
Dans cet article, nous allons développer l’approche de l’analyse des cooccurrences à partir d’un mot pivot.
Vous pouvez retrouver dans un autre article l’analyse des cooccurrences “complètes” d’un corpus (sans mot pivot).
No code : https://cooccurrences-motpivot.streamlit.app/
Github : https://github.com/stephane1109/Cours-AT-ISTHIA-M2/blob/main/cooccurrences/cooccurrences-motpivot.py
Dans un texte, il est possible de compter les associations entre deux termes. Ces associations entre mots sont appelées cooccurrences : deux “mots” sont cooccurrentes lorsqu’ils apparaissent dans un même voisinage.
Parenthèse : Il existe plusieurs dictionnaires de cooccurences, on peut citer : “Le Grand Druide des cooccurrences” (Simon Charest, Jean Fontaine et Jean Saint-Germain) … construit à partir d’un corpus de 92 millions de phrases, il repose sur des algorithmes d’analyse qui permettent de cartographier les relations lexicales les plus fréquentes de la langue.
1. Qu’est-ce qu’une cooccurrence ?
En analyse textuelle, on parle de cooccurrence lorsque deux unités lexicales apparaissent dans une même unité de contexte, appelée fenêtre autrement dit dans le même voisinage.
Un voisinage peut être de dimension variable.
Deux mots sont dits cooccurrents s’ils “co-apparaissent” dans ce voisinage (fenêtre) : par exemple, tourisme et fréquentation pourrait apparaitre ensemble dans la même phrase ou le même paragraphe.
La notion de cooccurrence est donc relative au choix d’une fenêtre de contexte, il peut s’agir :
- D’un nombre fixe de mots autour d’un pivot (voisinage immédiat avec k = ± n, autour du pivot).
- D’une phrase ou d’un paragraphe pour analyser les associations sémantiques
- Ou même de l’ensemble d’un document propice pour une analyse thématique
Les mots cooccurrents ne sont pas nécessairement consécutifs ; ils partagent simplement le même contexte textuel.
La cooccurrence et donc à distinguer des n-grammes (n-gram), qui sont des séquences continues de n mots.
La notion de n-grammes est utilisée dans les moteurs de recherche ou dans les modèles de langage pour repérer des expressions fréquentes. Le n-gram désigne une séquence exacte et continue de n éléments dans un corpus, en tenant compte de l’ordre.
2. Définir une “fenêtre” pour analyser les cooccurrences
Prenons les phrases suivantes :
(Phrase 1)
Le tourisme à Paris connaît une forte croissance économique grâce à la hausse de la fréquentation étrangère.
2.1 Fenêtre de mots (k = ±2)
Autour du pivot tourisme (phrase 1) : on prend deux mots avant et deux mots après.
Le pivot est alors associé à : “Le, à, Paris, connaît” (dans cet exemple nous n’avons pas supprimés les stopwords).
2.2 Fenêtre de phrase
La fenêtre de phrase considère chaque phrase comme une unité lexicale, la segmentation se faisant à partir de la ponctuation (Ici, nous appliquons les “Stopwords”).
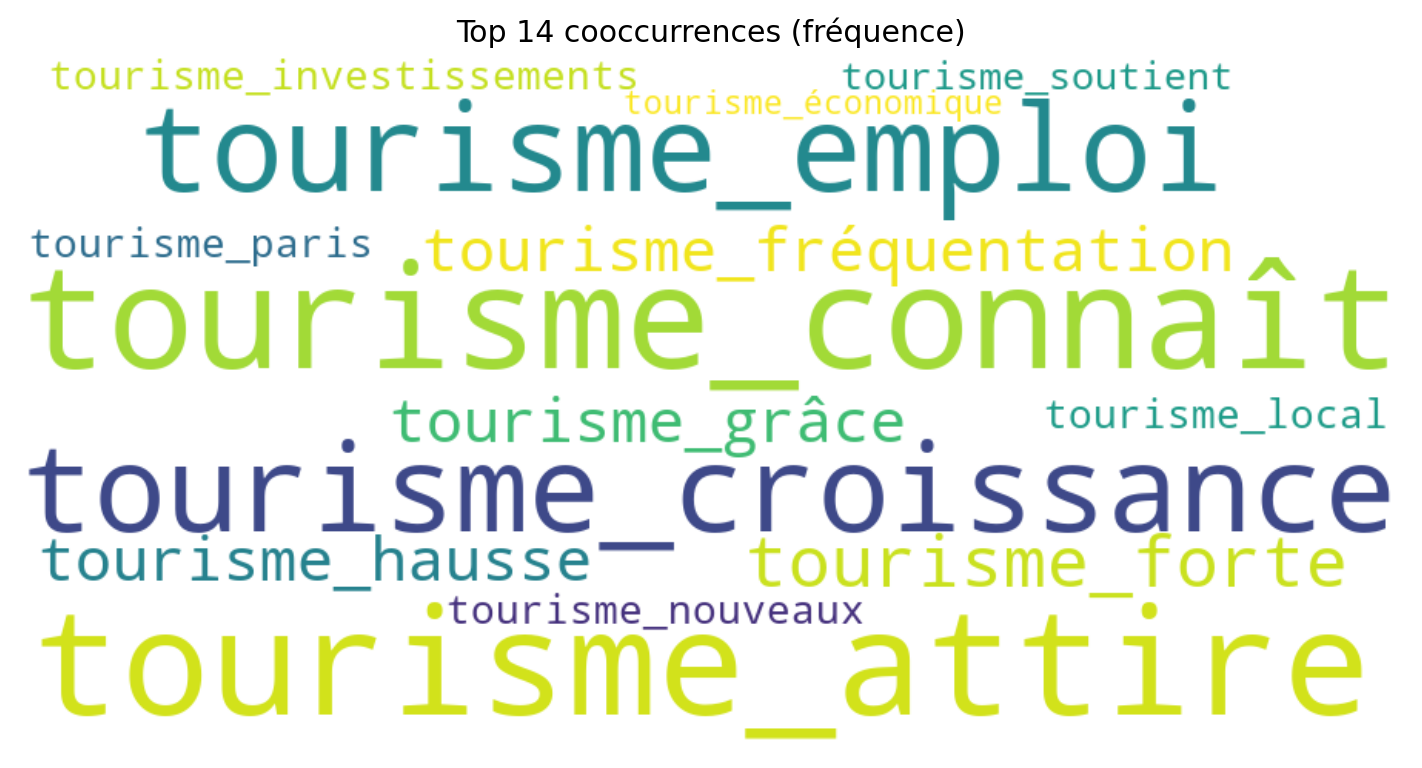
Voici le texte après suppression des stopwords :
(Phrase 1) : tourisme Paris connaît forte croissance économique grâce hausse fréquentation étrangère.
Analyse des cooccurrences à partir du mot pivot (tourisme) : Le mots cooccurrents sont les suivants : Paris, connaît, forte, croissance, économique, grâce, hausse, fréquentation, étrangère (8 cooccurrents).
Avec la fenêtre “Phrase”, nous nous appuyons sur la segmentation des phrases de spaCy (modèle fr_core_news_md), mais on ne le laisse pas faire !
Un correctif prend la main et impose un découpage, fondé sur la ponctuation suivante : ".", "!", "?", "…"
# fenêtre phrase : sentencizer règle-basé qui PREND LA MAIN sur doc.sents
# Règle de segmentation en phrases, basée sur la ponctuation forte.
# Par défaut spaCy coupe sur ".", "!", "?" ; on ajoute "…" et on force le remplacement.
nlp.add_pipe(
"sentencizer",
config={
"punct_chars": [".", "!", "?", "…"],
"overwrite": True
}
)
2.3 Fenêtre de paragraphe
Lorsqu’il y a une ligne vide dans le corpus, on considère qu’il s’agit de deux paragraphes distincts.
def segmenter_paragraphes(texte: str):
norm = texte.replace("\r\n", "\n").replace("\r", "\n") # normalise CRLF/CR -> LF
blocs = re.split(r"\n\s*\n+", norm) # <-- LIGNE QUI FAIT LA SÉPARATION
return [b.strip() for b in blocs if b.strip()]
Le motif r"\n\s*\n+" coupe dès qu’il y a au moins une ligne vide :
\n: fin de ligne\s*: éventuellement des espaces/tabs sur la ligne vide\n+: une ou plusieurs fins de ligne supplémentaires
Cette segmentation est ensuite utilisée pour construire les fenêtres paragraphe.
Paragraphe 1
Le tourisme à Paris connaît une forte croissance économique grâce à la hausse de la fréquentation étrangère.
Cette dynamique favorise la modernisation des transports publics.
Elle encourage également la création de nouveaux équipements culturels.
Paragraphe 2
Le tourisme soutient l’emploi local et attire de nouveaux investissements.
Il contribue à renforcer l’image internationale de la ville.
Certains habitants dénoncent toutefois les nuisances liées à la surfréquentation.
Le paragraphe étant l’unité de contexte. Cela signifie que tous les mots apparaissant dans le même paragraphe que le pivot “tourisme” sont considérés comme cooccurrents.
Paragraphe 1 : Pivot : tourisme
Cooccurrents = Paris, connaît, forte, croissance, économique, grâce, hausse, fréquentation, étrangère, contribue, développement, infrastructures, urbaines, stimule, création, nombreux, services, culturels, commerciaux.
Paragraphe 2 : Pivot : tourisme
Cooccurrents = soutient, emploi, local, attire, nouveaux, investissements, renforce, image, internationale, ville, encourage, partenariats, acteurs, publics, privés.
2.4 Mode d’agrégation “Documents”
Le mode d’agrégation “Document” affiche pour chaque fichier texte les résultats des cooccurrences (Dans chaque document la fenêtre utilisée est la fenêtres phrases pour les calculs).
Une « vraie » fenêtre « Document » serait intéressante, mais nécessiterait énormément de documents pour être lisible, puisqu’avec cette fenêtre on observerait les co-présences au niveau du document (un document compte 1 s’il contient à la fois le pivot et le mot, sinon 0). Cette approche serait intéressante pour comparer des articles (presse) selon les périodes.
Prenons maintenant un exemple de deux articles de presse au format fichier texte (.txt)).
surtourisme_texte_1
surtourisme_texte_2
L’analyse se fait donc sur chacun des document (on utilise la fenêtres phrases) afin de pouvoir comparer les thèmes abordées dans chacun des documents.
3. Analyse des cooccurrences à partir de la fréquence
Dans ce cadre d’analyse, le principe est simple : on comptabilise le nombre de cooccurrences observées dans la fenêtre définie. C’est ainsi que nous procédons pour le nuage de mots.
Pour la représentation en graphe de réseau, le principe est un peu différent, car nous allons pondérer les cooccurrences. Les arêtes du graphe sont proportionnelles à la somme des fréquences d’apparition conjointe, et la taille de chaque nœud est proportionnelle à la somme des fréquences des arêtes qui le relient.
Les explications sont présentées plus en détail dans l’article “Analyse des cooccurrences d’un corpus complet”.
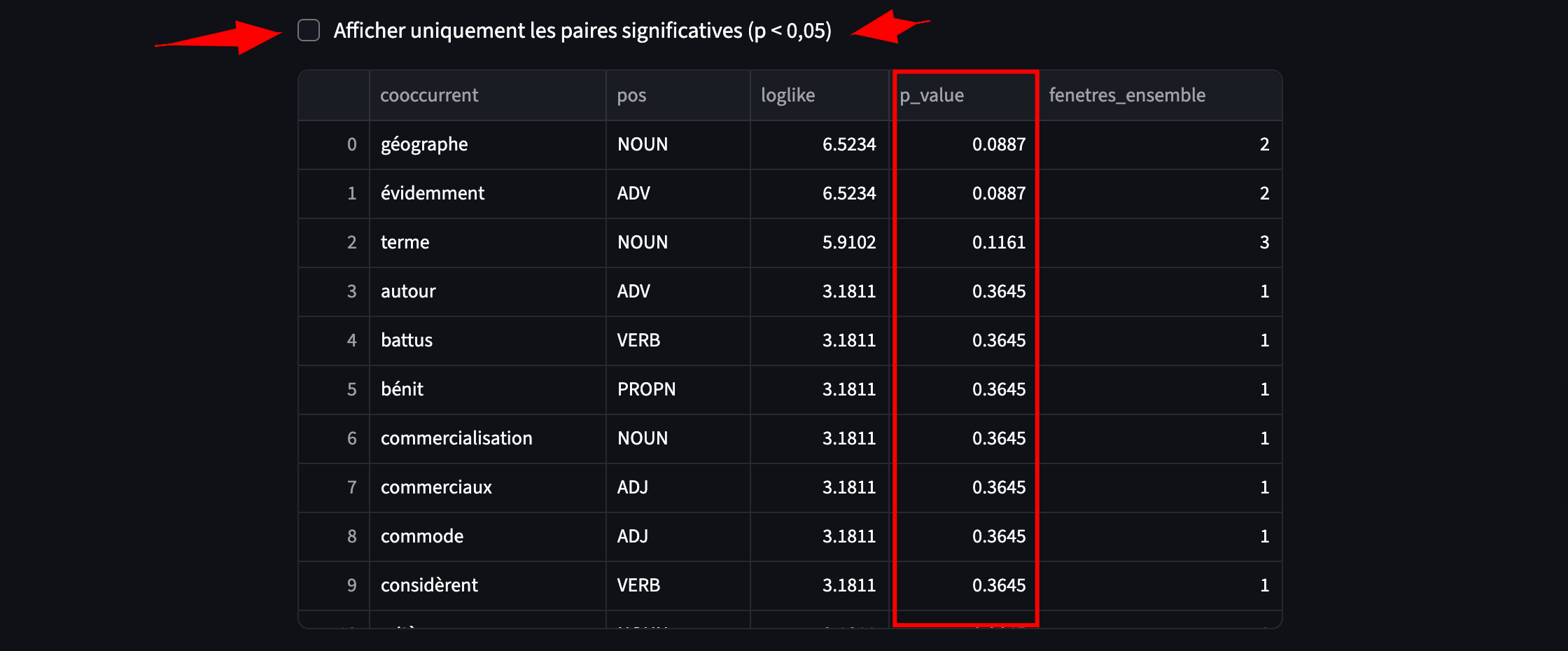
4. Mesurer la force des cooccurrences avec le log-likelihood
Un problème majeur réside dans le fait que les mots fréquents apparaissent souvent comme cooccurrents simplement par hasard. Il faut donc distinguer :
- les cooccurrences fortuites, dues au jeu du hasard,
- les cooccurrences significatives, beaucoup plus fréquentes que ce qu’on attendrait par hasard.
Pour distinguer les cooccurrences réellement significatives du simple hasard, on utilise une mesure statistique d’association.
Le log-likelihood compare la fréquence observée d’une cooccurrence avec ce qu’on attendrait si les deux mots étaient indépendants.
Un score élevé indique une association forte.
5. Les cooccurrences lexico-syntaxiques
Même si nous n’aborderons pas ce point dans l’article/script, on peut recourir aux relations syntaxiques pour identifier des cooccurrences.
Cette approche permet de repérer les mots liés par la syntaxe (par exemple, un verbe et son sujet).
Des outils comme le “Lexicoscope” exploitent ce type d’analyse. Si on travaille sur des phénomènes syntaxiques (par exemple, étudier la grammaire d’un corpus), il peut être pertinent de garder les stopwords.
Conclusion
Nous ferons évoluer le script afin d’implémenter une véritable fenêtre “Document”.