Ici, le but de cet article est de décrire le workflow d’une AFCM réalisée avec le logiciel Orange Data Mining (free, gratuit, gratos!) et de le comparer à un script R utilisant le package FactoMineR.
Autant le dire tout de suite : l’AFCM dans Orange Data Mining est très facile à mettre en œuvre, mais le résultat est décevant en raison de la faible quantité d’informations que l’on peut exporter.
Dans cet article, je m’intéresse à l’analyse factorielle des correspondances multiples (AFCM) appliquée à un même jeu de données, mais calculée selon deux approches différentes : d’un côté avec le logiciel Orange Data Mining, de l’autre avec un script R.
Cette comparaison montre la différence de calcul de l’inertie selon que l’on utilise la matrice de Burt (méthode appliquée par le logiciel Orange Data Mining) ou le tableau disjonctif (méthode classique en AFCM, utilisée ici dans le script R).
Pour réaliser le comparatif, vous disposez des ressources suivantes :
- Le fichier de données source : sciences.csv
- Le workflow dans Orange Data Mining (widget PCA)
- Le script R disponible sur GitHub (à utiliser avec RStudio, par exemple)
1. Qu’est-ce que l’AFCM (ou ACM) ?
L’AFCM est une méthode exploratoire : elle sert à repérer des structures, des oppositions, des profils d’individus, des groupes de modalités.
Le test de référence lié au cadre de l’AFCM est le test du khi2 d’indépendance. Il n’est pas utilisé pour calculer les coordonnées des modalités sur les axes, mais pour mesurer statistiquement s’il existe des associations entre variables (par exemple : variable “edu” × variable “B”)
1.1 Préparation les données
https://drive.google.com/drive/folders/1lkcySnBTHzi96zyEA3mEZHaGQKTOeV4v?usp=sharing
Comme pour toute analyse statistique, il faut s’assurer de bien préparer les données. On part ici d’un tableau individus × variables qualitatives.

Le jeu de données (pédagogique) « Fait-on confiance à la science ? » provient d’une enquête réalisée en 1993 auprès de 871 enquêtés sur leur opinion concernant le rôle de la science.
J’ai repris ce jeu de données grâce au blog de Valérie Monbet et à son TP (source).
Chaque enquêté répond à quatre questions à échelle, avec cinq modalités de réponse possibles codées de 1 à 5 (échelle), mais que j’ai ensuite recodées dans Orange Data Mining/et le script R en modalités : A_1, A_2,…
Les quatre questions sont les suivantes :
Question A : « Nous croyons trop souvent en la science et pas assez à l’intuition (aux sentiments et aux croyances). »
- A_1 = tout à fait d’accord – A_2 = d’accord – A_3 = pas d’avis – A_4 = pas d’accord – A_5 = absolument pas d’accord
Question B : « Globalement les sciences font plus de mal que de bien. »
- B_1 = tout à fait d’accord – B_2 = d’accord – B_3 = pas d’avis – B_4 = pas d’accord – B_5 = absolument pas d’accord
Question C : « Tous les changements que les hommes font à la nature, aussi scientifiques soient-ils, sont susceptibles d’empirer les choses. »
- C_1 = tout à fait d’accord – C_2 = d’accord – C_3 = pas d’avis – C_4 = pas d’accord – C_5 = absolument pas d’accord
Question D : « La science va résoudre les problèmes d’environnement sans affecter notre façon de vivre. »
- D_1 = tout à fait d’accord – D_2 = d’accord – D_3 = pas d’avis -D_4 = pas d’accord – D_5 = absolument pas d’accord
Le fichier contient également des variables illustratives/sociologiques : le sexe (sex1 = homme, sex2 = femme), l’âge en 6 classes (age1 = 16–24 ans, …, age6 = 65 ans et plus) et le niveau d’éducation en 6 niveaux (edu1 = enseignement primaire, …, edu6 = Bac + 8).
1.2 Construire le tableau disjonctif (TD)
Là, ça coince… du côté du logiciel Orange Data Mining…
C’est un tableau 0/1 : une colonne par modalité ; une ligne par individu ; 1 si l’individu possède la modalité, 0 sinon.

Soit on travaille directement sur le tableau disjonctif (c’est l’usage le plus courant), soit on forme le tableau de Burt (méthode utilisée dans Orange Data Mining).
1.3 Tableau disjonctif vs Burt ?
L’inertie, dans le cadre des analyses factorielles, mesure la « dispersion » des individus par rapport au centre des facteurs. Plus les individus sont différents les uns des autres (par leurs réponses), plus l’inertie est élevée. Quand on projette les données sur les axes factoriels, chaque axe capte une partie de cette inertie totale.
Le pourcentage d’inertie expliqué par un axe indique donc la part de la variabilité des données que cet axe résume. Ainsi, plus un axe explique d’inertie, plus il est « informatif » pour comprendre les oppositions et les structures présentes dans les données.
Avec le TD, on travaille sur le tableau individus × modalités.
Avec le tableau de Burt, on travaille sur un tableau modalités × modalités qui compile toutes les cooccurrences.

Les scores d’inerties affichées ne seront pas identiques selon la méthode employée.
Les axes et les positions relatives sont (quasiment) identiques entre AFCM sur TD vs Burt ; ce qui change, ce sont les pourcentages d’inertie affichés, parce que les deux tableaux n’agrègent pas l’information de la même façon.
2. Workflow avec Orange Data Mining
Orange propose le widget “Correspondence Analysis” (CA) qui s’applique à notre jeu de données.
2.2.1 Importation
Ouvrez “File”, charger le fichier “sciences.csv”. Dans ce fichier, toutes les variables sont stockées sous forme de nombres entiers, mais elles correspondent en réalité à des variables qualitatives codées. Les variables A, B, C et D prennent les valeurs 1, 2, 3, 4, 5. Ce sont les réponses aux questions sous forme d’échelle en 5 modalités. Statistiquement, on les traite comme des variables catégorielles ordinales ; il faudra alors ré-encoder leurs modalités.
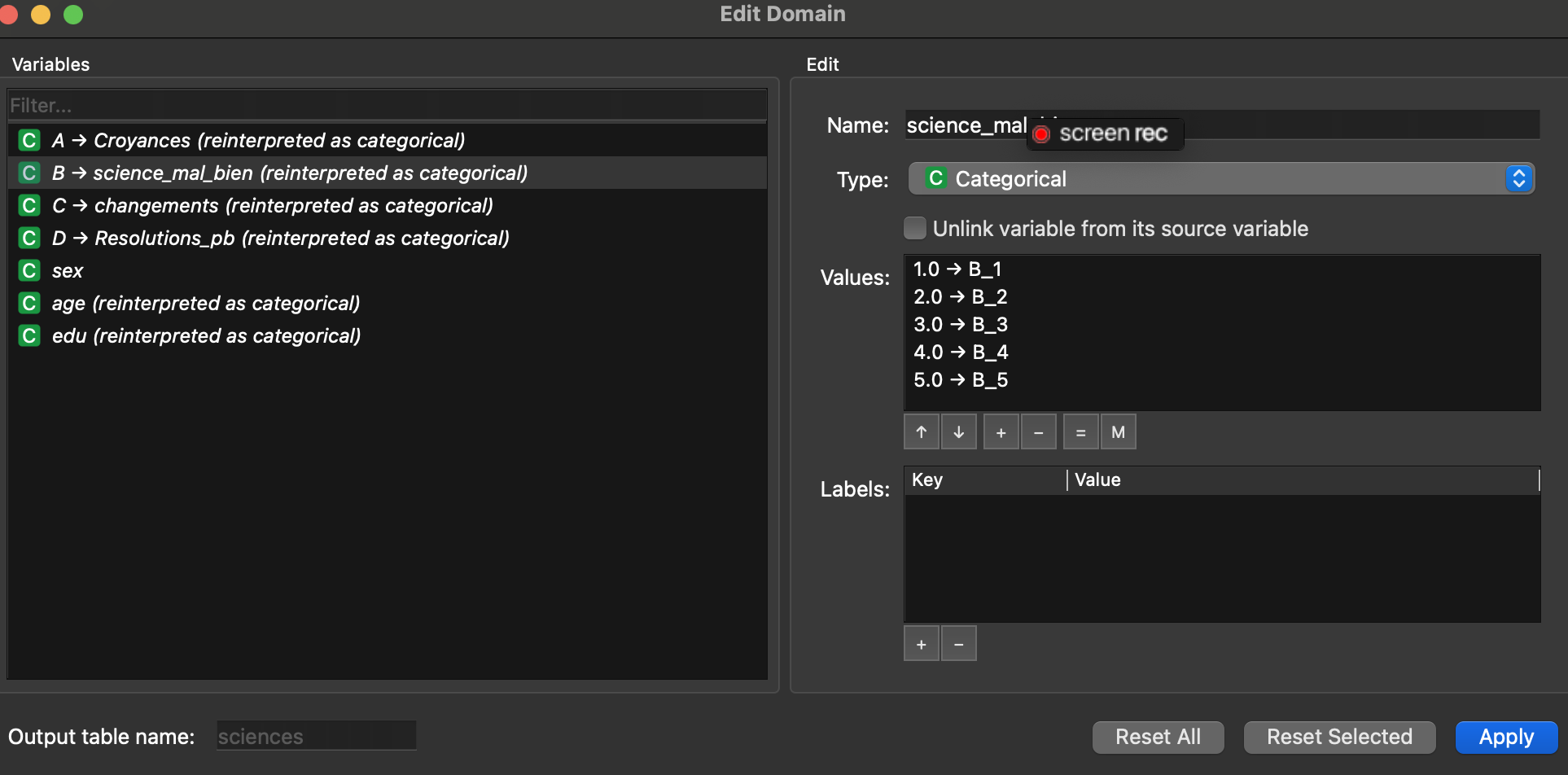
2.2.2 Widget : “Edit domain”
Il permet de déclarer les variables du fichier comme variables catégorielles et de ré-encoder leurs modalités, en remplaçant par exemple les codes numériques (1, 2, 3…) par des catégories explicites.
2.2.3 Widget « Select Column »
Si vous voulez sélectionner les variables pour le calcul de l’AFCM. Vous pourrez également, dans le widget « Correspondence Analysis », sélectionner ou désélectionner les variables, ce qui aura pour conséquence de modifier dynamiquement les scores d’inertie.
2.2.4 Widget « Correspondence Analysis »

2.2.5 Comparatif de l’inertie avec le script R
Ici, les deux images issues de l’AFCM réalisée avec un script R (FactoMineR) montrent bien la différence de score de l’inertie selon la méthode employée. Avec le logiciel Orange Data Mining, vous n’aurez pas le choix de la méthode. Le logiciel calcule l’inertie à partir du tableau de Burt et non du tableau disjonctif.
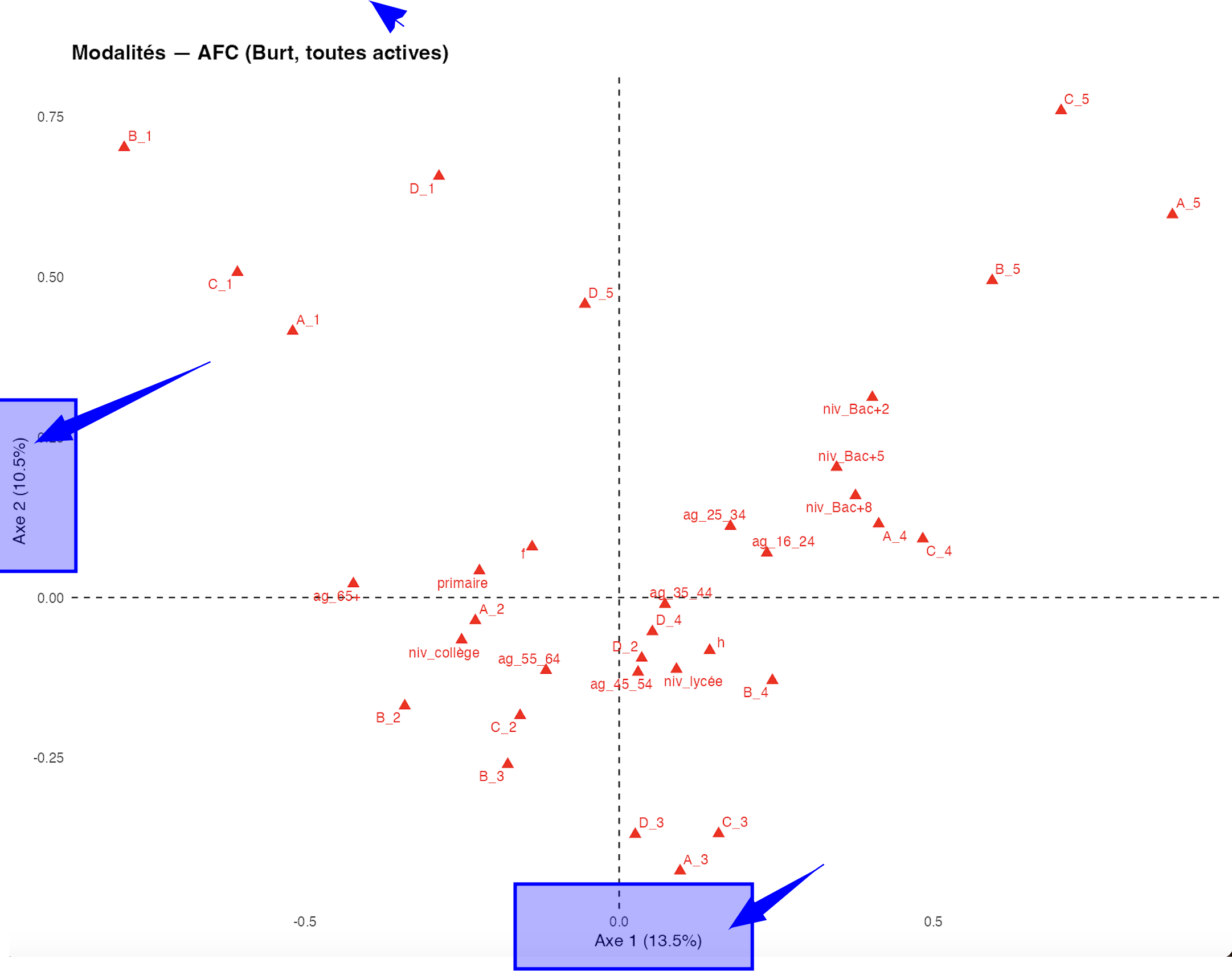

Le script R calcule, lui, l’inertie avec les deux méthodes afin de pouvoir comparer et vérifier celle utilisée par Orange : le tableau disjonctif et la méthode de Burt.
On peut vérifier avec le script R que le logiciel Orange Data Mining réalise une AFCM à partir de la méthode de Burt.

2.2.5 Widget “DataBase”
À la sortie du widget « Correspondence Analysis », vous pouvez connecter le widget « DataBase » pour voir les coordonnées des modalités, mais vous n’aurez pas de tableau de khi-deux ni d’autres tableaux explicatifs.
Les possibilités d’exportation des données sont donc limitées dans Orange Data Mining.
Conclusion
Pour conclure, cet article avait pour objectif de montrer que le logiciel Orange Data Mining est un outil remarquable : son système de widgets « no code » le rend particulièrement accessible. En revanche, certains modules, comme celui d’AFCM, restent limités du point de vue des possibilités d’exportation et de contrôle fin des méthodes, surtout si l’on compare avec une solution fondée sur du « code » (ici, un script R avec FactoMineR).
Précision, Orange Data Mining propose (non développé ici) un widget « Python Script », qui permet d’implémenter des fonctions complémentaires lorsque celles-ci ne sont pas disponibles dans les widgets fournis par défaut.