize()),
alt.Tooltip(f'{metric}_delta:Q', title=f'{metric} Δ')
]
)
.properties(width={'step': 30}, height=300)
)
# UI: bouton d'enregistrement
if st.button('Synchroniser cumul du jour'):
row = recuperer_cumul()
enregistrer_cumul(row)
if row:
st.success(f"Enregistré {row['ts']}")
# Lecture quotidienne
df = obtenir_quotidien()
if df.empty:
st.info('Aucune donnée.')
st.stop()
# Score du jour
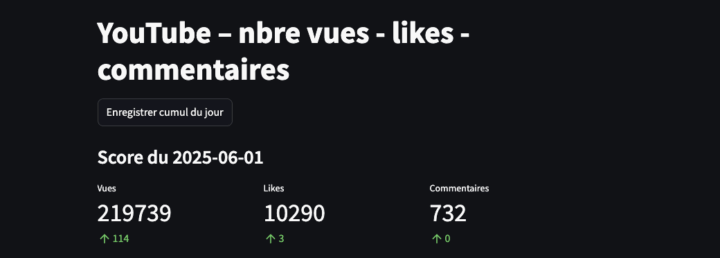
date_last = df['Jour'].iloc[-1]
st.subheader(f"Score du {date_last}")
today = df.iloc[-1]
cols = st.columns(3)
cols[0].metric('Vues', int(today['vues']), int(today['vues_delta']))
cols[1].metric('Likes', int(today['likes']), int(today['likes_delta']))
cols[2].metric('Commentaires', int(today['commentaires']), int(today['commentaires_delta']))
# Tableau
st.subheader('Données quotidiennes')
st.dataframe(df, use_container_width=True)
# Graphiques simples
st.subheader('Vues par jour')
st.write(tracer_barres(df, 'vues', '#1f77b4'))
st.subheader('Likes par jour')
st.write(tracer_barres(df, 'likes', '#ff7f0e'))
st.subheader('Commentaires par jour')
st.write(tracer_barres(df, 'commentaires', '#2ca02c'))
# Export Excel
buf = io.BytesIO()
df.to_excel(buf, index=False, sheet_name='Jour')
buf.seek(0)
st.download_button('Export Excel', buf, 'stats.xlsx', 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet')
2.2 Création de la base SQLite : init_db.py
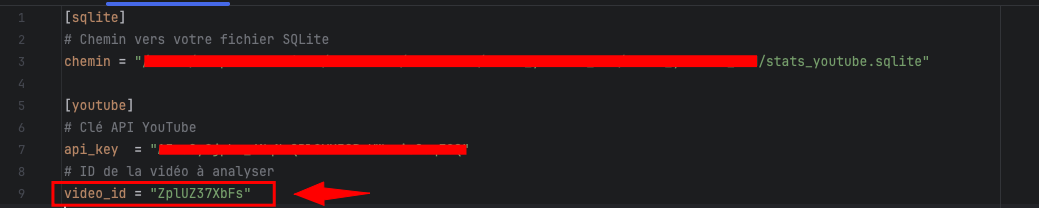
Pour créer la base SQLite vous aurez besoin de créer le fichier keys.toml (en précisant votre clé API YouTube v3, le chemin de votre bdd et l’ID (identifiant)de la vidéo que vous voulez suivre)

Ensuite exécutez le script une première fois (streamlit run main.py), ainsi la base sera créée automatiquement.
SQLite ne nécessite aucun serveur ni configuration complexe : les données sont enregistrées localement dans un fichier .db.
Autrement dit, il n’est pas nécessaire d’ouvrir tous les jours Streamlit pour que la collecte des données fonctionne : la tâche CRON s’exécute en arrière-plan, appelle l’API YouTube, et enregistre les données directement dans la base SQLite.
L’interface Streamlit ne sert qu’à visualiser et analyser ces données a posteriori, quand vous le souhaitez.
Le fichier init_db.py
import sqlite3
CHEMIN_BDD = "Le chemin ciblant le repertoire de votre base de données/stats_youtube.sqlite"
with sqlite3.connect(CHEMIN_BDD) as conn:
cur = conn.cursor()
# Création de la table des commentaires
cur.execute("""
CREATE TABLE IF NOT EXISTS youtube_stats (
date TEXT,
likes_video INTEGER,
vues_video INTEGER,
commentaire TEXT,
auteur TEXT,
UNIQUE(date, commentaire, auteur)
);
""")
# Création de la table de l’historique
cur.execute("""
CREATE TABLE IF NOT EXISTS youtube_historique (
date TEXT PRIMARY KEY,
likes_video INTEGER,
vues_video INTEGER,
nb_commentaires INTEGER
);
""")
conn.commit()
print("Base SQLite initialisée avec succès.")
2.3 Création d’un fichier keys.toml
Le fichier .toml est le fichier de configuration. Il permet de ne pas mélanger le code (dans main.py, cron_yt.py) et les variables sensibles (dans keys.toml
[sqlite] # Chemin vers votre fichier SQLite chemin = "le_chemin_du_repertoire_de_votre_bdd/stats_youtube.sqlite" [youtube] # Clé API YouTube api_key = "votre clé API Youtube" # votre clé API Youtube Data V3 # ID de la vidéo à analyser video_id = "ZplUZ37XbFs" # l'id de votre vidéo à récupérer à partir de l'URL YouTube
2.4 Automatiser avec une tâche CRON
Dans un premier temps, il faut créer un script python qui récupère les données
Créez le fichier : cron_yt.py :
# cron_yt.py
from main import recuperer_cumul, enregistrer_cumul
if __name__ == "__main__":
ligne = recuperer_cumul()
if ligne:
enregistrer_cumul(ligne)
print("Enregistré :", ligne)
Ensuite vous pourrez créer votre tache “cron” dans votre terminal avec l’éditeur NANO (plus convivial).
Dans votre terminal :
EDITOR=nano crontab -e
Rédigez (copiez/collez) la ligne suivante :
59 23 * * * détermine l’heure de l’exécution de la tache, ici 23h59.
59 23 * * * le chemin de votre fichier/cron_yt.py
YouTube ne fournit pas les stats du jour terminé, mais seulement l’état courant au moment de la requête. Si vous interrogez l’API à 6h du matin, vous obtiendrez le total jusqu’à 6h. Il n’y a pas de stats rétroactives par heure/jour via l’API v3.
Si vous voulez vous rapprocher au maximum du bilan réel de la journée, il faut planifier la tâche CRON à une heure proche de 23h59 tous les jours, afin d’obtenir le cumul le plus complet possible de la journée.
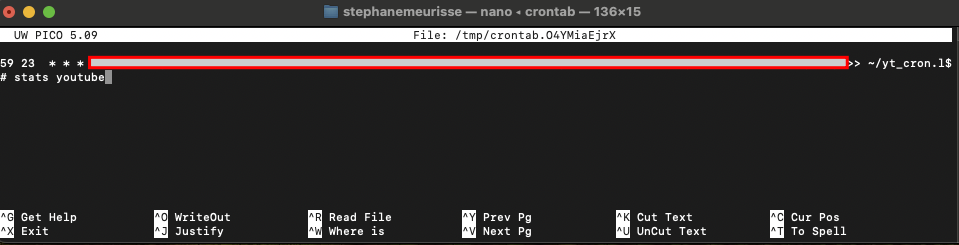
Pour connaitre facilement le chemin de votre fichier cron_yt.py vous pouvez glisser/déposer dans le terminal de votre Mac le fichier depuis son répertoire. Il suffit ensuite de copier le chemin et le coller dans “nano”.
3. Un mot sur les “aberrations” statistiques
Pour illustrer ce projet, j’ai choisi de suivre une vidéo au titre pour le moins accrocheur :
« Je suis passé de 1400€/mois à 100000€/mois : mon histoire en toute INTIMITÉ », mise en ligne le 21 janvier 2024.
Au 1er juin 2025, elle comptabilisait 217 318 vues, soit en l’espace de cinq mois.
Pourtant, à l’observation des données journalières depuis le 24-05-2025 (cf graph), les variations de vues quotidiennes semblent relativement faibles.
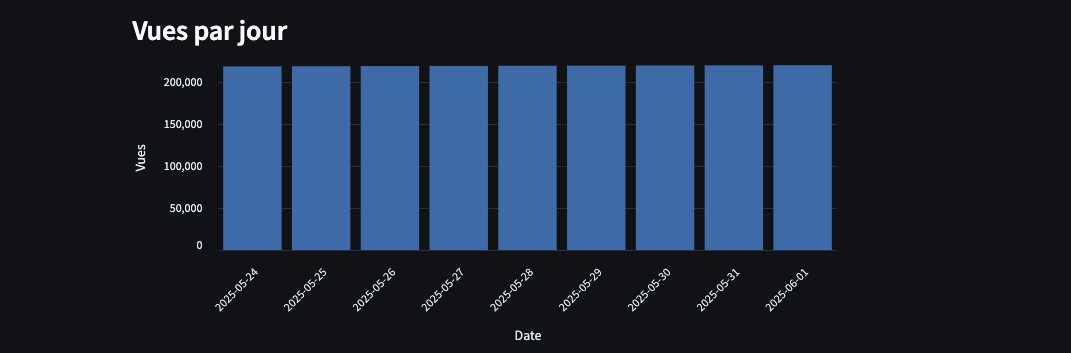
Autrement dit : malgré un nombre de vues global élevé, le rythme quotidien des vues est presque “plat”.
Cet exemple rend difficile la mise en évidence d’éventuelles anomalies ou pics suspects (achats massifs de vues par exemple).
Le premier jour d’observation est le 24-05-2025 ce qui explique les “deltas” avec la valeur “0” pour cette date.
Ainsi l’analyse arrive trop tardivement et il aurait été intéressant de débuter l’observation dès le premier jour de la publication de la vidéo.
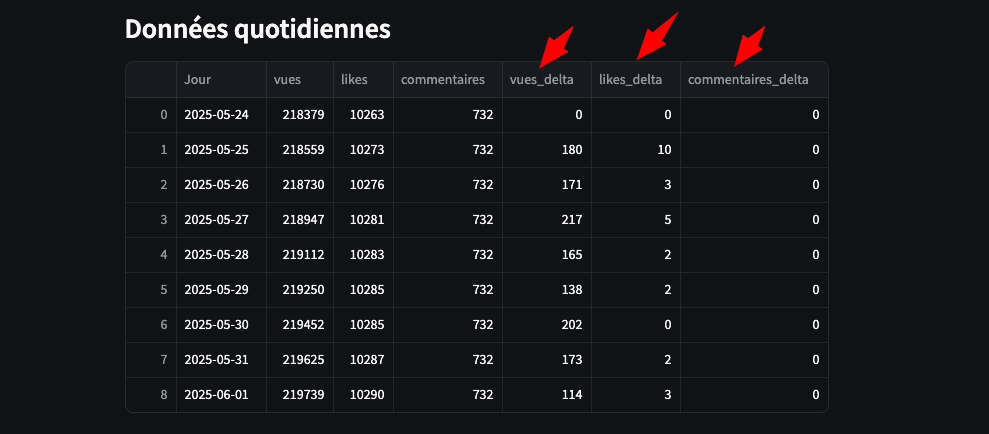
Bref, pas de chance pour une démonstration « sensationnelle » !