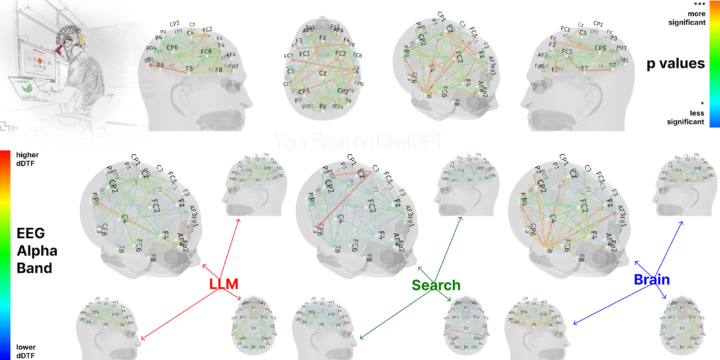
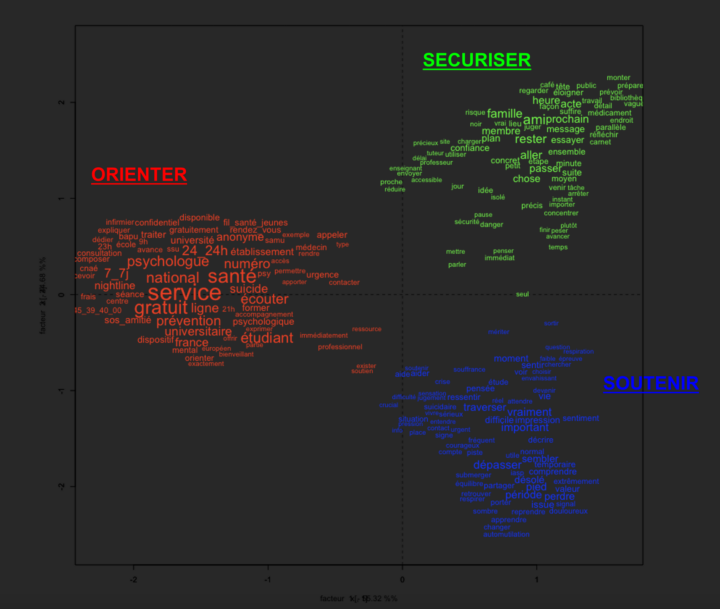
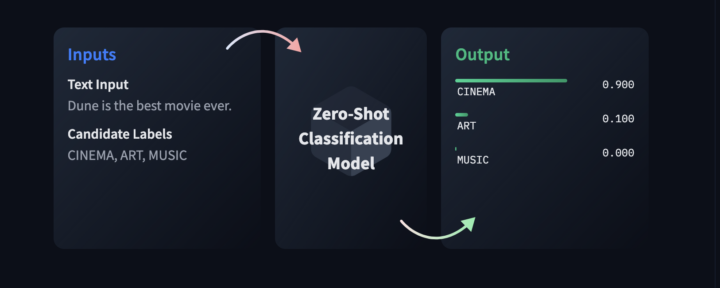
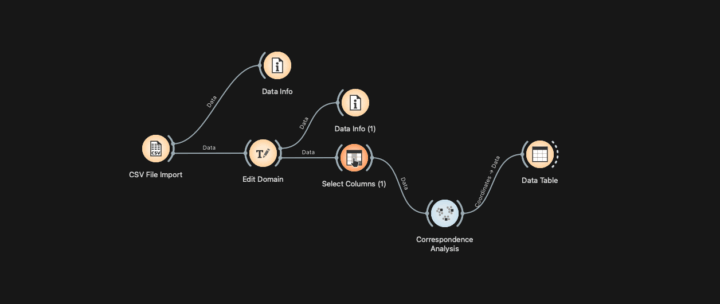
Quand vous envoyez un CV et une lettre de motivation, vous respectez un cadre qui vise à répondre à une annonce : vous produisez des documents aussi intelligibles que possible, en mettant en valeur vos compétences au regard des besoins et des missions de l’employeur. Dans ce contexte, on s’inscrit dans une démarche « classique », qui peut aller de la candidature spontanée à la réponse à une offre...