
Je m’acharne un peu à tester le package “Rainette” de Julien Barnier, qui permet de réaliser des classifications hiérarchiques descendantes (CHD), alors que le logiciel libre de Pierre Ratinaud “IRaMuTeQ”, considéré comme une référence dans ce domaine, propose déjà ces analyses dans une interface « no-code » beaucoup plus accessible !
Nouvelle version du script – 01-08-2025
Cela dit, il est intéressant d’explorer les possibilités de paramétrage offertes par Rainette, notamment pour bien comprendre le fonctionnement de la CHD.
Selon moi, l’un des points faibles de Rainette est la difficulté d’intégration de Shiny pour gérer les paramètres de la CHD, car la fonction rainette_explor() mobilise déjà Shiny pour la visualisation interactive des résultats.
Je n’ai donc pas trouvé la solution pour créer une interface utilisateur gérant les paramètres de la CHD tout en affichant la CHD dans l’explorateur de Shiny (c’est l’un ou l’autre…).
En l’état, l’ensemble des paramétrages doit donc être réalisé directement dans le script R avec Rstudio (attention de ne pas oublier d’enregistrer le script après chaque modification des paramètres avant de lancer l’analyse).
Pour comprendre le principe de fonctionnement de la CHD vous pouvez consulter cet article.
2. Paramétrage de la CHD avant analyse
Voici la partie du script qui permet à l’utilisateur de modifier les paramètres. Je rappelle qu’après chaque modification d’une valeur, il faut enregistrer le script avant de relancer l’analyse.
#########################################################
# PARAMÈTRES UTILISATEUR (modifiable par l'utilisateur)
#########################################################
# Choix du mode de découpage
mode_decoupage <- "segment_size" # "segment_size" ou "ponctuation"
# Taille des segments avant analyse (nombre de mots par segment)
segment_size <- 40
# Nom du fichier texte brut (dans base_dir)
texte_fichier <- "tourisme_surtourisme_1an_presse_nationale.txt"
# Répertoire principal contenant le fichier texte
base_dir <- "/Users/stephanemeurisse/Documents/Cours ISTHIA/Cours ISTHIA 2026/Cours_Analyse_textuelle/"
# Nombre de classes (clusters) pour Rainette
k <- 8
# Nombre minimal de segments de texte par classe pour continuer à diviser
# (évite de créer des classes trop petites)
min_split_segments <- 10
# Seuil minimal de fréquence documentaire dans le DFM
# Exemple : si min_docfreq <- 2 seuls les mots présents dans au moins 2 segments sont gardés
# Les mots présents dans seulement 1 segment sont retirés
min_docfreq <- 4
# Nombre maximal de mots affichés par classe dans les nuages de mots
top_n <- 20
# Répertoire où exporter les résultats
export_dir <- file.path(base_dir, "exports")
dir.create(export_dir, showWarnings = FALSE, recursive = TRUE)
# lemmatisation
lemmatisation <- TRUE # TRUE pour activer la lemmatisation, FALSE sinon
# Liste des formes (UPOS) à conserver lors de la lemmatisation
# Exemple de valeurs : "NOUN" = nom, "ADJ" = adjectif, "VERB" = verbe, "PROPN" = nom propre, "ADV" = adverbe, etc.
# Liste complète UDPipe (UPOS) : "ADJ" (adjectif), "ADP" (adposition), "ADV" (adverbe), "AUX" (auxiliaire),
# "CCONJ" (conjonction de coordination), "DET" (déterminant), "INTJ" (interjection), "NOUN" (nom),
# "NUM" (numéral), "PART" (particule), "PRON" (pronom), "PROPN" (nom propre), "PUNCT" (ponctuation),
# "SCONJ" (conjonction de subordination), "SYM" (symbole), "VERB" (verbe), "X" (autre, inconnu)
upos_a_conserver <- c("NOUN", "ADJ") # Modifier ici selon vos besoins
Attention, le script a été testé avec un corpus initialement formaté pour IRaMuTeQ (qui accepte un format assez strict), mais c’est justement l’une des forces de Rainette de pouvoir importer un fichier texte contenant, en tête, des lignes de variables étoilées, comme ceux prévus pour IRaMuTeQ.
Le corpus html provenant du site Europresse a été préalablement traité à l’aide de ce script, déployé en ligne sur les serveurs de Streamlit Cloud, pour le transformer au format texte.
Il faut simplement réactiver le serveur (ce qui prend environ une minute) pour pouvoir ensuite intégrer un fichier Europresse au format HTML et laisser le script le convertir automatiquement en fichier texte (format IRaMuTeQ).
Le fichier utilisé est disponible ici. Il contient 1000 articles provenant d’Europresse, ce qui permet de tester la robustesse du script. Attention, ce fichier n’a subi qu’un nettoyage (très) succinct.
2.1 Choix du mode de découpage
Un point clé de l’analyse textuelle automatisée concerne la manière dont le corpus est découpé en segments élémentaires avant la classification.
Dans le script, ce découpage est contrôlé par le paramètre mode_decoupage, qui peut prendre la valeur "segment_size" ou "ponctuation".
# Choix du mode de découpage mode_decoupage <- "segment_size" # "segment_size" ou "ponctuation"
Lorsque l’on choisit "segment_size", chaque segment est constitué d’un nombre fixe de mots, défini par le paramètre segment_size (par exemple, 40 mots par segment).
# Taille des segments avant analyse (nombre de mots par segment) segment_size <- 40 #exemple
Le mode "ponctuation" propose un découpage basé sur la “phrase”, c’est-à-dire que chaque segment correspond à une phrase détectée à partir de la ponctuation.
Ce mode est intéressant lorsque l’on souhaite conserver la structure syntaxique naturelle du texte, mais j’avoue que ce paramètre ne m’a pas donné satisfaction dans mes tests.
Je vous déconseille pour le moment d’utiliser ce mode.
2.2 Nom du fichier texte et répertoire
Le paramètre texte_fichier spécifie le nom du fichier au format .txt qui sera analysé. Ici, le fichier utilisé s’intitule “tourisme_surtourisme_1an_presse_nationale.txt”.
# Nom du fichier texte brut (dans base_dir) texte_fichier <- "tourisme_surtourisme_1an_presse_nationale.txt" # Répertoire principal contenant le fichier texte base_dir <- "/Users/stephanemeurisse/Documents/Cours ISTHIA/Cours ISTHIA 2026/Cours_Analyse_textuelle/"
Ce fichier doit être placé dans le dossier défini par base_dir.
2.3 Nombre de classes (k)
Le paramètre k correspond au nombre de classes ou clusters demandés à l’algorithme Rainette.
# Nombre de classes (clusters) pour Rainette k <- 6
Ici, j’ai fixé la valeur à 6, mais ce choix doit être guidé par les résultats de votre corpus et par un tâtonnement expérimental.
Sachez que si vous définissez k = 8 dans l’interface de rainette, vous aurez toujours la possibilité de diminuer “à la volée” le nombre de classes directement dans l’interface. En revanche, les graphiques et les nuages de mots exportés seront basés sur la valeur de k définie dans le script.
2.4 Nombre minimal de segments de texte par classe
Le paramètre min_split_segments fixe le nombre minimal de segments qu’une classe doit contenir pour pouvoir être subdivisée.
# Nombre minimal de segments de texte par classe pour continuer à diviser # (évite de créer des classes trop petites) min_split_segments <- 10
Ce paramètre détermine quand l’algorithme doit s’arrêter de diviser un groupe.
2.5 Seuil minimal de fréquence documentaire dans le DFM
Le paramètre min_docfreq contrôle l’épuration du dictionnaire de termes.
# Seuil minimal de fréquence documentaire dans le DFM # Exemple : si min_docfreq <- 2 seuls les mots présents dans au moins 2 segments sont gardés # Les mots présents dans seulement 1 segment sont retirés min_docfreq <- 1
Par exemple, en fixant min_docfreq à 2, seuls les mots présents dans au moins deux segments du corpus sont conservés.
Ce paramètre permet de réduire le “bruit” dû aux mots rares ou isolés.
2.6 Nombre maximal de mots affichés par classe dans les nuages de mots (top_n)
Le paramètre top_n permet de limiter le nombre de termes affichés dans les nuages de mots générés pour chaque classe.
# Nombre maximal de mots affichés par classe dans les nuages de mots top_n <- 20
2.7 Répertoire où exporter les résultats
export_dir est le chemin du répertoire où tous les fichiers de sortie (segments.txt, nuages de mots, concordancier.html) seront exportés.
Le script crée automatiquement ce dossier s’il n’existe pas.
2.8 Choix les formes grammaticales à analyser
Dans le script, un paramètre important permet de choisir les formes grammaticales que l’on souhaite conserver pour l’analyse, grâce à la variable upos_a_conserver.
Ce paramètre s’appuie sur l’annotation UPOS fournie par l’outil UDPipe lors de la lemmatisation ou du POS-tagging. UPOS signifie Universal Part-of-Speech, c’est-à-dire la catégorisation des mots selon leur rôle grammatical : nom (NOUN), adjectif (ADJ), verbe (VERB), nom propre (PROPN), adverbe (ADV), …
# Liste des formes (UPOS) à conserver lors de la lemmatisation # Exemple de valeurs : "NOUN" = nom, "ADJ" = adjectif, "VERB" = verbe, "PROPN" = nom propre, "ADV" = adverbe, etc.
# Liste complète UDPipe (UPOS) : "ADJ" (adjectif), "ADP" (adposition), "ADV" (adverbe), "AUX" (auxiliaire),
# "CCONJ" (conjonction de coordination), "DET" (déterminant), "INTJ" (interjection), "NOUN" (nom),
# "NUM" (numéral), "PART" (particule), "PRON" (pronom), "PROPN" (nom propre), "PUNCT" (ponctuation),
# "SCONJ" (conjonction de subordination), "SYM" (symbole), "VERB" (verbe), "X" (autre, inconnu)
upos_a_conserver <- c("NOUN", "ADJ") # Modifier ici selon vos besoins
Ce paramètre permet de filtrer très précisément les mots à inclure dans la matrice d’analyse. Par exemple, en ne conservant que les noms et les adjectifs (upos_a_conserver <- c("NOUN", "ADJ")), on évite de faire intervenir les déterminants, pronoms, conjonctions, ou la ponctuation dans la classification et les nuages de mots.
Cette notion de UPOS est l’équivalent du POS-tagging (Part-of-Speech tagging) utilisé dans le NLP.
La liste complète des catégories UPOS inclut notamment : ADJ (adjectif), ADP (adposition), ADV (adverbe), AUX (auxiliaire), CCONJ (conjonction de coordination), DET (déterminant), INTJ (interjection), NOUN (nom), NUM (numéral), PART (particule), PRON (pronom), PROPN (nom propre), PUNCT (ponctuation), SCONJ (conjonction de subordination), SYM (symbole), VERB (verbe), X (autre, inconnu).
3. Lemmatisation avec udipipe
La lemmatisation permet de ramener chaque mot à sa forme canonique, par exemple « mangé », « mangeons », « mangeais » deviennent tous « manger ».
Cette “normalisation” réduit la dispersion lexicale et évite que des formes grammaticales différentes soient comptées comme des termes séparés dans les analyses statistiques.
Dans la pratique, cette partie du script fonctionne correctement. Cependant, une limite apparaît lors de l’export des segments par classe : le texte exporté est celui issu directement de la lemmatisation.
Cela donne un texte lisible, mais plus rugueux et appauvri sur le plan stylistique, puisque les formes originales ont été remplacées par leurs lemmes. Ce point est à améliorer et pour le moment je déconseille d’utiliser la lemmatisation.

En comparaison, le logiciel IRaMuTeQ gère beaucoup mieux cet aspect, car ils permet de conserver le texte original pour l’affichage des segments de texte.
3.1 Fonctionnement de la lemmatisation
Dans le script, udpipe joue un rôle dans le prétraitement linguistique des textes.
Concrètement, udpipe est une bibliothèque qui réalise plusieurs tâches d’analyse automatique de texte : elle segmente les phrases, identifie les mots (tokenisation), leur attribue une catégorie grammaticale (part-of-speech tagging), et détermine pour chaque mot son lemme, (par exemple : “mangé”, “mangeons”, “mangeais” deviennent tous “manger”).
# Chemin du modèle UDPipe français
modele_udpipe <- "french-gsd-ud-2.5-191206.udpipe"
if (!file.exists(modele_udpipe)) {
cat("Téléchargement du modèle UDPipe français...\n")
udpipe_download_model(language = "french", model_dir = ".", overwrite = FALSE)
}
ud_model <- udpipe_load_model(modele_udpipe)
L’étape de lemmatisation via udpipe permet ainsi de normaliser les textes et de réduire les variations morphologiques qui disperseraient inutilement l’analyse statistique.
4. Processus de filtrage : stopwords
Dans ce script, le traitement des stopwords intervient lors de la préparation des tokens, juste avant la construction de la matrice documentaire (DFM).
L’élimination des stopwords (mots outils) est une étape essentielle dans le prétraitement d’un corpus en analyse textuelle.
Ces mots très fréquents (par exemple : “le”, “de”, “à”, “mais”, “pour”, etc.) n’apportent généralement pas d’information discriminante pour l’analyse.
tok <- tokens(corpus_lemmat, remove_punct = TRUE, remove_numbers = TRUE)
tok <- tokens_remove(tok, stopwords("fr"))
tok <- tokens_split(tok, "'")
tok <- tokens_remove(tok, pattern = c("\\b[a-zA-Z]\\b", "^[^a-zA-Z]+$"), valuetype = "regex")
tok <- tokens_tolower(tok)
4.1 Tokenisation initiale
tok <- tokens(corpus_lemmat, remove_punct = TRUE, remove_numbers = TRUE)
Le texte est découpé en tokens (mots), en supprimant la ponctuation et les chiffres. On obtient ainsi une première segmentation en “mots”.
4.2 Suppression des stopwords
tok <- tokens_remove(tok, stopwords("fr"))
À cette étape, tous les mots de la liste des stopwords français prédéfinis par la bibliothèque quanteda sont retirés des tokens.
4.3 Découpage sur l’apostrophe
tok <- tokens_split(tok, "'")
Ici, chaque token contenant une apostrophe est découpé. Par exemple, “c’est” devient “c” et “est”, “j’ai” devient “j” et “ai”.
Cela permet de traiter correctement les contractions fréquentes en français.
4.4 Suppression des tokens non informatifs ou bruités
tok <- tokens_remove(tok, pattern = c("\\b[a-zA-Z]\\b", "^[^a-zA-Z]+$"), valuetype = "regex")
On élimine les tokens d’un seul caractère (ex : “l”, “d”, “j”, … , restes des contractions) et les tokens qui ne comportent que des signes ou des caractères non alphabétiques (ex : “+”, “-“, …).
4.5 Passage en minuscules
tok <- tokens_tolower(tok)#minuscules
Enfin, on convertit tous les tokens restants en minuscules. Cela garantit que « Ariège » et « ariège » soient traités comme le même mot.
5. Export des nuages de mots
L’export des nuages de mots basé sur la statistique du chi² permet de visualiser les termes les plus discriminants pour chaque classe issue de la classification.
Le calcul du chi² utilisé lors de l’export est paramétrable (nombre de termes, p-value directement dans le script R), tandis que dans Rainette on ne peut pas appliquer ses propres filtres.
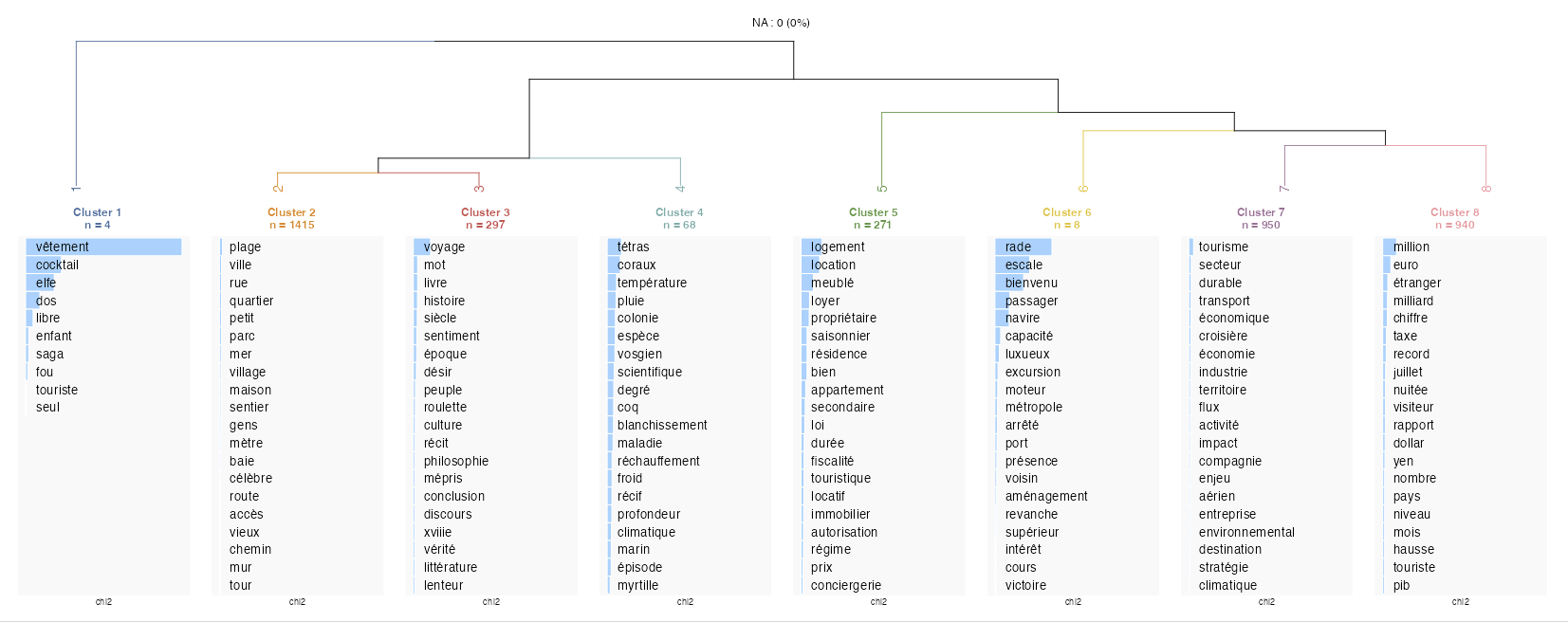
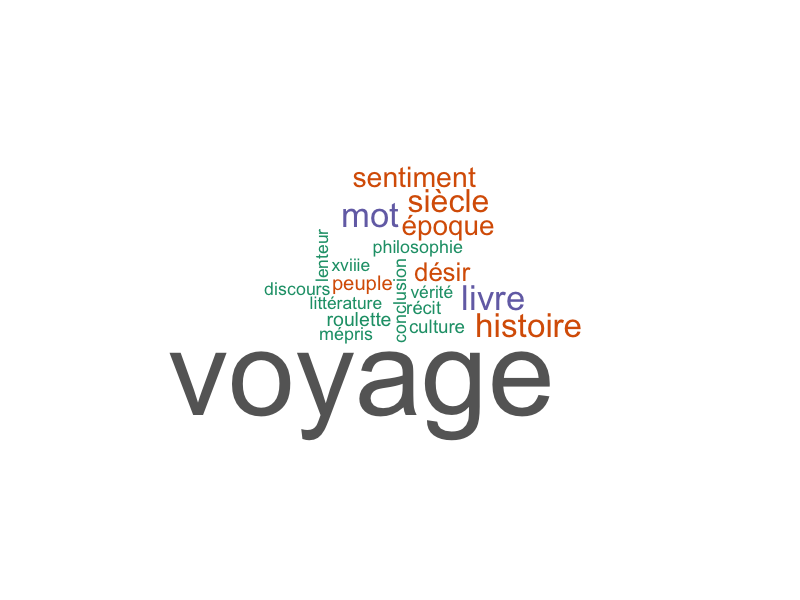
Conclusion
Ce script constitue une base de travail pour la classification hiérarchique descendante de textes avec Rainette.
Il offre déjà de nombreuses fonctionnalités paramétrables.
Cependant, plusieurs axes d’amélioration restent à explorer. En particulier, le développement d’un concordancier plus lisible. La question de la segmentation par ponctuation demande également à être approfondie.
Enfin, si les tests sont concluants, une interface graphique pour le paramétrage de la CHD pourra être envisagée.
Dernier point : il serait judicieux de comparer les résultats produits par Rainette et ceux d’IRAMUTEQ sur la base du même corpus.