L’objectif de cet article est de présenter un script “expérimental” destiné à l’évaluation du débit de parole.
Le script utilise la transcription automatique fournie par le modèle Whisper d’OpenAI pour découper l’audio en segments et mesurer la vitesse d’élocution à partir des timestamps associés.
Toutefois, bien que le script soit opérationnel, il n’est pas encore dans sa version optimale.
Des améliorations sont envisageables, notamment pour la séparation des locuteurs dans des entretiens comportant plusieurs intervenants (le script comporte un énorme biais à ce niveau) et pour l’optimisation du découpage des segments audio.
En effet, le modèle Whisper semble se baser principalement sur deux types de pauses : les pauses primaires, liées à la respiration, et les pauses secondaires, associées aux processus cognitifs tels que la recherche de mots ou la planification du discours – ces dernières apparaissant notamment lorsque l’intervieweur laisse un temps de réflexion, mais également de manière spontanée ou stratégique dans le discours de l’interviewé.
Par ailleurs, après avoir constaté des lacunes avec le modèle whisper « base » – qui omettait de nombreux passages – j’ai opté pour le modèle « small », qui offrent une meilleure retranscription.
sur streamlitcloud (no code !) : https://analyseparolepauses.streamlit.app/
La vidéo de référence
Dans un cadre strictement méthodologique, j’ai utilisé cette vidéo uniquement pour développer les fonctionnalités du script dans le but de mesurer le débit de parole.
Bien que cet indicateur soit intéressant, il ne suffit pas à lui seul pour tirer des conclusions définitives. Il devra être intégré dans une approche multimodale, où image, texte et voix sont analysés de manière synchronisée pour offrir une compréhension plus complète du discours.
Ce développement est actuellement en cours, car cette approche présente un potentiel réel dans l’analyse d’un discours.
La vidéo test utilisée pour élaborer le script est issue d’un contexte très particulier : elle relate l’interview de Marine Le Pen réalisée par TF1 (à partir de 8’05) après sa condamnation pour inéligibilité.
L’objectif de cette analyse est d’examiner, à travers le débit de parole, la stratégie discursive déployée par Marine Le Pen lors de cet entretien.
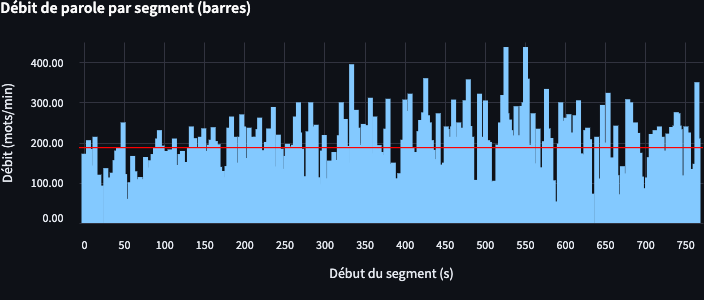
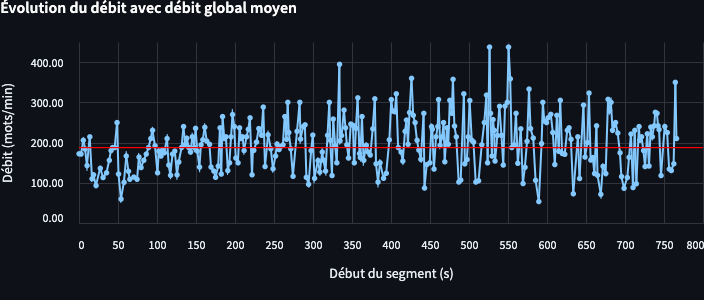
On observe que les pauses apparaissent principalement lorsque le journaliste pose des questions, tandis que Marine Le Pen s’exprime de manière continue, sans temps de pause notable (non détecté par whisper, configuré sur des pauses > 1 s).
Par ailleurs, à mesure que l’interview progresse, le discours se complexifie et se transforme en un véritable mélange de questions et de réponses enchevêtrées.
Fonctionnement et modes
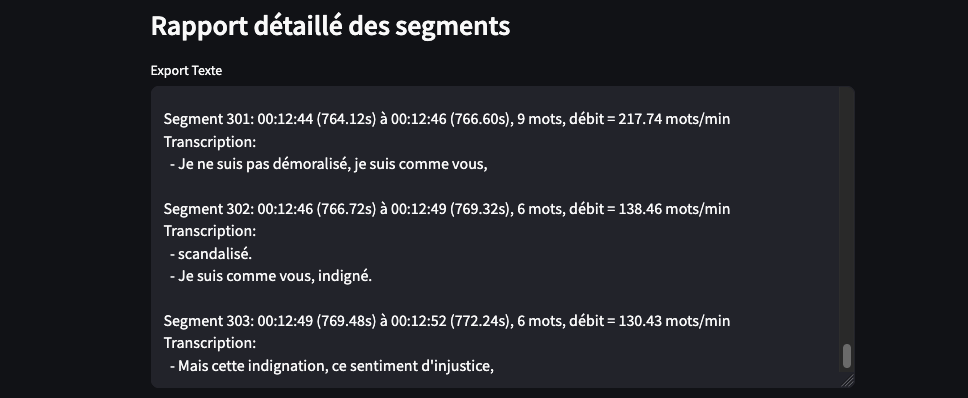
L’analyse se fait à partir des timestamps associés aux segments issus de la transcription. Autrement dit, le calcul du débit (mots par minute) s’appuie sur la durée des segments (déterminée grâce aux timestamps) et sur le nombre de mots dans le texte transcrit.
Cela signifie qu’après que Whisper a reconnu et converti l’audio en texte, le script compte les mots et divise ce nombre par la durée (exprimée en minutes) déterminée par les timestamps.
Mode automatisé “Whisper”
“Au petit bonheur la chance”… Dans le mode « whisper », la segmentation repose entièrement sur la capacité du modèle Whisper à détecter automatiquement les pauses naturelles dans le discours (pauses respiratoires par exemple). En effet, lors de la transcription, Whisper effectue une analyse acoustique du signal audio et identifie des points de transition (souvent marqués par des micro silences ou des changements de tonalité) qui lui permettent de découper le discours en segments internes.
Cela dit, il faut reconnaître que l’on ne peut pas maîtriser entièrement la méthode de segmentation mise en œuvre par le modèle, ce qui est limitant.
Mode Ponctuation
Dans le mode ponctuation, après que le texte complet ait été transcrit, le script découpe le discours en phrases en se basant sur la ponctuation. Ensuite, pour chaque phrase isolée, un intervalle de temps est attribué de manière uniforme sur l’entièreté de la durée transcrite.
Autrement dit, la durée totale de la vidéo est divisée équitablement entre toutes les phrases, ce qui donne à chaque segment un début et une fin “estimés”.
Cette répartition, bien qu’approximative, permet de segmenter le discours selon sa structure syntaxique, permettant ainsi le calcul du débit de parole (mots par minute). Cependant, il n’est pas possible de “forcer” le modèle Whisper à utiliser strictement la ponctuation pour générer des timestamps précis, car la segmentation interne de Whisper est déterminée par l’analyse acoustique du signal audio et les critères internes du modèle (comme la détection des silences et les changements de tonalité).
Le mode « ponctuation » semblait séduisant, mais il semble malheureusement manquer de précision ! Cela dit, lorsqu’une mesure est utilisée, il est essentiel de l’appliquer de manière homogène. Il conviendra donc de tester cette approche dans divers contextes et de la confronter aux observations empiriques, en réexaminant la vidéo pour vérifier sa cohérence.
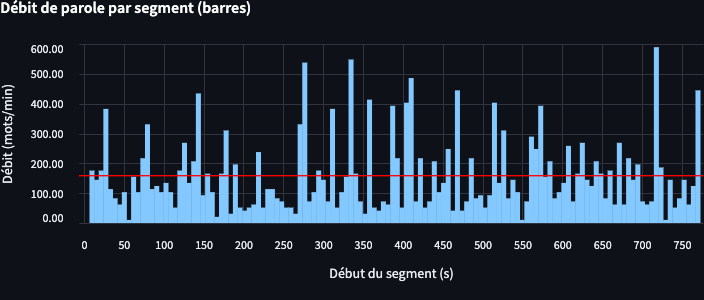

En résumé, si vous avez besoin de timestamps précis pour chaque segment, il est recommandé d’utiliser la segmentation interne de Whisper plutôt que de découper le texte par ponctuation.
Analyse des pauses
Dans le domaine de la communication politique un débit de parole élevé lors d’une interview peut être interprété de plusieurs manières.
D’une part, il peut refléter une volonté de contrôler l’échange en limitant les interventions de l’intervieweur, empêchant ainsi la formulation de questions potentiellement déstabilisantes. D’autre part, parler rapidement et sans pauses significatives peut empêcher l’auditoire de réfléchir ou d’analyser les propos tenus, ce qui peut être perçu comme une stratégie pour imposer un message.
Ainsi, un débit de parole élevé sans pauses lors d’une interview politique peut être une stratégie délibérée visant à contrôler la conversation et à influencer la perception du public. Toutefois, cette approche peut également être perçue négativement si elle est interprétée comme une tentative d’éviter le dialogue ou la transparence.
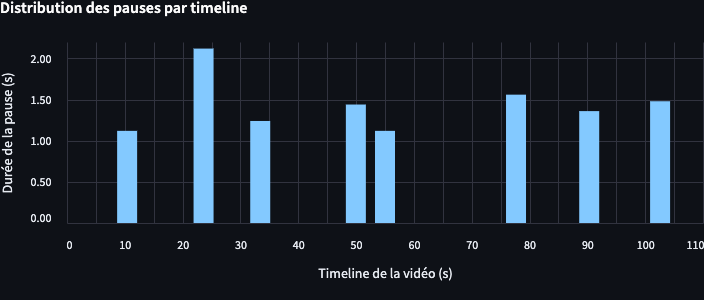
Le script est paramétré pour détecter les pause > 1 seconde (ce qui correspond non pas à une pause “respiratoire” mais à une pause “cognitive”).
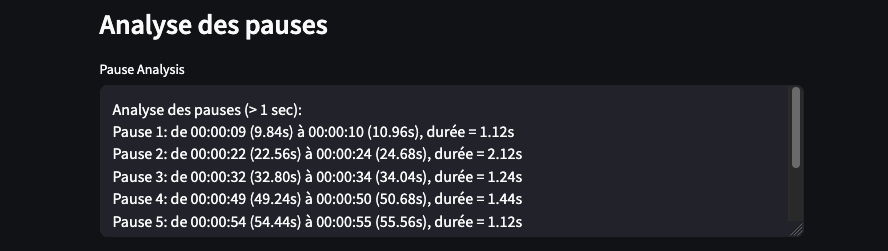
Perspectives
En conclusion, notre approche actuelle, basée sur le mode « whisper » pour la segmentation automatique et le découpage par ponctuation, offre déjà une vision intéressante du débit de parole et des dynamiques discursives. Toutefois, chacune de ces méthodes présente des limites : tandis que le mode « whisper » s’appuie sur l’analyse acoustique pour détecter les pauses naturelles, il reste tributaire de la fidélité du modèle et peut parfois omettre des transitions subtiles ; le mode « ponctuation », quant à lui, repose sur une répartition uniforme des timestamps, ce qui demeure une approximation.
Pour aller plus loin, une perspective prometteuse consisterait à développer un troisième mode de segmentation basé sur un alignement forcé, par exemple en utilisant Gentle ou d’autres outils tels que le Montreal Forced Aligner.
Ce mode permettrait de ré-aligner précisément le texte transcrit avec le signal audio d’origine, fournissant ainsi des timestamps plus précis pour chaque segment.