

Je préfère prévenir : le script ne fonctionne pas sur Streamlit Cloud, en raison de l’absence de ffmpeg (qui n’est pas une librairie Python) et de la dépendance yt-dl.
En attendant de trouver une solution, vous trouverez le code source disponible sur GitHub. Le script est composé de deux fichiers principaux : main.py et opticalflow.py
1. Application d’opticalflow : Le ralenti image
La méthode du flux optique (opticalflow), développée par Bruce D. Lucas et Takeo Kanade, constitue une avancée majeure dans le domaine de la vision par ordinateur.
À l’origine, cette méthode visait à déterminer les mouvements apparents des objets entre deux images consécutives en calculant les vecteurs de déplacement de chaque pixel. Cette approche, efficace pour identifier la direction et la vitesse des mouvements au sein d’une séquence d’images, a rapidement trouvé une application concrète dans l’univers du montage vidéo.
En effet, divers logiciels de montage exploitent l’algorithme opticaflow pour créer artificiellement des ralentis fluides à partir de vidéos tournées à des fréquences d’images limitées (par exemple, 25 ou 30 images par seconde). Ces logiciels utilisent le flux optique afin de détecter précisément les mouvements et génèrent ainsi automatiquement des images intermédiaires (interpolation d’images). Cette technique permet ainsi d’obtenir des ralentis de qualité, là où une simple duplication d’images donnerait une impression saccadée.
Exemple : imaginons une séquence filmée d’un sportif en plein saut. Avec une caméra standard qui enregistre à 30 images par seconde (fps), le mouvement du sportif sera capturé en seulement 30 images chaque seconde. Ainsi, lors d’un ralentissement, par exemple à 4 fois la vitesse originale (ralenti à 25%), on se retrouve avec seulement 7,5 images par seconde, ce qui crée un effet très saccadé puisque l’œil humain perçoit clairement les espaces manquants entre chaque image.
-
Séquence à 30 fps :
Image 1→Image 2→Image 3→Image 4… (30 images pour 1 seconde) -
Si l’on ralentit par 4 (ralenti à 25%) sans ajout d’images intermédiaires :
Image 1––––Image 2––––Image 3––––Image 4(7,5 images/sec)
→ Dans ce cas, avec 7,5 images/sec, l’œil perçoit clairement un mouvement discontinu comme dans un film de Charlie Chaplin (entre 15 et 20 fps) 😉
Pour obtenir un ralenti parfaitement fluide, on utilise idéalement des caméras filmant à haute vitesse (par exemple, 120 fps ou 240 fps).
Cependant, « l’arme du pauvre » — car il faut bien le dire, les caméras capables de filmer à 240 images par seconde représentent un investissement conséquent ! consiste à utiliser, en post-production, un plugin basé sur l’optical flow (méthode de Lucas-Kanade). Ce plugin permet de fabriquer “artificiellement” les images intermédiaires manquantes. Il calcule les vecteurs de déplacement entre les images existantes et génère ainsi de nouvelles images, simulant un mouvement continu et réaliste.
Bon, si ce n’est pas complètement clair, ce n’est pas très grave ! Entre une caméra RED à 50 000 dollars et un plugin bien utilisé, à part dans les productions cinématographiques haut de gamme, la différence sera à peine perceptible pour la plupart des spectateurs. 😉
2. Analyse des images brutes et segment de texte sur les pic sonore
Je sélectionne une vidéo YouTube dans l’objectif de faire émerger des éléments discriminants au sein de la communication. Ce choix repose entièrement sur une approche subjective et intuitive.
Le script extrait les images brutes aux instants : t−1, t et t+1.
Je regrette un peu ce paramétrage arbitraire, mais une prochaine version du script permettra à l’utilisateur de choisir l’intervalle. Toutefois, après avoir testé un intervalle de t+3 secondes, je constate que cela devient rapidement illisible dans l’interface Streamlit.
À ce niveau, il serait sans doute préférable de reconstruire une micro-vidéo en superposant les images extraites. Ce développement est également en projet.
Attention à l’échelle des plans !
Dans le langage du cinéma, l’échelle des plans désigne le cadrage de l’image. Dans le cadre de ma démarche, il faut reconnaître que lorsqu’un changement de plan intervient, les résultats produits par l’optical flow deviennent nettement moins fiables.
Le calcul du mouvement repose en effet sur la continuité visuelle entre les images ; un changement brutal de cadrage ou de scène perturbe cette continuité et fausse l’analyse du déplacement.
Ces images sont synchronisées sur l’amplitude sonore, selon la méthode détaillée dans un article précédent. Les segments de texte transcrits sont également associés à ces trois intervalles temporels (t−1 t, t+1), cependant la retranscription réalisée avec Whisper semble imprécise, notamment en raison des difficultés rencontrées avec les timestamps générés.



Il serait sans doute pertinent, pour améliorer cette précision, de ne plus raisonner sur les mots ou les segments entiers, mais plutôt sur les tokens, qui pourraient offrir un meilleur alignement temporel.
2. 1 La magnitude optique
La magnitude optique correspond à la longueur des vecteurs obtenus en calculant le flux optique entre deux images successives.
Concrètement, elle représente la vitesse apparente d’un pixel entre ces images : plus la magnitude est grande, plus le pixel s’est déplacé rapidement, et inversement, une faible magnitude indique un mouvement lent ou quasi inexistant.
Ainsi, en visualisant la magnitude optique, on peut facilement identifier quelles parties d’une image bougent rapidement ou lentement, facilitant notamment l’analyse des mouvements dans les vidéos ou la détection des zones d’intérêt en traitement d’image.
2.2 L’analyse HSV
Le modèle HSV (Hue–Saturation–Value) permet de représenter simultanément la direction et l’intensité du mouvement optique de façon visuelle. Concrètement, on calcule pour chaque pixel son vecteur de déplacement, puis on en déduit :
- H (teinte) : l’angle du vecteur, indique la direction du mouvement
- S (saturation) : la norme du vecteur, renseigne sur l’intensité du déplacement à cet endroit
- V (valeur) : pour maximiser la luminosité, met en avant la teinte et la saturation


Ainsi, chaque couleur renvoie à une direction (rouge vers la droite, vert vers le bas, bleu vers la gauche…) et chaque nuance (pastel ou on vif) traduit un mouvement plus ou moins rapide.
- 0° (rouge) → déplacement vers la droite
- 90° (vert) → déplacement vers le bas
- 180° (cyan) → déplacement vers la gauche
- 270° (bleu) → déplacement vers le haut
Par exemple, quand on dit « rouget vers le haut », cela signifie donc que, pour ces pixels, l’algorithme a estimé que le mouvement global se fait vers le haut de l’image.
Plus la couleur “rouge” est saturée, plus ce mouvement est prononcé à cet endroit.
2.2 Superposition
La superposition (image brute + HSV) consiste à fusionner les images de la vidéo originale et sa carte de flux optique pour révéler, en un coup d’œil, non seulement « où » se déplacent les objets, mais aussi « l’intensité » du déplacement.


Ce mélange d’images et de couleurs permet de visualiser les zones et la force des mouvements, sans avoir à interpréter séparément la carte optique et la trame vidéo.
2.3 Les vecteurs de déplacement
Au cœur de l’analyse par flux optique se trouvent les vecteurs de déplacement, qui permettent de représenter le mouvement apparent des pixels entre deux images successives.


Chaque vecteur indique à la fois une direction (vers où le pixel semble se déplacer) et une magnitude (la vitesse ou l’amplitude du déplacement).
En d’autres termes, ces vecteurs traduisent le “chemin” suivi par des éléments visuels d’une image à l’autre.
Lorsqu’ils sont visualisés, ces vecteurs forment un champ de déplacements qui rend visible des micro-mouvements du corps.
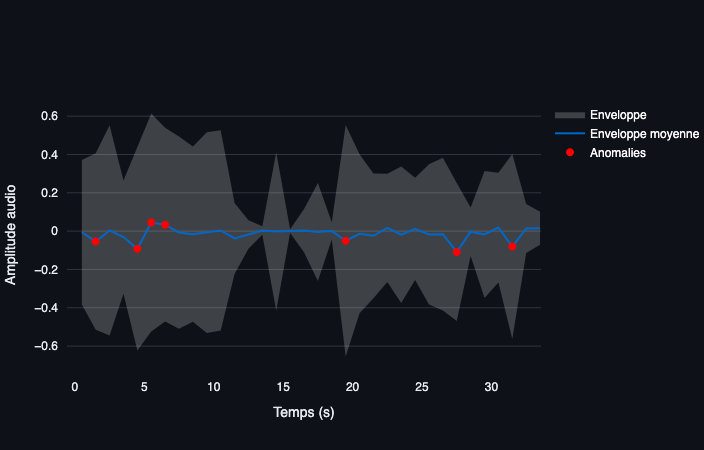
3. Déception autour de la synchronisation audio
En utilisant Whisper, la synchronisation audio autour des instants t−1, t et t+1 s’est révélée plutôt décevante.
J’ai testé de nombreux paramétrages, mais il semble persister un problème lié à la précision des timestamps générés par Whisper.

La retranscription automatique proposée par YouTube n’offre pas de meilleures performances, bien au contraire.
Pour aller plus loin dans l’analyse, j’aurais aimé pouvoir récupérer également le timestamp des commentaires : on se prend à rêver d’une fonction permettant de savoir exactement à quel moment de la vidéo un utilisateur a posté son commentaire.
Mais, hormis les annotations explicites faites par les utilisateurs eux-mêmes dans leurs messages (par exemple en citant une minute précise), il n’est actuellement pas possible d’accéder automatiquement à ces données.
Une piste que je n’ai pas encore explorée serait de tenter de synchroniser la retranscription directement sur les timestamps des tokens, et non sur ceux des segments de texte entiers.