Reddit est un réseau social d’origine américaine fondé en 2005, qui se distingue des plateformes comme Facebook, X ou Instagram… par son fonctionnement communautaire et thématique. Structuré autour de “subreddits” (forums dédiés à des sujets spécifiques), Reddit permet aux utilisateurs de publier, commenter et voter des contenus textuels, visuels. Si Reddit occupe une...
Extraction multimédia à partir de YouTube

Streamlit Cloud est une solution particulièrement intéressante pour héberger gratuitement des applications Python. Simple à utiliser, directement connecté à GitHub, il permet de mettre en production très rapidement des projets basés sur l’interface graphique de Streamlit. Les dépendances sont directement installée et indiquée depuis un fichier requirements.txt. Pour l’utilisateur...
Analyse amplitude sonore & mouvements

Ce script s’inscrit dans une approche multimodale, croisant les variations de l’amplitude sonore (les “pics sonores”) avec les mouvements détectés dans l’image grâce à l’analyse du flux optique. L’objectif est d’explorer les corrélations entre ce que l’on entend et ce que l’on voit, dans des unités temporelles extrêmement brèves — centrées autour de trois instants clés : t−1, t et t+1...
Rendre audible l’inaudible
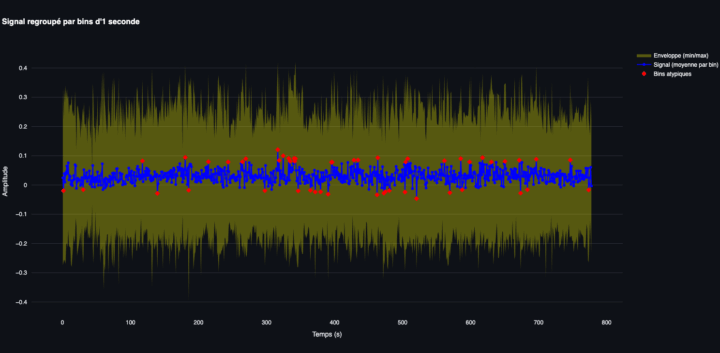
Cet article, dense, se déploie en deux temps : d’abord une exploration théorique du signal audio, puis une réflexion sur une méthode pour analyser, restituer et rendre ces données intelligibles. Il s’agit d’une approche multimodale, croisant audio et texte. Les données textuelles restent au cœur de l’analyse en SHS, mais elles peuvent aujourd’hui être parasitées par des contenus uniformisés...
Décrypter le discours : Approche par le débit de parole
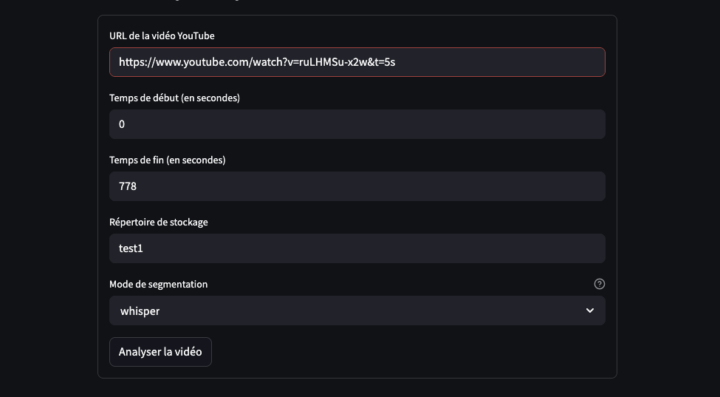
L’objectif de cet article est de présenter un script “expérimental” destiné à l’évaluation du débit de parole. Le script utilise la transcription automatique fournie par le modèle Whisper d’OpenAI pour découper l’audio en segments et mesurer la vitesse d’élocution à partir des timestamps associés. Toutefois, bien que le script soit opérationnel, il n’est pas encore dans sa version...
Tour d’horizon du concept de liminalité

Je m’intéresse ici à la notion de liminalité parce qu’elle permet de penser, de manière transversale, ce qui se joue dans les “moments de transition”, les “états instables”, les “seuils de passage” au sein des systèmes humains, sociaux ou cognitifs. Qu’il s’agisse de rites de passage (Van Gennep), de paradoxes relationnels (Bateson)...
Extraction de commentaires YouTube via streamlit
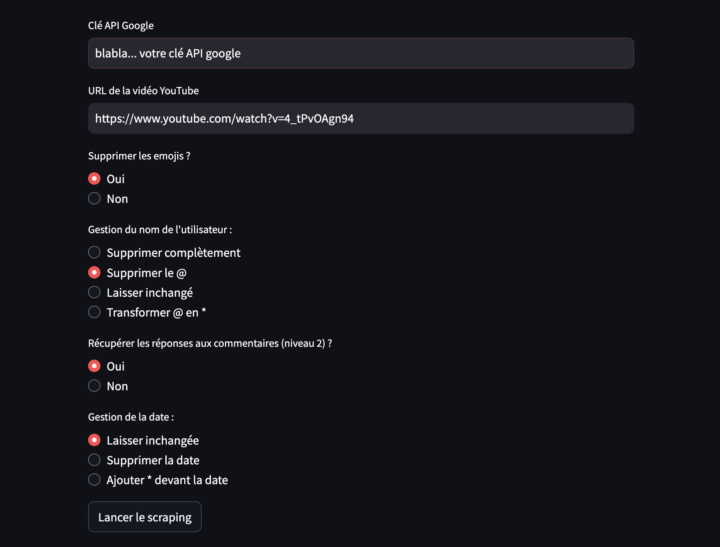
X est devenu le repaire de la désinformation… Alors que Facebook ou Linkedin imposent une API payante pour récupérer leurs posts, il nous reste donc une source – certes également sujette à la désinformation, mais où l’expression demeure spontanée et authentique – celle des commentaires YouTube. Il faut bien l’avouer : certaines vidéos suscitent une avalanche de réactions ! Merci...
Comprendre la CHD et la méthode Reinert
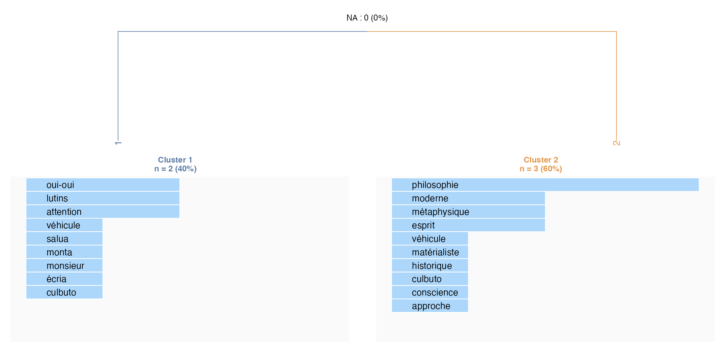
Cet article vise à « reproduire » la démarche statistique (simplifiée) expliquée par Julien Barnier autour de la CHD. Je reprends donc l’exemple et la démarche lors de son excellente intervention sur l’excellente chaîne YouTube Tuto Mate-SHS.L’objectif est de (re)construire un script R (sans utiliser le package “rainette”) qui, à partir des 5 phrases de...
Speech-to-text avec whisper et streamlit cloud

J’ai adapté un script utilisant le modèle Whisper d’OpenAI en une solution “no code” déployée sur Streamlit Cloud. Il suffit de lancer l’URL de l’application et, après un délai de réponse assez long dû aux serveurs de Streamlit Cloud, vous aurez accès à un l’interface qui vous permet de retranscrire vos fichiers MP3 ou, directement, la voix en texte à...
Approche exploratoire des techniques d’embedding et de centralité

Toute bonne chose a une fin… Il était temps de mettre un point final à cet article. Il s’agit ici d’une démarche exploratoire visant à croiser, pour l’analyse textuelle, plusieurs méthodes d’embedding de BERT, une analyse de similarité cosinus et une analyse de centralité (théorie des graphes). Ça fait déjà beaucoup de choses ! Dans l’analyse textuelle, il est...