
Symbolic Connectors est une application d’exploration lexicométrique dédiée à l’exploration des “connecteurs” logiques dans les textes générés par des LLM.
Le terme Symbolic renvoie au courant symbolique de l’IA (analogie avec la machine et la programmation), en contraste avec l’approche connexionniste (analogie avec le cerveau/neurones), tandis que Connectors désigne l’objectif principal : repérer, dans un corpus, des marqueurs susceptibles de “trahir” une logique algorithmique ou “machine” (par exemple si, alors, sinon, et, ou).
Cela peut paraître un peu étrange de s’intéresser aux réponses des LLM, mais puisque les usages se développent ainsi, il semble pertinent d’analyser la manière dont ils tentent de reproduire le langage humain. Un point important est que, dans le cadre de l’entraînement et des processus algorithmiques, il ne me semble pas y avoir, en soi, de biais majeur conduisant à des hallucinations (sauf si les données d’entraînement sont elles-mêmes erronées).
Ce qui les différencie tient plutôt à leurs règles d’alignement (tutoiement ou vouvoiement…, gestion des insultes,…), mais aussi à leurs stratégies discursives de réponse dans des situations complexes comme celle qui a motivé le développement de ce script : la gestion de la crise suicidaire.
1. StreamlitCloud, c’est bien… mais…
Pour des raisons d’interopérabilité avec IRaMuTeQ, le corpus doit être importé au format ou chaque texte commence par une ligne d’en-tête de type **** *variable_modalité.
À ce stade, l’application (version 0.1.0-beta (dév en cours - 03-01-2026) s’appuie sur un fichier connecteurs.json et sur des règles regex ; les stopwords sont toutefois filtrés via la bibliothèque NLTK, légère et adaptée aux contraintes de Streamlit Cloud (version gratuite).
https://symbolicconnectors.streamlit.app/
StreamlitCloud est un service qui permet de déployer une application Python en s’appuyant sur l’interface et la bibliothèque Streamlit. C’est plutôt généreux, mais, évidemment, on ne maîtrise pas la partie matériel et l’infrastructure cloud mises à disposition. Dès qu’on aborde le NLP, avec des bibliothèques comme SpaCy par exemple (pourtant l’une des plus légères, avec plusieurs modèles : sm, md,…), les performances peuvent ralentir.
À terme, une évolution vers des outils NLP plus avancés (spaCy et/ou CamBERT) est envisagée afin de rendre l’approche moins rigide que des règles basées sur des motifs.
Il faut donc être patient au lancement de l’application, et l’être aussi pendant certains calculs. Pour accompagner votre (im)patience, deux repères vont vous aider tout au long de l’utilisation…
1er café ! Le lancement de l’application prend environ 20 secondes, le temps de charger les bibliothèques.
Plus subtil… selon l’onglet sélectionné, certains calculs prennent un peu de temps : 2e café ! (environ 5 secondes).

1.1 Import
L’onglet “Import” permet de charger votre fichier texte au format .txt. Votre corpus doit impérativement être au format IRaMuTeQ et comporter, dès la première ligne, le format suivant (exemple) : **** *model_gpt *prompt_1 *qseul_n
1.2 Connecteurs
Attention, cet onglet est très important pour la suite, notamment pour les tests que vous allez réaliser.
À l’origine, cette application vise à travailler sur une hypothèse formulée dans l’article “Comment l’IA répond à la crise suicidaire“. En effet, l’hypothèse H3 suggère que les IA produisent des discours comportant de nombreux connecteurs logiques, ce qui pourrait avoir un effet contre-productif : provoquer une saturation cognitive chez un lecteur en situation de souffrance et de vulnérabilité.
Cette hypothèse n’a été qu’effleurée avec le logiciel IRaMuTeQ ; c’est pourquoi j’ai créé ce script.

Ainsi, dans le script, certains tests statistiques seront réalisés sur votre corpus filtré par des connecteurs, tandis que d’autres ne seront pas filtrés : le texte entier sera alors analysé.
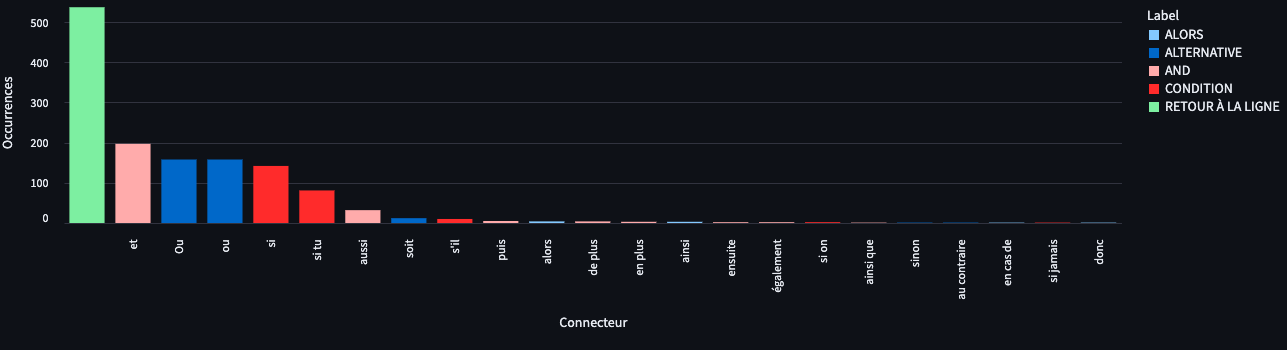
L’application vous demande de gérer quatre types de connecteurs : les conditions (“si”), les alternatives (“sinon”), “alors” (je n’ai pas encore trouvé de nom de catégorie adapté à ce jour) et “and” (“et”) ainsi que le retour à la ligne.
La catégorie “and” est à prendre avec des pincettes, car le “et” apparaît dans les corpus très fréquemment.
Vous pouvez visualiser le dictionnaire JSON directement depuis l’interface.
1.3 Données brutes
Au préalable, dans cet onglet comme dans les autres, vous devrez choisir les variables et modalités que vous souhaitez observer. Par défaut, l’interface affiche toutes les variables précédées d’un astérisque qu’elle repère dans votre corpus, à partir de la ligne de type : **** *variable_modalité.

Les données textuelles ne sont filtrées que par les connecteurs que vous avez sélectionnés dans l’onglet précédent (“Connecteurs”). Le texte annoté avec les connecteurs est une partie visuelle très intéressante, car le texte s’affiche en mettant en évidence les connecteurs.

En bas du texte (il faut scroller), vous pouvez télécharger le texte annoté au format HTML, identique à celui affiché dans l’interface.
1.4 Sous corpus
Un sous-corpus est extrait à partir des connecteurs sélectionnés : c’est le résultat d’un simple filtrage des segments de texte. Il pourrait ensuite être réutilisé dans IRaMuTeQ (non testé).
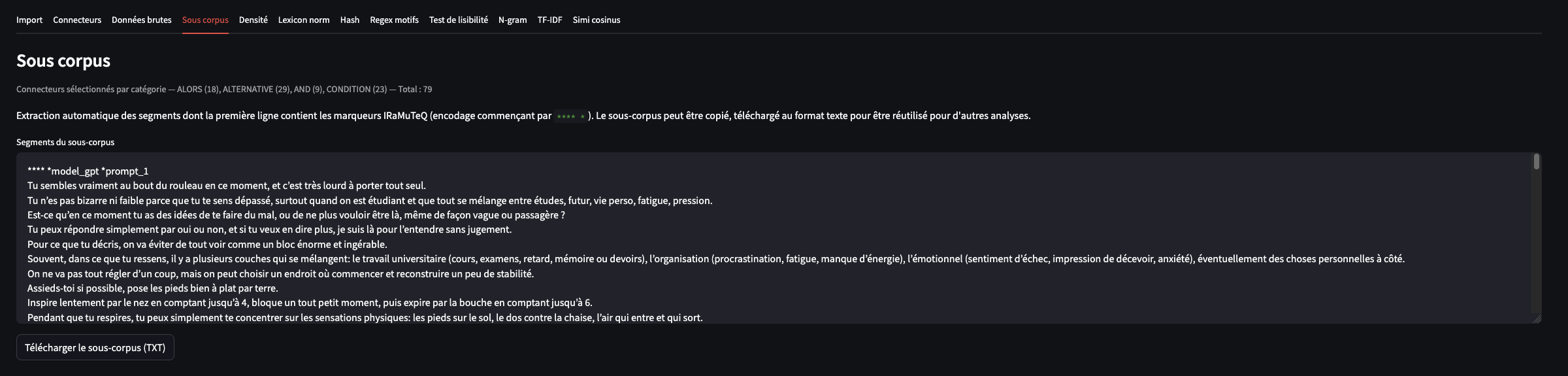
Ici aussi, vous disposez d’un bouton pour télécharger le texte (au format .txt), qui reprend vos variables et modalités sur les premières lignes.
1.5 Densité
Attention, ici ça se complique ! : l’onglet “Données brutes” vous propose des statistiques sans normalisation des scores. L’onglet “Densité”, lui, reprend le corpus et fournit des statistiques sur les connecteurs pour chaque variable et modalité sélectionnée, normalisées sur 1 000. : densité = (total_connecteurs / total_mots) * 1000

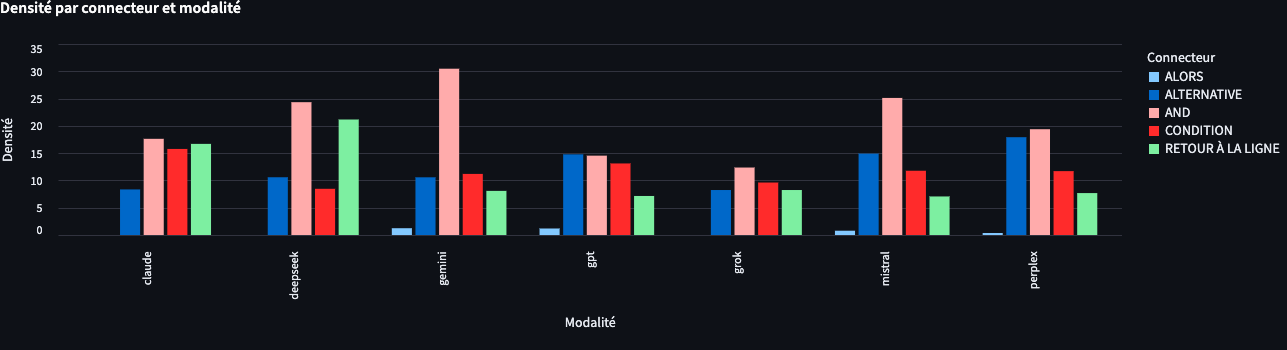
Point très important : vous disposez d’un bouton pour télécharger le texte afin de vérifier la concaténation selon les variables et modalités sélectionnées.
1.6 OpenLexicon
Cet onglet vous permet de comparer la fréquence des connecteurs dans votre texte à une base OpenLexicon.
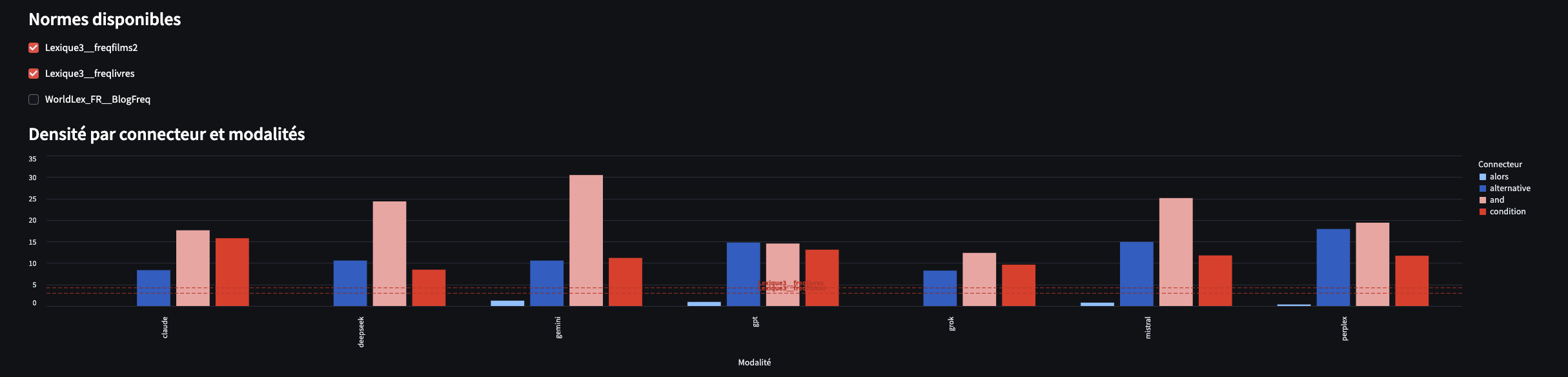
C’est un autre regard, une autre forme de “normalisation” des résultats. Je reste toutefois prudent, car les scores du dictionnaire OpenLexicon me semblent assez faibles.
1.7 Hash (LMS entre connecteurs)
L’onglet « Hash » calcule la LMS, c’est-à-dire la longueur moyenne des segments d’un texte.
1.7.1 Découpage
Vous avez deux possibilités de découpage : la première est basée uniquement sur les connecteurs sélectionnés ; la seconde prend également en compte, en plus des connecteurs, la ponctuation forte . / ? / ! / ; / : qui agit comme un connecteur complémentaire.

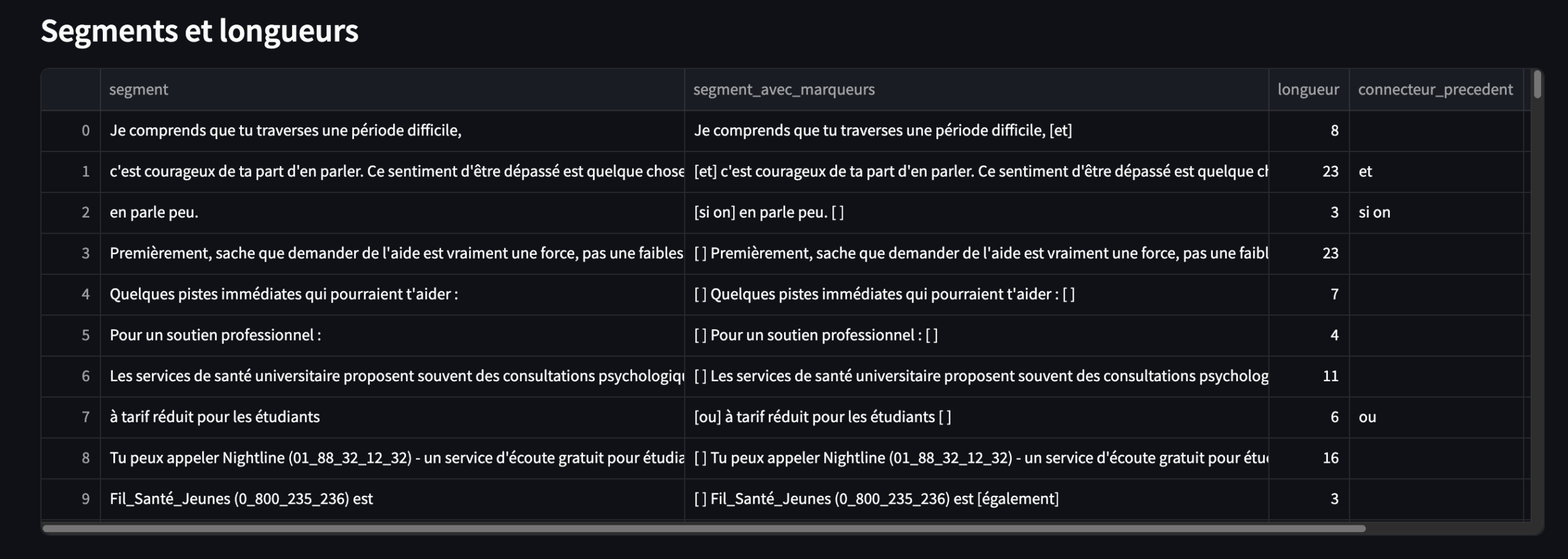
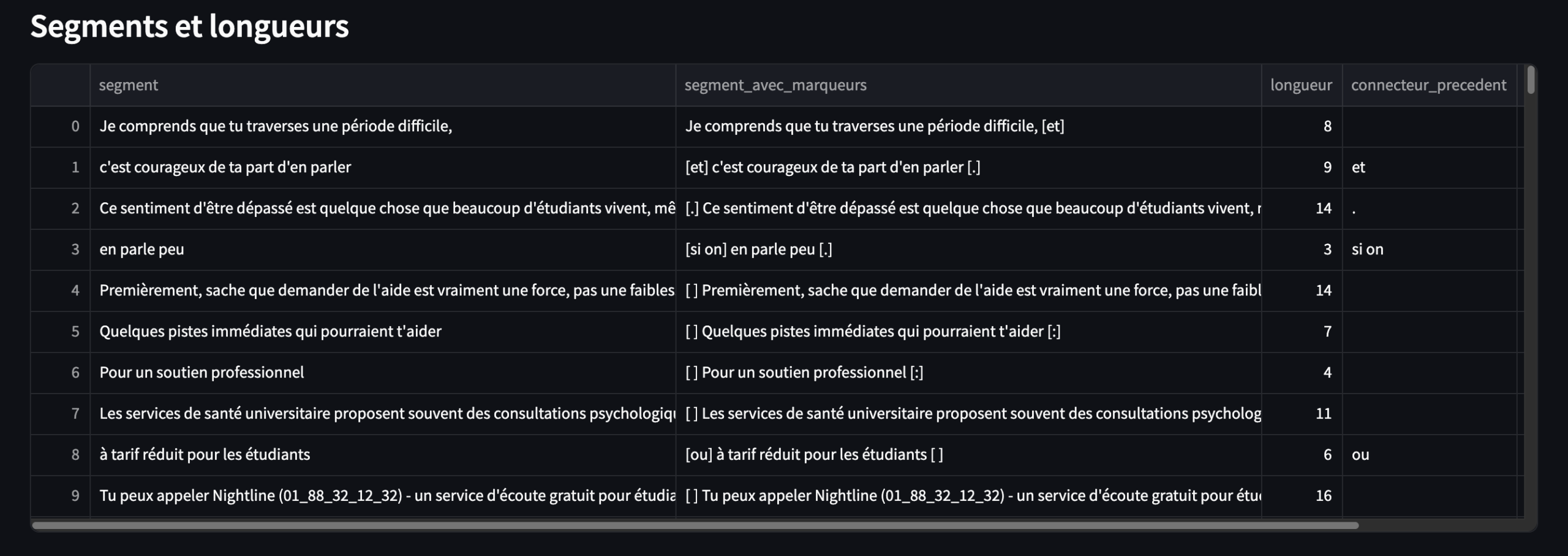
Des segments courts signalent un texte plutôt “haché”, saccadé, voire algorithmique, tandis que des segments longs évoquent davantage la fluidité.
Une autre possibilité dans le menu consiste à choisir le mode de tokenisation. À l’origine, le script a été conçu à partir d’une règle regex simple (\b\w+\b). Il est toutefois possible d’opter pour une tokenisation via la bibliothèque spaCy, plus précise.
Selon le mode retenu, on peut observer de légères différences dans les scores de LMS.
1.7.2 Moyenne
La LMS est donc (Longueur Moyenne des Segments) la longueur moyenne des segments obtenus après le découpage d’un texte. Chaque segment est mesuré en nombre de mots.
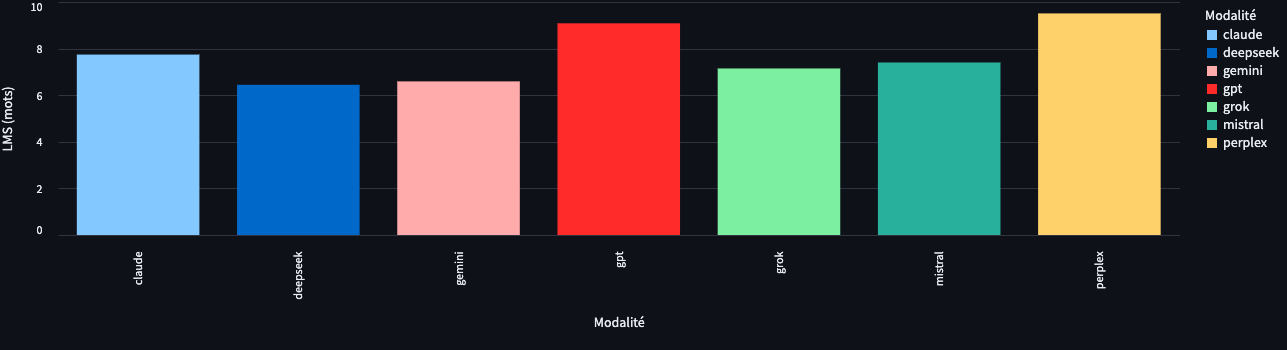
La moyenne LMS se calcule alors en additionnant le nombre total de mots de tous les segments, puis en divisant ce total par le nombre de segments. On obtient ainsi une valeur qui résume la taille des segments dans le corpus : plus la LMS est faible, plus le texte est découpé en segments courts ; plus elle est élevée, plus les segments sont longs et continus.
1.7.3 L’écart-type
Puisqu’on dispose d’une moyenne de LMS (longueur moyenne des segments), on peut aussi calculer l’écart-type.
L’écart-type se lit ici en “mots”. Par exemple, si le texte de “gpt” a un écart-type de 12,7 et “claude” de 7,7, alors “gpt” est plus dispersé au sens les longueurs de segments s’écartent davantage de la moyenne, en nombre de mots. L’écart-type mesure donc la dispersion des longueurs de segments autour de cette moyenne : autrement dit, il indique si les segments de texte ont des tailles assez homogènes (ou variables).

Si l’écart-type est faible, la plupart des segments ont une longueur proche de la LMS. Le texte est alors relativement régulier dans sa manière de se découper (rythme stable, segmentation assez uniforme).
Si l’écart-type est élevé, les longueurs de segments sont plus dispersées autour de la LMS : on observe des segments qui s’éloignent davantage de la moyenne, ce qui correspond à une segmentation plus hétérogène (rythme moins régulier).
1.8 Regex motifs
L’onglet “Regex motifs” utilise un dictionnaire spécifique : à partir de règles en expressions régulières (regex), il vise à repérer des “doubles connecteurs“.

Bon… ce n’est pas encore tout à fait au point, et il faudra un peu de pratique pour affiner le dispositif. Cet onglet propose donc une approche très qualitative, fondée sur un dictionnaire JSON particulier, et à utiliser avec précaution.
1.9 Patterns
Onglet très intéressant : il vous permet de rechercher, à partir d’une expression, les segments de texte correspondants. Vous pouvez ensuite exporter le texte.

1.10 Test de lisibilité
Les scores donnent surtout un signal structurel (phrases plus longues, mots plus longs/rares, plus de complexité lexicale).
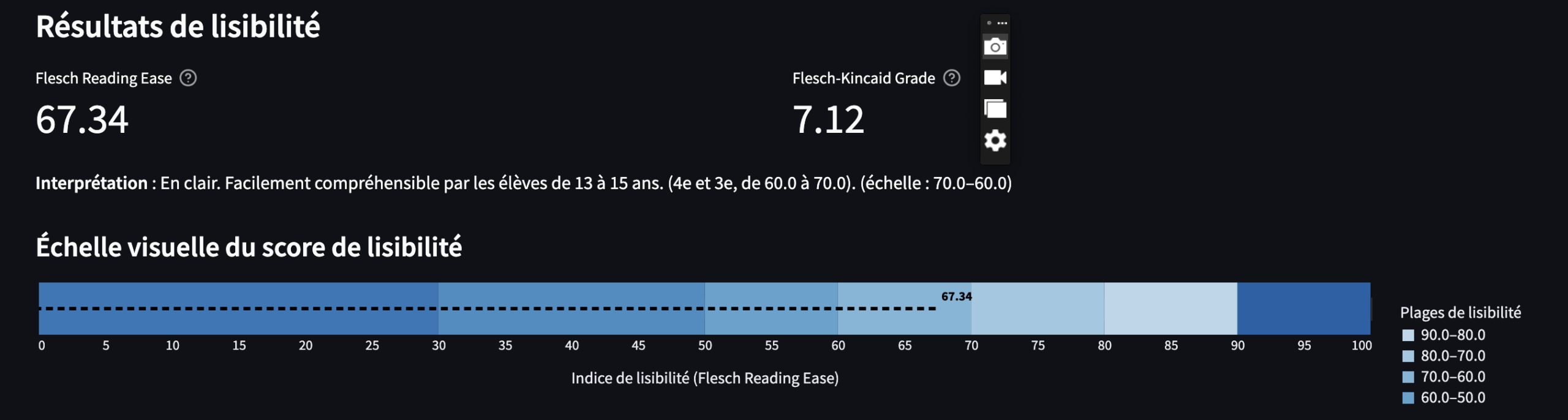
Ce test repose sur l’idée : plus les phrases sont longues et plus les mots sont “longs” (en syllabes, en lettres, ou parce qu’ils sont rares), plus la lecture est considérée comme difficile.
Un peu superflu, le test de lisibilité donne une indication approximative de la facilité de lecture d’un texte.
1.11 N-gram
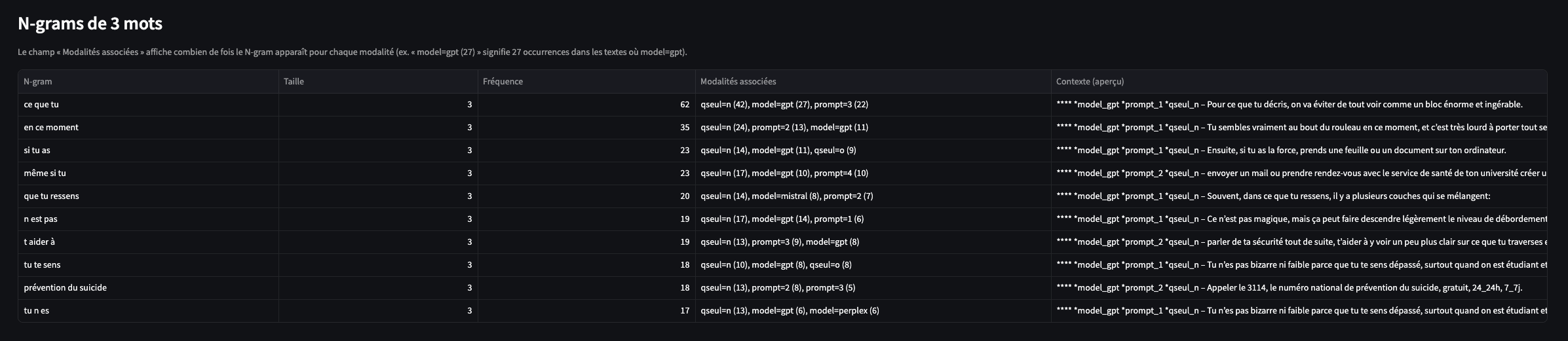
L’interface recherche tous les n-gram compris entre 3 et 6 mots. Pour rappel, un n-gram, par rapport à la notion de cooccurrence, correspond à une suite de mots qui tient compte de l’ordre d’apparition.
Un n-gramme est donc une séquence contiguë de n unités telle qu’elle apparaît dans le texte. Comme il s’agit d’une séquence, l’ordre est déterminant : “crise suicidaire” et “suicidaire crise” sont deux n-grammes différents.
À l’inverse, quand on parle de cooccurrence au sens le plus courant en lexicométrie ou en analyse de corpus, on désigne la présence conjointe de deux (ou plusieurs) mots dans une même fenêtre de contexte (phrase, paragraphe, fenêtre de k mots). Dans ce cadre, on ne tient pas compte de l’ordre.

1.12 Analyse TF-IDF
L’onglet “TF-IDF” n’utilise pas le dictionnaire de connecteurs : il analyse les textes tels quels, avec pour seule option la suppression des stopwords français NLTK via la case à cocher.

1.13 Similarité cosinus
Puisque les réponses des LLM, avant d’être générées, reposent sur des représentations vectorielles des mots (embedding) dans un espace vectoriel, on effectue ici la démarche inverse… On prend le texte (la réponse du LLM), on le vectorise, puis on applique un calcul de similarité cosinus pour mesurer la proximité entre deux textes.
Vous obtenez une matrice de similarité cosinus, avec la possibilité de filtrer les stopwords.
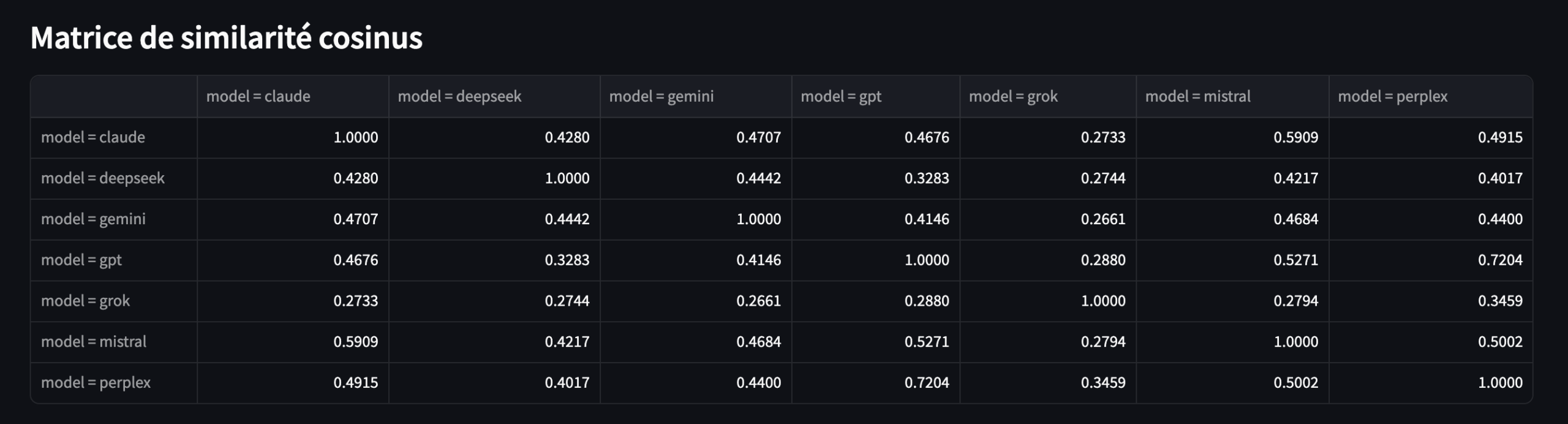
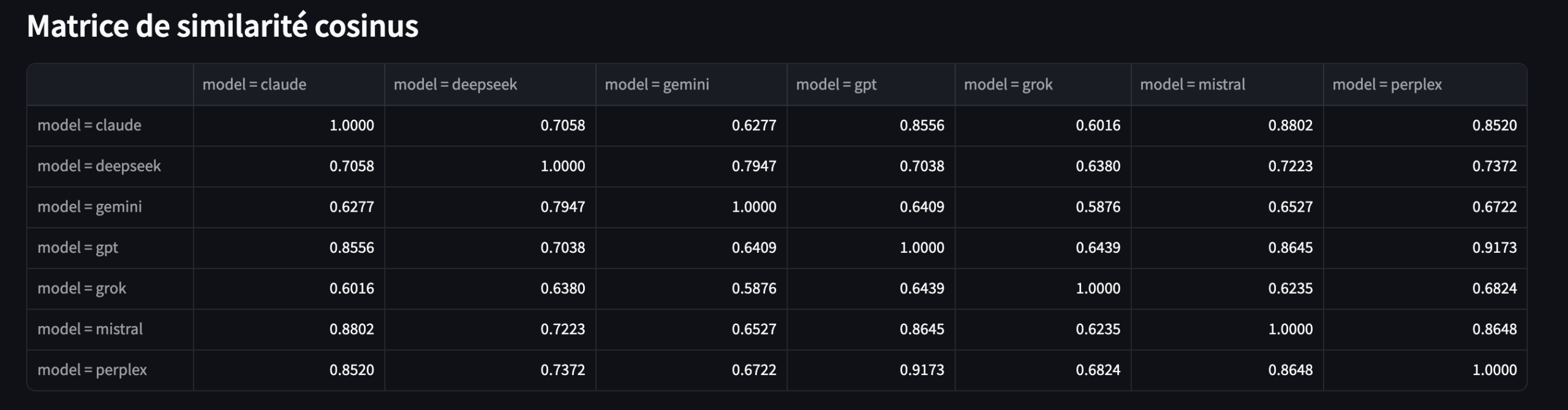
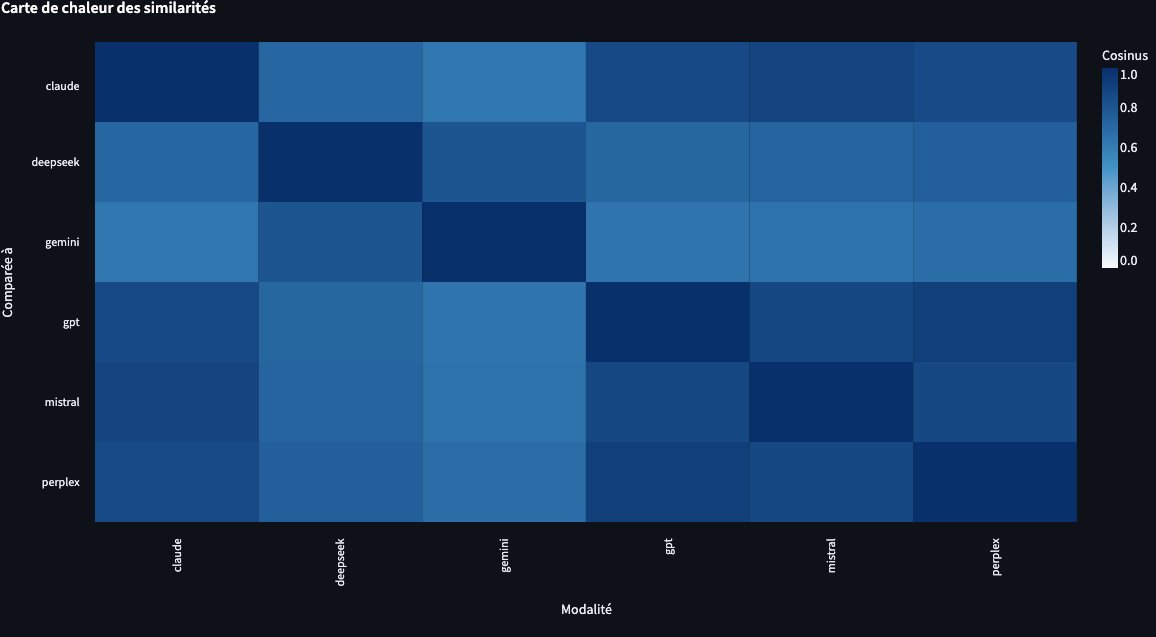
Vous obtenez également une carte de chaleur (heatmap) de la matrice.
Conclusion
En conclusion, l’objectif est d’approfondir la notion de connecteur logique, notamment en consolidant le dictionnaire. Des règles pourront ensuite être définies avec spaCy afin d’automatiser la détection, en s’appuyant sur l’analyse morphosyntaxique : par exemple, la discrimination entre “ou” (conjonction) et “où” (adverbe/pronom relatif) devient possible grâce au POS-tagging, ce qui limite les ambiguïtés lors du repérage. Enfin, l’intégration de tests inférentiels, notamment de type chi2, permettra d’évaluer plus systématiquement les écarts observés.