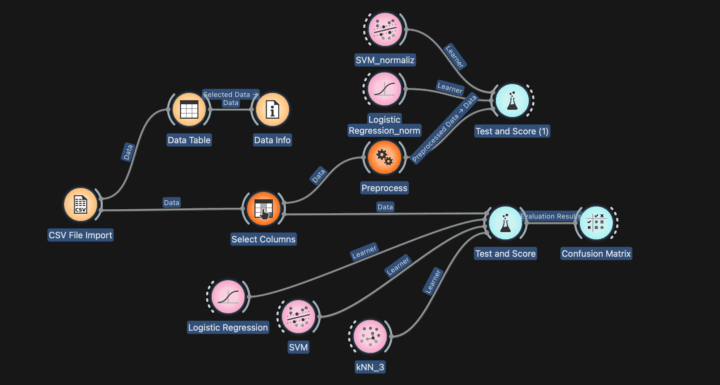
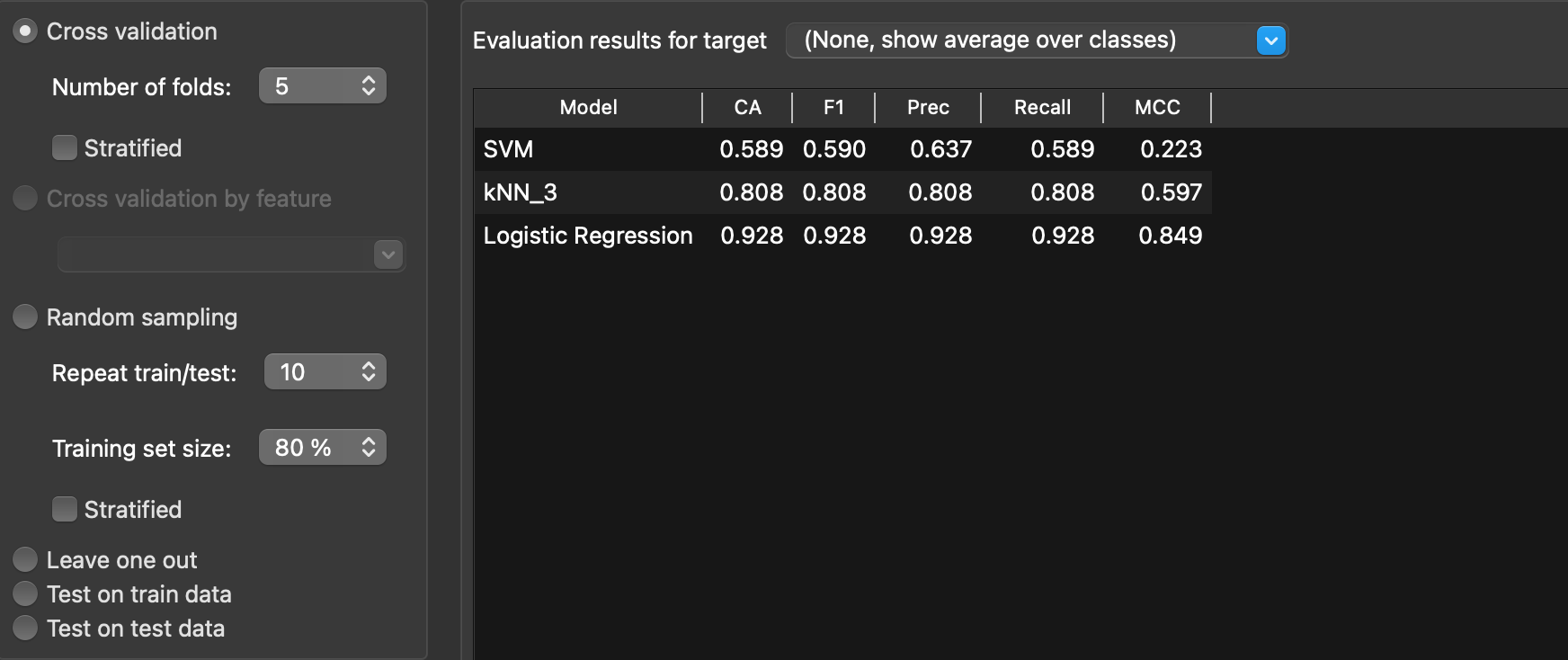
L’objectif ici est d’utiliser le logiciel Orange Data Mining pour prédire si un mail doit être classé « spam » ou « non-spam » à partir du dataset Spambase, et pour mesurer/comparer la performance de trois modèles de classification supervisée : SVM, régression logistique, kNN.
L’intérêt d’Orange Data mining est de permettre, par simple enchaînement de widgets de construire un workflow reproductible pour entraîner les modèles, prédire sur les données de test et évaluer leurs précisions (accuracy).

Le fichier spambase.csv ne contient pas les messages bruts mais uniquement les caractéristiques numériques déjà extraites à partir des e-mails.Les textes ne sont pas fournis. On travaille donc directement sur les « scores » de chaque caractéristiques pour entraîner le(s) modèle(s) et prédire le score binaire : « spam » ou « non-spam ».
1. Constitution du dataset spambase
Intéressons nous rapidement au dataset.
Le dataset Spambase contient 4601 messages (observations / instances / individus) et 57 caractéristiques pour chacune de ces observations, plus l’étiquette/label de prédiction (y) binaire : spam/non-spam.
Les 57 caractéristiques explicatives peuvent être regroupées en 3 catégories.
On se situe ici dans un cadre d’apprentissage supervisé : le modèle est entraîné à partir des caractéristiques extraites de chaque message et annoté à la cible “y” (spam/non spam), puis il prédit (y) la classe pour de nouveaux messages.
La première catégorie regroupe 48 caractéristiques notées word_freq_WORD : pour chaque mot prédéfini, on mesure le pourcentage de mots du message qui correspondent à ce mot.
La seconde catégorie comprend 6 caractéristiques notées char_freq_CHAR : il s’agit du pourcentage de caractères du message appartenant à un caractère donné, en pratique le point-virgule “;“, la parenthèse ouvrante ” ( “, le crochet ouvrant “[ “, le point d’exclamation “!“, le symbole “$” et le dièse “#“.
La troisième catégorie rassemble 3 caractéristiques liées aux séquences de lettres majuscules : capital_run_length_average, qui mesure la longueur moyenne des séquences continues de majuscules, capital_run_length_longest, qui est la longueur de la plus longue séquence continue, et capital_run_length_total, qui est la somme des longueurs de toutes les séquences, équivalente au nombre total de lettres en majuscules dans l’e-mail.

Exemples : La caractéristique word_freq_free mesure la part de mots “free” dans l’e-mail ; une valeur de 2,0 signifie que 2 % des mots sont ” free “. La variable char_freq_! égale à 5,0 signifie que 5 % des caractères du message sont des “!“.
Si capital_run_length_longest vaut 40, on observe au moins une séquence de 40 lettres consécutives en majuscules, signe fréquent de messages publicitaires.
C’est une observation statistique propre au corpus Spambase, pas une vérité universelle sur tous les e-mails.
2. Les modèles
2.1 k-Nearest Neighbors (k-NN)
Idée de base: pour un e-mail à classer, on cherche ses k voisins les plus proches dans l’espace des observations.
L’algorithme du Nearest Neighbors nécessite de garder en mémoire tous les points du jeu de données pour calculer la distance entre ces points et un nouveau point dont on souhaite faire une prédiction (spam/no spam).
Pour cela, on calcule la distance entre ce point et tous les autres points du jeu de données. On utilise la distance euclidienne. On attribue ainsi un point à la même classe que son plus proche voisin. On généralise cette opération à tous les points de notre espace, ce qui permet de déterminer une frontière de décision, c’est-à-dire la frontière qui sépare les deux classes.
Dans sa forme la plus simple, l’algorithme du plus proche voisin, dans sa version à 1 voisin, n’est pas la plus efficace. On utilise généralement les k-voisins plus proches, pour ensuite assimiler notre point à la classe majoritaire parmi ces k-voisins.
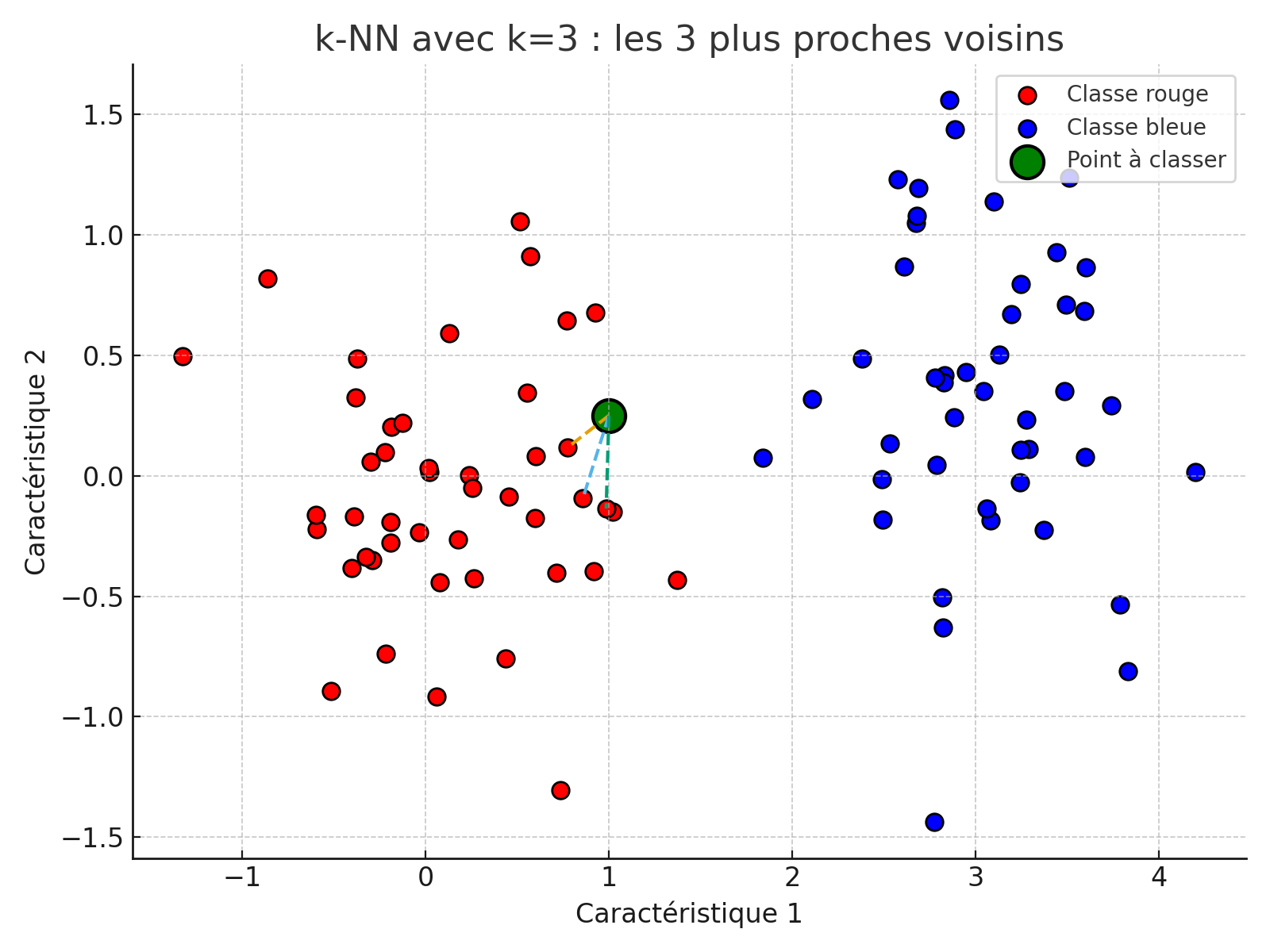
Un exemple avec k=3. Ici, notre point compte parmi ses 3 voisins les plus proches, 3 points de la classe spam (rouge). Il est donc (logiquement) assimilé à la classe “spam” (rouge).
2.2 Régression logistique
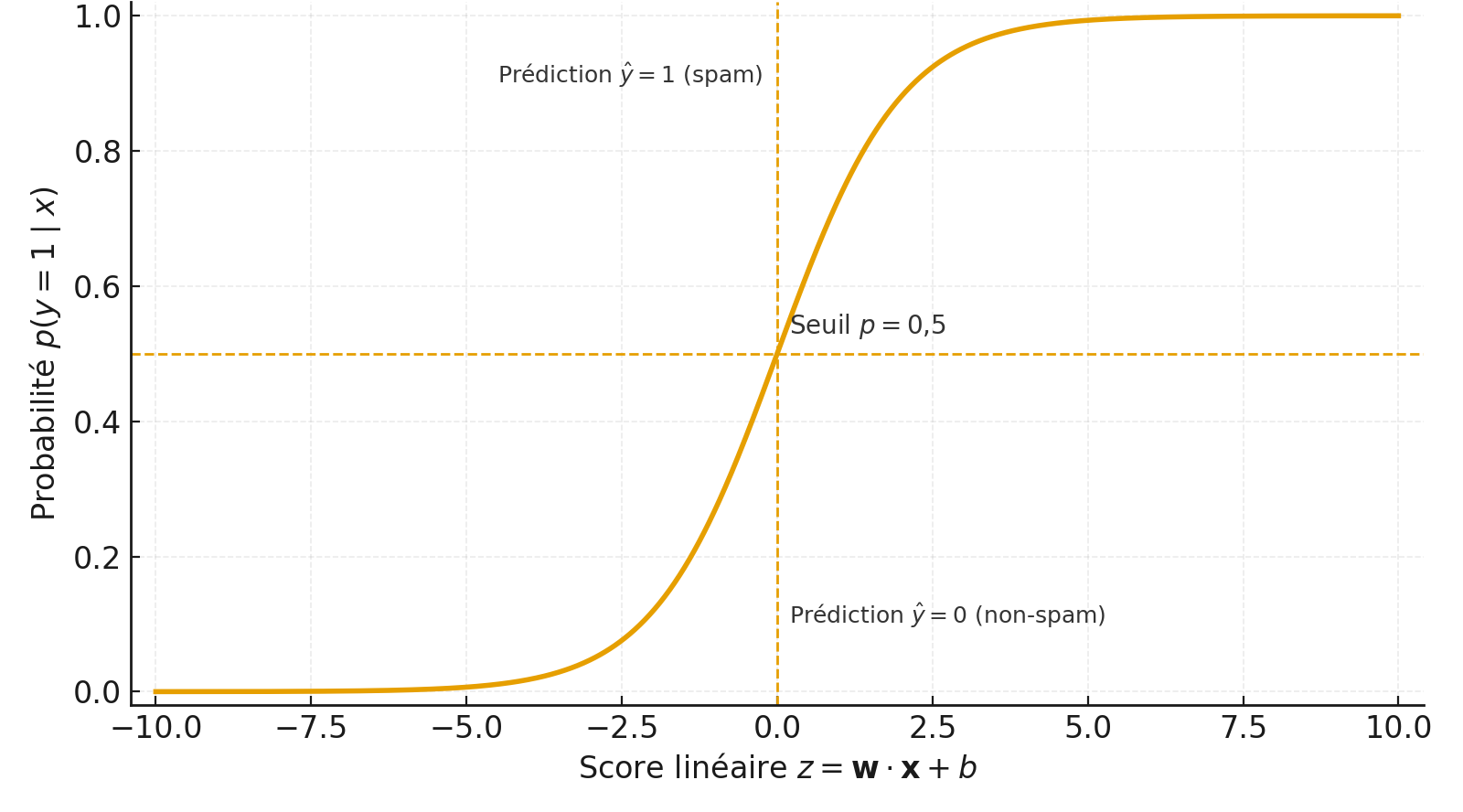
Idée de base : La régression logistique sert à prédire une étiquette binaire, notée 0 ou 1.
On l’utilise quand on veut décider entre deux états par exemple « spam » ou « non-spam », « tumeur maligne » ou « bénigne »…
La régression logistique est donc un modèle de classification binaire qui calcule la probabilité qu’un e-mail appartienne à la classe “spam”.
Ici le modèle apprend à partir d’exemples étiquetés à reconnaître des combinaisons de caractéristiques (features) qui augmentent ou diminuent la probabilité d’appartenir à la classe 1 (spam).
Pour chaque observation, elle applique une fonction logistique (sigmoïde) pour transformer une combinaison linéaire des caractéristiques en une probabilité comprise entre 0 et 1.
Si cette probabilité dépasse un certain seuil, l’email est classé comme spam.
C’est souvent un des premiers modèles testés en classification binaire.
2.3 SVM (Support Vector Machine)
Idée de base: trouver une frontière qui sépare au mieux spam et non-spam en maximisant la “marge”.
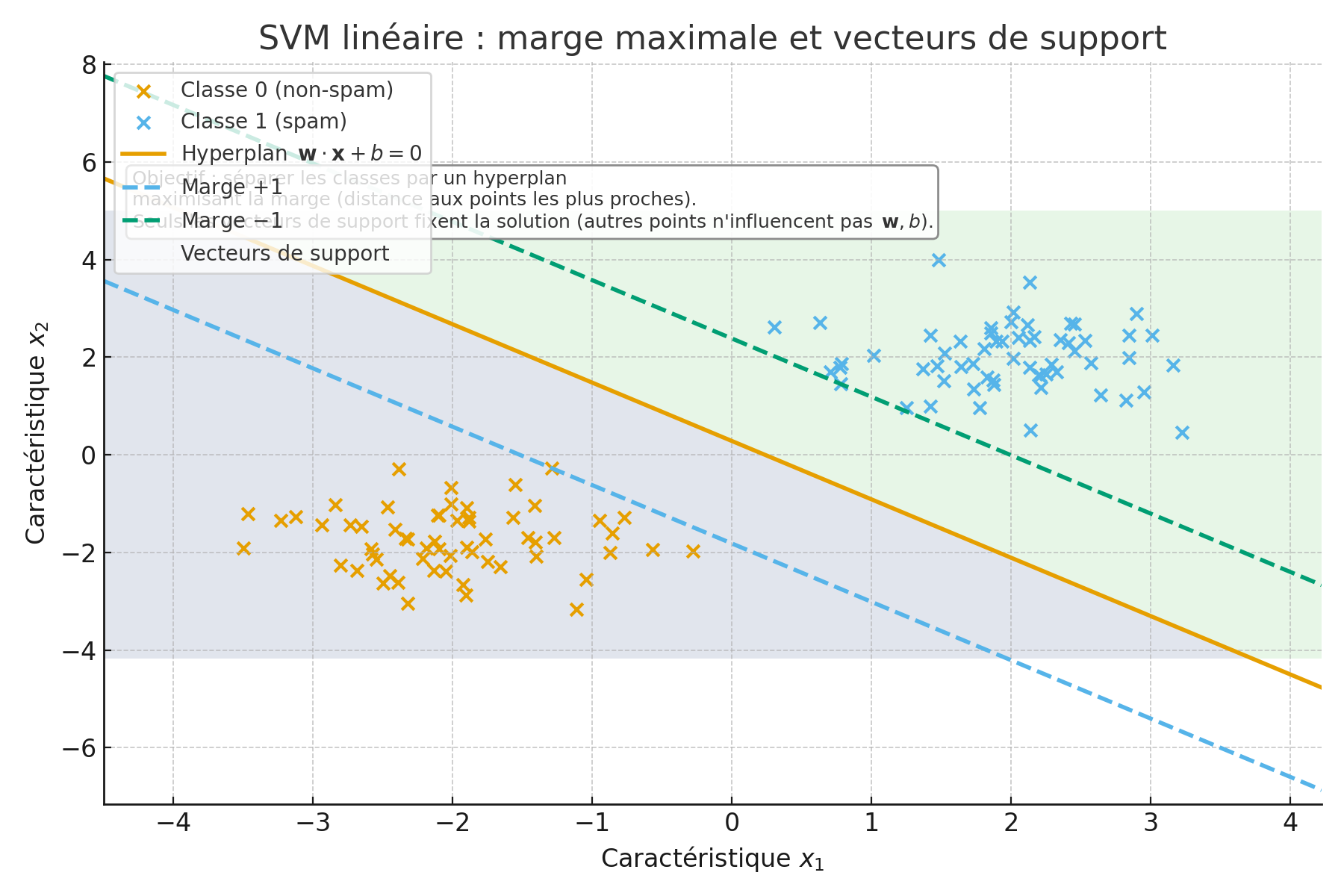 Un SVM cherche une frontière qui sépare deux classes en maximisant la marge, c’est-à-dire la distance entre la frontière et les points les plus proches de chaque classe, appelés vecteurs de support.
Un SVM cherche une frontière qui sépare deux classes en maximisant la marge, c’est-à-dire la distance entre la frontière et les points les plus proches de chaque classe, appelés vecteurs de support.
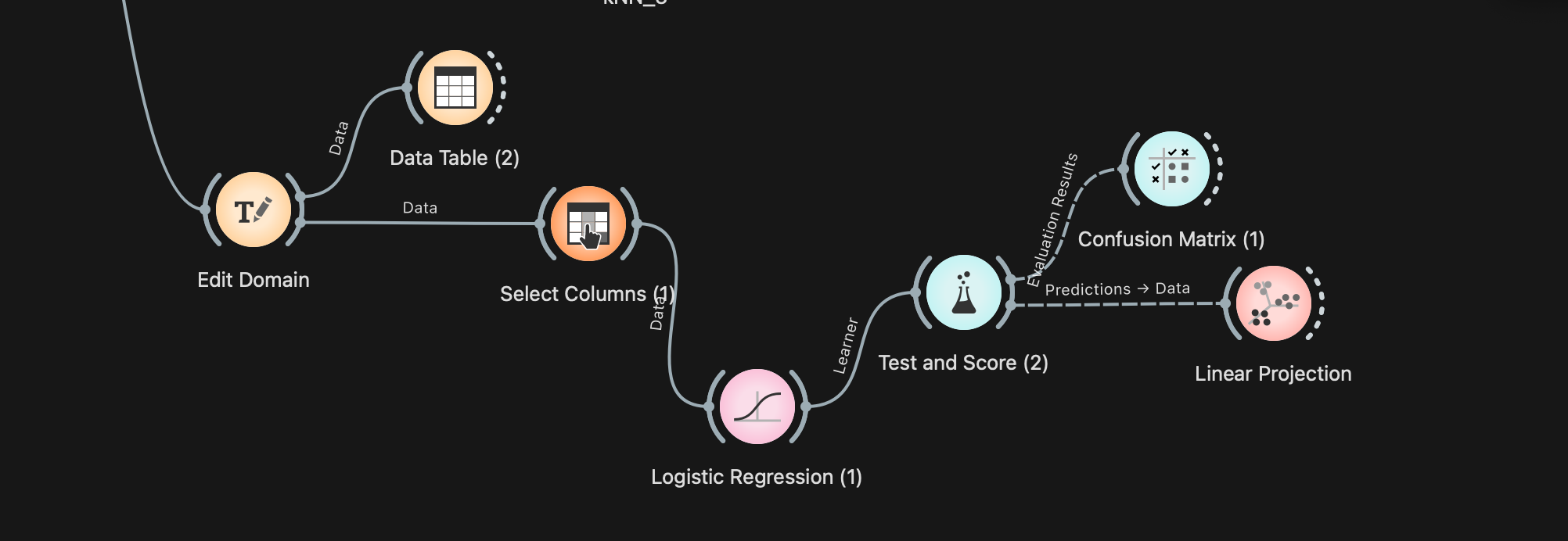
3. Contexte Spambase + Orange
Dans Orange Data Mining, l’enchaînement type consiste à charger la base, éventuellement nettoyer/normaliser, brancher des classifieurs (ici : regression logistique – svm – knn), puis évaluer avec Test & Score, Confusion Matrix…
Une image me semble plus parlante pour comprendre les connexions entre les widgets 😉
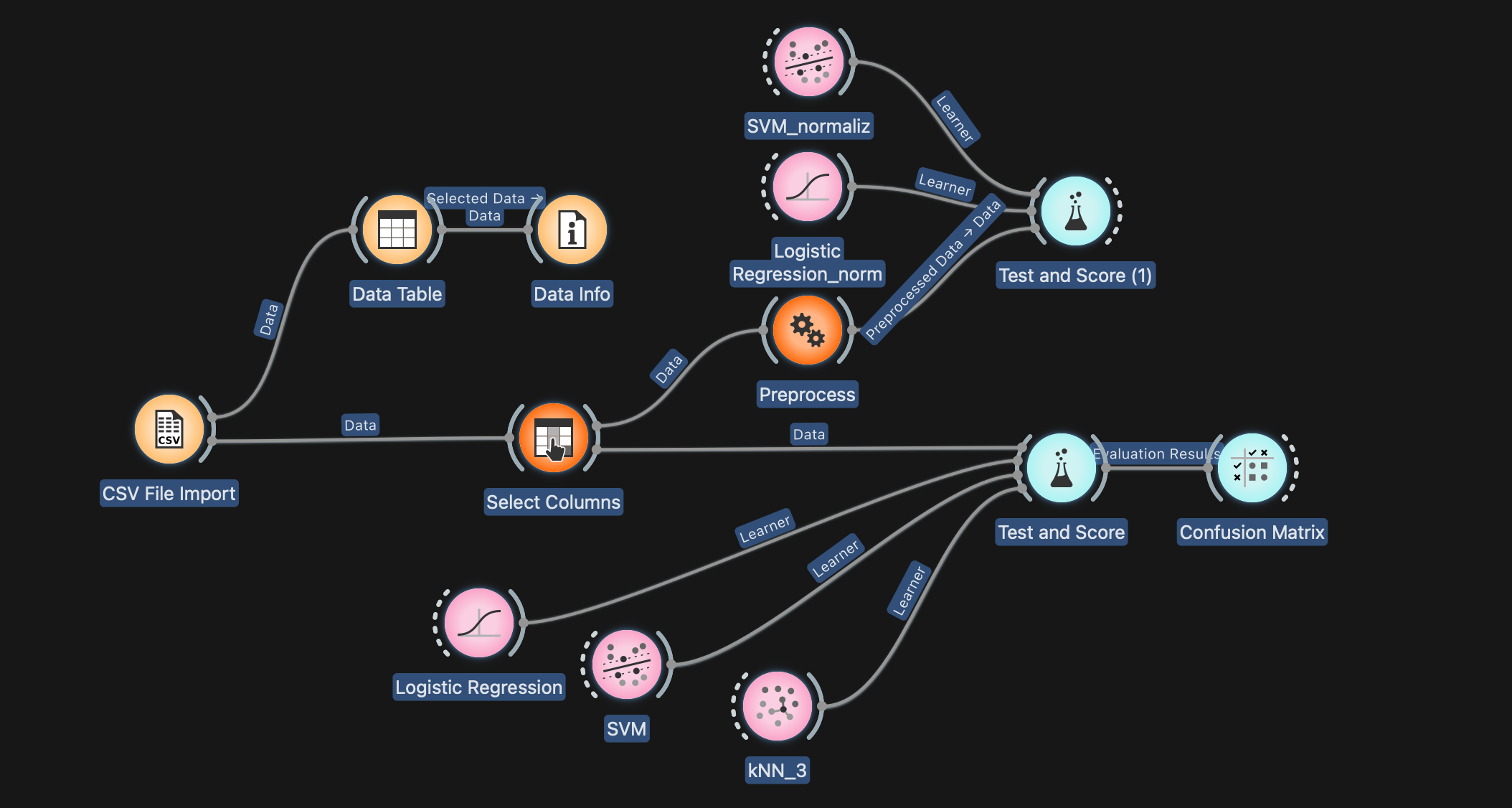
4. Normalisation avec Orange Data Mining
Dans Orange Data mining il est possible d’ajouter le widget Preprocess afin de normaliser les données.
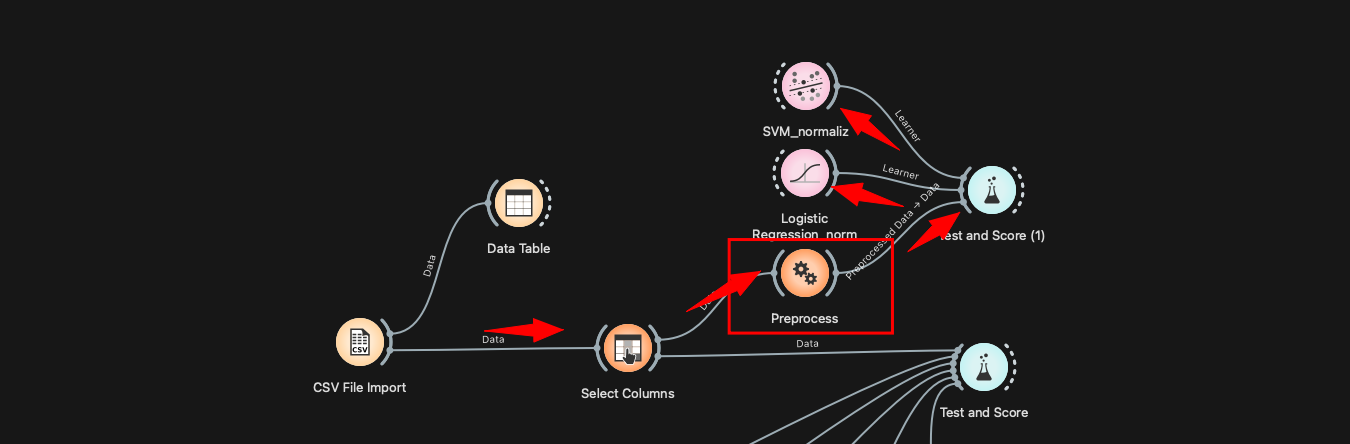
Il est souhaitable de normaliser le dataset parce que les caractéristiques des observations n’ont pas la même échelle. Dans le dataset Spambase, certaines colonnes sont des fréquences en pourcentage, d’autres des comptes (longueurs de séquences de caractères,..).
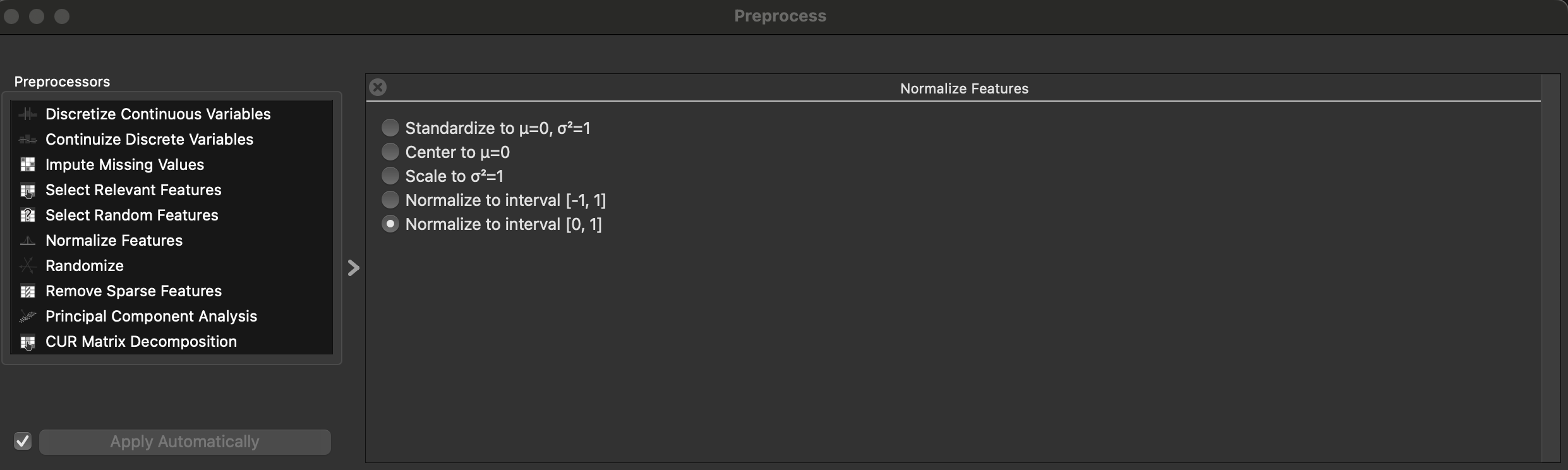
kNN et SVM s’appuyant sur des notions de distance ou de marge dans l’espace des observations/caractéristiques. Si une variable varie entre 0 et 10 000 et une autre entre 0 et 1, la première écrase la distance euclidienne et oriente la frontière de décision.
En normalisant, on “met chaque variable au même poids de départ”.
5. Les métrics (évaluation)
Par défaut, dans Orange Data Mining, l’option « Cross validation » (validation croisée) est cochée. Cela veut dire que le dataset est découpé en “k” parts de taille comparable. On entraîne le modèle sur k parts et on le teste sur la part restante. On recommence k fois en changeant la part qui sert de test, puis on fait la moyenne des résultats.
Ainsi, chaque mail a servi une fois au test et plusieurs fois à l’apprentissage, ce qui donne une estimation plus stable qu’un seul découpage 80/20 classiquement utilisé.
Quand l’option « stratified » est active, chaque “part” respecte la même proportion de classes (spam/non-spam) que le jeu complet.
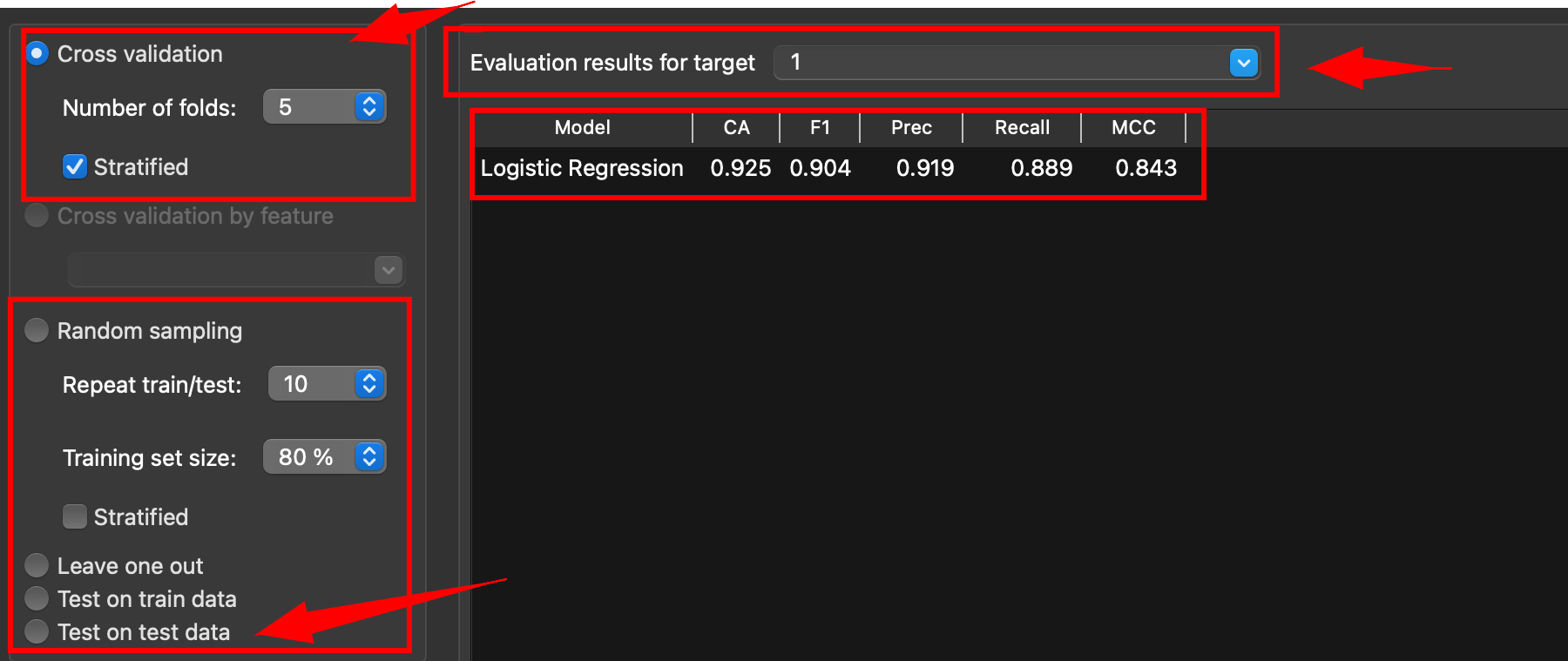
5.1 Cross-validation
Procédure d’évaluation où l’on découpe le jeu de données en plusieurs parts, on entraîne sur certaines parts et on teste sur la part restante, puis on recommence en changeant la part test.
On moyenne ensuite les résultats pour obtenir une estimation plus fiable qu’un seul découpage 80/20.
5.2 Stratification
Façon de faire les découpages en conservant la même proportion de chaque classe (ex. spam/non-spam) dans chaque part.
Cela évite qu’un pli contienne trop peu d’exemples d’une classe et stabilise les métriques.
5.4 Fold (pli ou split)
À chaque itération, un pli/split sert de test et les autres servent d’entraînement. Par exemple en “5-fold”, cela signifie que, à chaque itération, environ 20 % des données servent de test et 80 % d’apprentissage, et l’algorithme répète l’opération 5 fois en changeant le bloc test.
5.5 Matrice de confusion
La matrice de confusion permet de vérifier les scores de la régression logistique (ou d’une autre méthode de classification).

On peut lire les totaux par classe dans la matrice de confusion (somme de la ligne “ACTUAL”).
On retrouve 1813 spams (TP+FN) et 2788 non-spams (TN+FP), soit 1813/4601 = 39,4 % de spams et 2788/4601 = 60,6 % de non-spams.
Le dataset n’est pas parfaitement équilibré (50/50).
5.6 Comprendre le widget score and test
Voici les éléments qui permettent de comprendre comment les scores sont calculés (matrice de confusion (lignes = Réel, colonnes = Prédiction par le modèle)
| Prédict = 0 (non-spam) |
Prédict = 1 (spam) |
Total réel | |
|---|---|---|---|
| Réel = 0 (non-spam) | TN | FP | TN + FP |
| Réel = 1 (spam) | FN | TP | FN + TP |
| Total prédit | TN + FN | FP + TP | N = TN + FP + FN + TP |
voici la légende complète (classe positive = 1 = spam) :
- TP = « vrais positifs » = spams correctement prédits spam
- FN = « faux négatifs » = spams à tort prédits non-spam
- FP = « faux positifs » = non-spams à tort prédits spam
- TN = « vrais négatifs » = non-spams correctement prédits non-spam
5.6.1 Accuracy (CA)
Accuracy (exactitude) : part de prédictions correctes sur l’ensemble des mails.
L’accuracy mesure la proportion totale de prédictions correctes sur l’ensemble des mails. Elle donne une vue globale, simple à lire et à comparer entre modèles. Quand les classes sont à peu près équilibrées et que le coût des erreurs est symétrique, c’est un indicateur pertinent pour un premier tri des modèles.

TP = « vrais positifs » = spams correctement prédits spam
TN = « vrais négatifs » = non-spams correctement prédits non-spam.
N = Nombre total d’observations/instances
Utile pour une vision globale, mais peut masquer un déséquilibre entre classes.
5.6.2 Précision (Prec)
Précision : parmi ce que le modèle a marqué « spam », proportion qui est vraiment du spam.
Parmi les mails que le modèle a marqués « spam », quelle proportion est vraiment du spam. Elle baisse quand on a beaucoup de faux positifs.
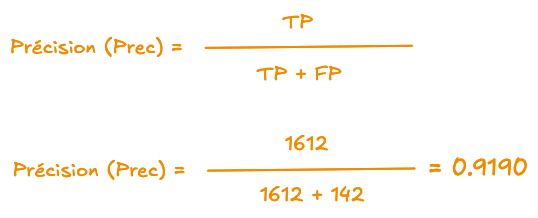
TP = « vrais positifs » = spams correctement prédits spam
FP = « faux positifs » = non-spams à tort prédits spam
5.6.3 Recall (= Rappel)
Rappel (Recall) : parmi tous les spams réels, proportion bien détectée comme spam.
Parmi tous les spams réels, quelle proportion le modèle a bien détectée. Il baisse quand on laisse passer des spams (faux négatifs).
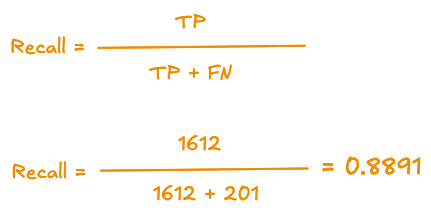
TP = « vrais positifs » = spams correctement prédits spam
FN = « faux négatifs » = spams à tort prédits en non-spam
5.6.4 Score F1
F1 : moyenne harmonique de la précision et du rappel ; élevé seulement si les deux sont bonnes.
Le F1-score sert à résumer en un seul score le compromis entre précision (prec) et recall (rappel). Il est utile dès que l’on souhaite éviter les faux positifs et de ne pas rater de vrais positifs.

Comme il s’agit d’une moyenne, le F1 ne peut être élevé que si précision et recall sont toutes deux bonnes ; une seule des deux métriques élevée ne suffit pas. Ainsi, si un modèle a une précision de 0,95 mais un rappel de 0,50, le F1 chute à 0,65, ce qui reflète bien que le modèle « rate » beaucoup de spams.
5.6.5 MCC (Matthews Correlation Coefficient)
Le MCC (Matthews Correlation Coefficient) est une mesure de corrélation entre les prédictions et la vérité/réalité.
Contrairement à l’accuracy, le MCC ne se laisse pas tromper par une classe majoritaire : il “récompense” les modèles qui sont “bons” à la fois sur les positifs et sur les négatifs.
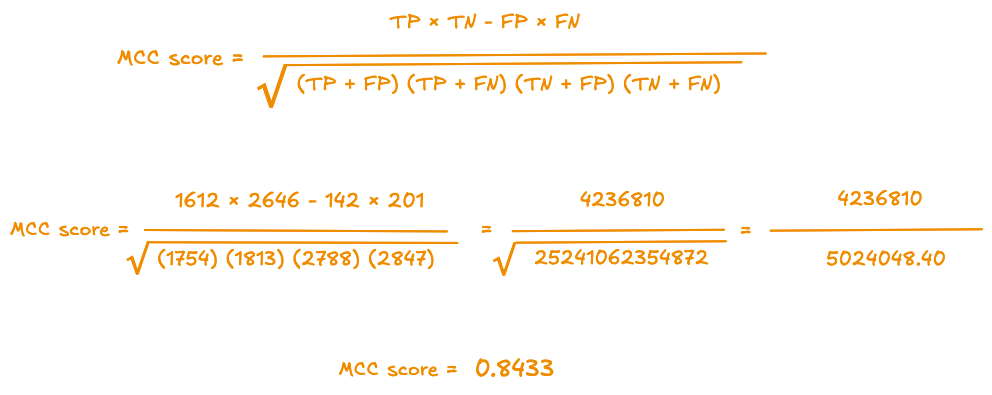
C’est une corrélation entre vraies étiquettes et prédictions, qui tient compte des quatre types de cas (vrais/faux positifs et négatifs). Il varie de −1 (tout faux) à 0 (au hasard) à 1 (parfait). C’est un bon résumé quand les classes ne sont pas parfaitement équilibrées.
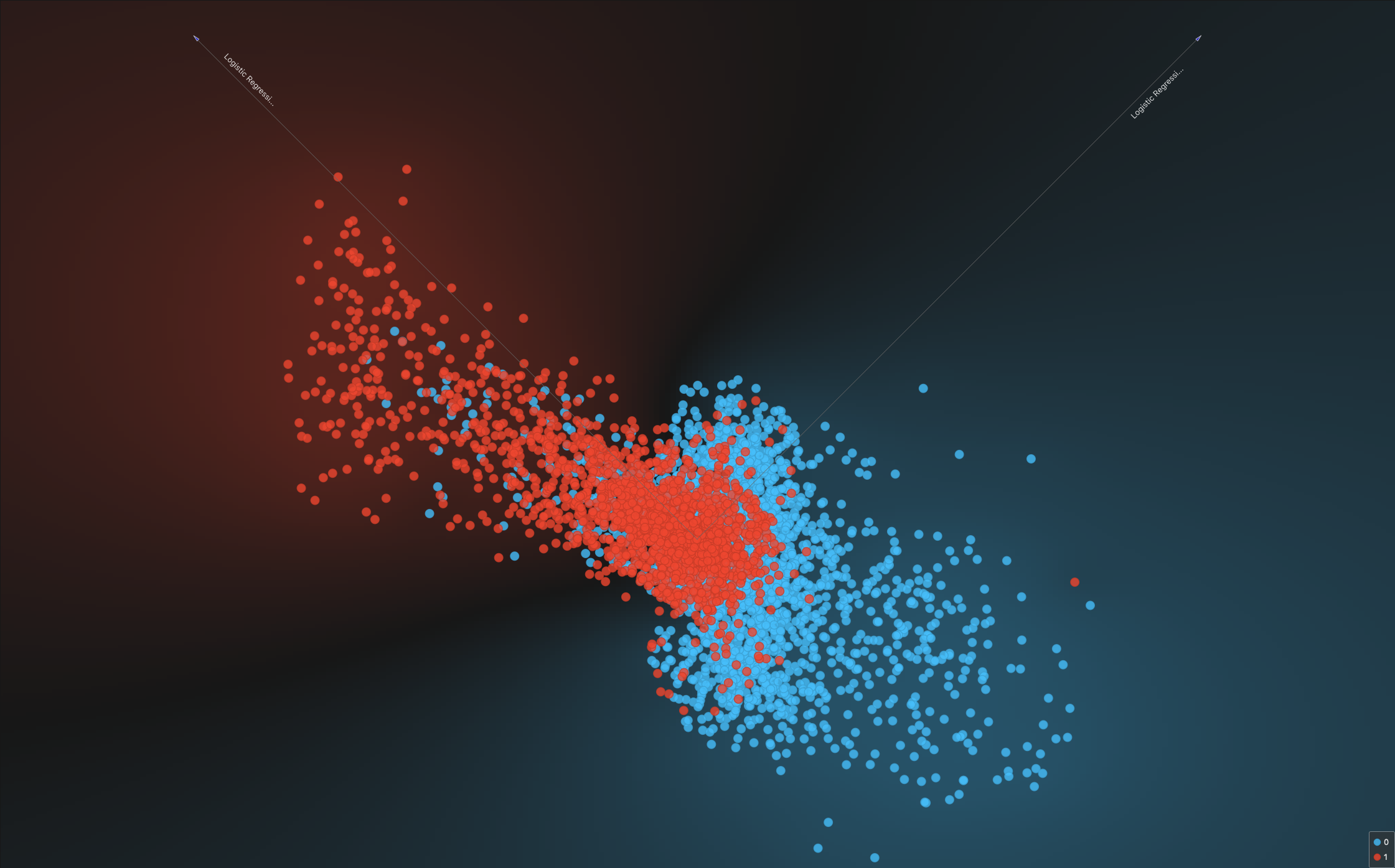
5.7 Représentation de la frontière de décision
En connectant le widget “Linear Progression”, on obtient une représentation qui n’est pas évidente à lire.
Personnellement, je n’ai pas réussi (ou j’ai manqué une étape ?) à obtenir une représentation (bien linéaire) de la frontière de décision. Si vous avez la solution, je suis preneur.
5.6 Représentation : Nomogram
Le modèle produit un score linéaire, et le Nomogram en décompose la valeur en contributions de chaque caractéristique (les 57 caractéristiques par observation). Sur ma configuration, j’obtiens bien le visuel du Nomogram mais les libellés des caractéristiques n’apparaissent pas, ce qui rend la lecture impossible…
Le problème semble lié à l’affichage (éventuellement propre à macOS ???). C’est regrettable, car cet outil est très utile pour visualiser l’influence (poids) de chaque caractéristiques sur la décision.
Conclusion
Cette première exploration est déjà dense… Nous aurions pu prolonger avec une analyse de la courbe ROC. L’analyse de la courbe ROC mérite un traitement à part. Rendez-vous dans un prochain billet.