J’apporte ici des modifications sur le script précédent portant surl’analyse de l’amplitude sonore et du flux optique.
Rappelons le cette double approche permet non seulement d’identifier les instants forts du discours d’un locuteur (en se basant sur l’amplitude sonore), mais aussi de visualiser la “dynamique gestuelle” qui accompagne le propos, ouvrant la voie à une analyse multimodale. L’analyse de l’amplitude sonores présente un intérêt pour repérer les instants forts du discours (saillants ?), mais elle gagnerait à être croisée avec l’étude des temps de pause.
Dans un script antérieur, j’ai exploré cette dimension en mesurant la durée et la fréquence des silences croisée avec l’image pour appréhender l’impact notamment la dimension cognitive du discours avec ces moment de pause qui pourrait signifier une forme d’anticipation, d’analyse et de métacognition.
Le script décrit ici ne calcule pas encore ces instants de pause ni ne propose de métriques spécifiques pour les quantifier. Vous pouvez toutefois, en revisitant manuellement la vidéo cible, effectuer une analyse empirique de ces silences (si il y en a) afin d’enrichir l’interprétation des dynamiques discursives.
Le filtrage des observations atypiques
Pour filtrer l’amplitude sonore selon le paramètre k, on commence par calculer, sur chaque observation d’une seconde du signal, la moyenne (μ) et l’écart-type (σ) des valeurs d’amplitude du signal.
L’utilisateur doit choisir un facteur (k), qui définit l’intervalle de confiance [μ – k·σ et μ + k·σ].
En ajustant k, l’utilisateur contrôle la sensibilité du filtre.
Lorsque k = 1, l’intervalle de filtrage devient [μ – σ, μ + σ], c’est-à-dire un écart d’une écart-type autour de la moyenne. En choisissant k = 1, on retient donc principalement les amplitudes considérées comme « normales ».
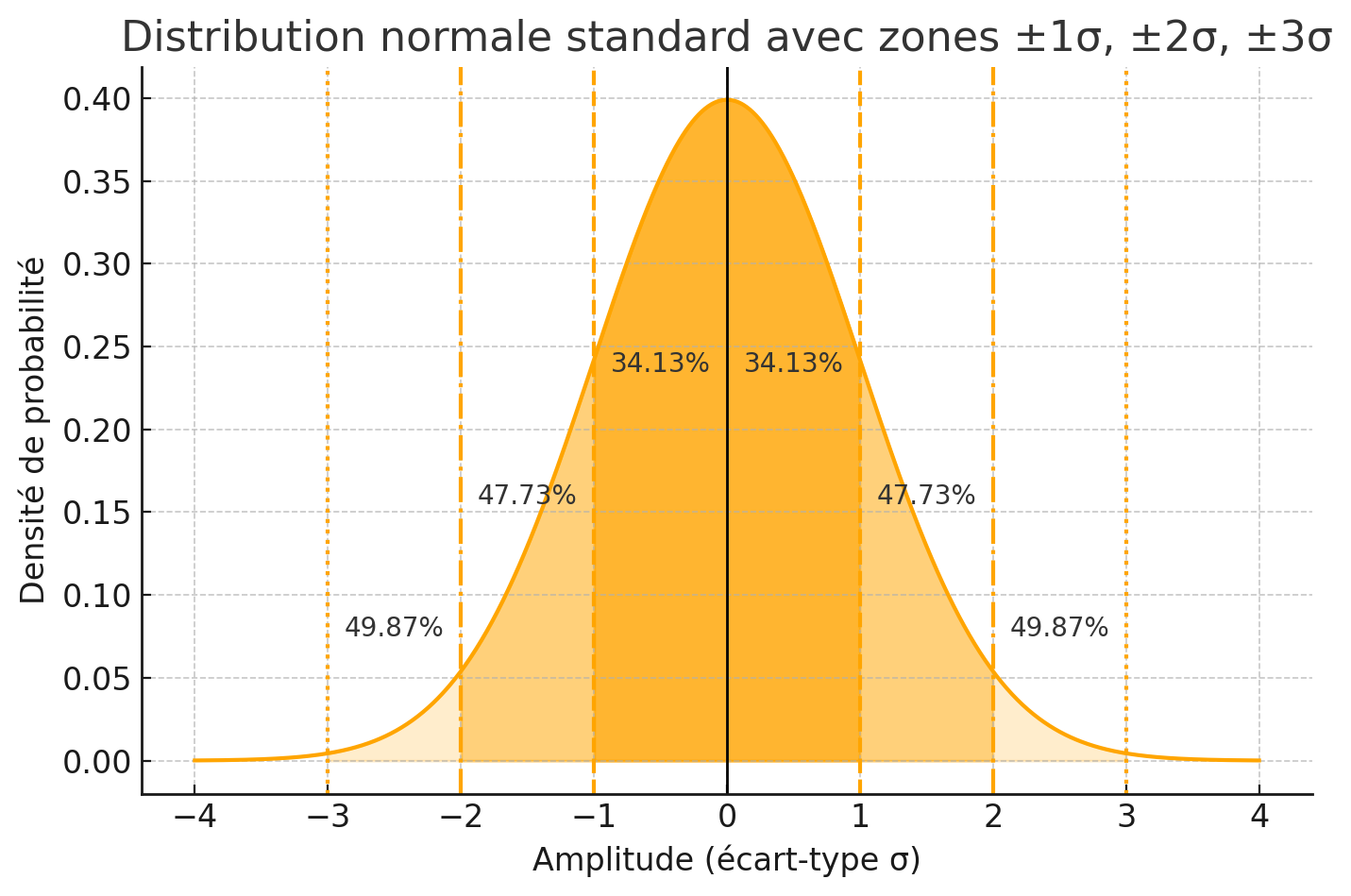
Si on sélectionne k = 3, théoriquement, dans une loi normale stricte, l’intervalle [μ − 3 σ, μ + 3 σ] couvre environ 99,7 % des observations : seuls 0,3 % des observations (soit 5 à 8 secondes les 2560 s de la vidéo de notre exemple) devraient tomber en dehors et être qualifiées d’observation atypiques.
Or, le score d’observation atypiques dans notre vidéo est de 27 s, ce qui correspond à plus de 1 % des observations. La distribution de l’amplitude audio présente donc une « queue/traine » plus épaisses que la gaussienne théorique : les extrêmes (pics sonores très forts ou très faibles) sont plus fréquents que prévu.

Ici, le filtrage “statistique” joue d’abord un rôle de sélection : il permet d’extraire les observations de signal véritablement saillants, en se concentrant sur les amplitudes qui s’écartent significativement du niveau moyen.
La loi normale a été choisie comme heuristique de filtrage pour deux raisons : d’une part, la moyenne (μ) et l’écart-type (σ) sont des descripteurs de la dispersion d’un jeu de données ; d’autre part, les seuils μ ± k σ offrent une “convention” statistique largement répandue pour quantifier les observations atypiques (≈ 32 % hors ± 1·σ, 4,5 % hors ± 2·σ et 0,3 % hors ± 3·σ).
Il ne faut cependant pas s’attendre à ce que l’ensemble d’un discours (politique) suive exactement une loi normale parfaite ce n’est pas une fin en soi. La comparaison entre la distribution réelle des amplitudes et la courbe normale théorique permet de mesurer la déviation : un taux d’anomalies empirique supérieur aux 0,3 % attendus pour k=3 signale une fréquence plus élevée de pics sonores.
Cette démarche reste avant tout mathématique et/mais descriptive : elle fournit un repère visuel et chiffré pour ajuster le filtrage et comparer différents discours sur une même échelle par exemple.
Les améliorations et corrections
Pour pallier la limite de téléchargement imposée par Streamlit sur les vidéos trop longues ou trop volumineuses, la partie du script gérant l’importation a été révisée.
Désormais, lz script prend en charge aussi bien les fichiers locaux de moins de 200 Mo que les URL YouTube. Si vous optez pour l’import d’un fichier MP4 local, vous pouvez vous appuyer sur un outil capable de découper la vidéo en segments et de la compresser pour respecter les contraintes de taille.
Cette option s’avère intéressante si vous avez déjà préalablement découpé ou compressé vos séquences à l’aide de votre propre script : il suffit alors de charger chaque fragment allégé sans risque de dépasser le quota, pour enchaîner immédiatement l’analyse audio et visuelle sans passer par une URL externe.
Cookies
Il est possible d’intégrer un fichier cookies.txt directement dans le script. Grâce à cette option, le téléchargement via youtube-dl se fait sous une session authentifiée, ce qui permet de contourner certains blocages.
Fenêtre textuelle
La définition de la fenêtre textuelle offre désormais une flexibilité étendue, avec des durées de 1, 5, 10, 20, 30, 40, 50 et 60 secondes.
Cette granularité permet d’adapter la segmentation du discours selon les besoins de l’analyse : de l’observation des micro-phrases à l’étude des séquences plus longues, on peut choisir la temporalité la plus pertinente pour capturer les faits saillants (les phrases en rouge marquent l’amplitude sonore détectée).
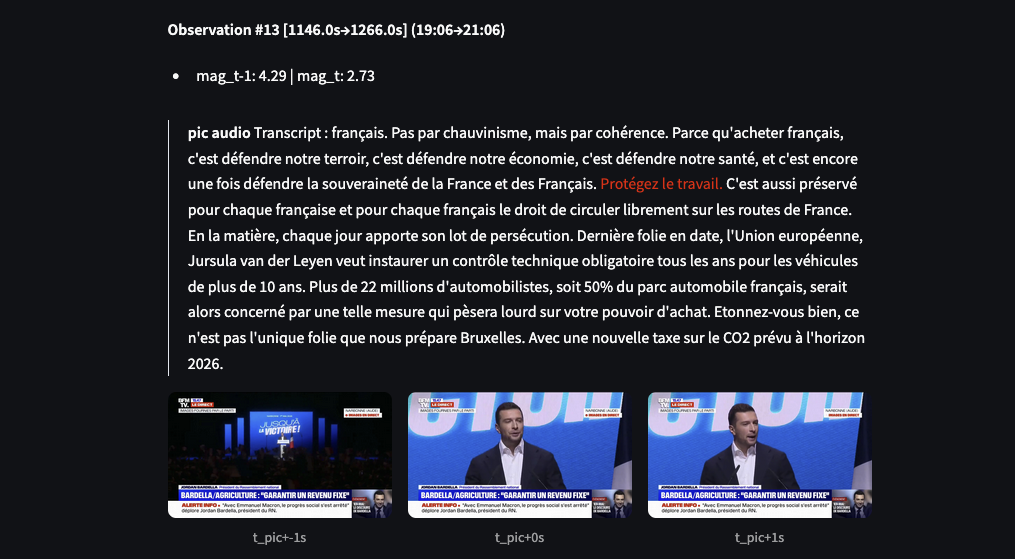
Le paramètre window s’interprète comme une “demi-fenêtre” autour du pic audio.
Concrètement, quand vous choisissez window = 10, l’extraction du texte se fera à t_pic − 10s et à t_pic + 10s.
Le rapport de transcription (téléchargeable en bas de page) fournit une synthèse des résultats : les pics sonores y sont automatiquement annotés en rouge, mais les images clés doivent être téléchargées manuellement pour le moment.
Les plans dont l’échelle varie (changements de cadrage, zooms/dézooms) sont à considérer comme non significatifs et doivent être exclus de vos analyses.
Enfin, il est recommandé de comparer la transcription générée par Whisper (précise à environ 80 %) avec la vidéo originale pour corriger les erreurs de transcription.
Génération de la transcription et des extraits sonores
Le script crée automatiquement un fichier texte de retranscription dans lequel sont listées les principales données, pour chaque observation atypique et le segment de texte transcrit avant et après le pic sonore, selon la fenêtre définie par l’utilisateur.
Parallèlement, chaque observation atypique est exportée au format WAV et MP4 dans le répertoire “Downloads”, en découpant précisément l’extrait sonore et la vidéo vous pourrez ainsi réécouter immédiatement la partie du discours à l’origine du “pic”.
Le fichier de retranscription complet est disponible en téléchargement en bas de l’analyse (il faut scroller).
Perspectives
Une piste de réflexion d’ordre méthodologique consisterait à utiliser les images d’OpticalFlow dans le cadre de l’apprentissage supervisé pour enrichir des modèles de détection des émotions. Plutôt que de s’appuyer sur les émotions « universelles » de Paul Ekman, souvent peu discriminantes et fréquemment classées comme « neutres » par les modèles, on pourrait exploiter les images issues du flux optique comme filtrage préalable.
Ces images permettraient d’isoler les séquences visuellement atypiques à annoter.
En couplant ces images avec les pics d’amplitude sonore, on obtiendrait des « points saillants » particulièrement pertinents pour l’entraînement supervisé des modèles avec des émotions « authentiques ».
Code source
Deux fichiers sont nécessaires.Les librairies à installer : pip install streamlit opencv-python soundfile plotly openai-whisper yt-dlp
Le plus simple reste de récupérer le code sur Github.
Le fichier principal main.py
############
# Analyse de l'amplitude sonore et du flux optique
# import fichier local < 200 Mo et/url - Fenêtre textuell : 1-5-10-20-30-40-50-60 sec
# Stéphane Meurisse
# www.codeandcortex.fr
# Date : 07-05-2025
############
# python -m streamlit run main.py
# pip install streamlit opencv-python soundfile plotly openai-whisper yt-dlp
import os
import subprocess
import streamlit as st
import numpy as np
import soundfile as sf
import plotly.graph_objects as go
import cv2
import whisper
from yt_dlp import YoutubeDL
from opticalflow import compute_optical_flow_metrics, _get_frame_at_time
# --- Initialisation du rapport dans le session_state ---
if 'rapport_observations' not in st.session_state:
st.session_state['rapport_observations'] = ''
# --- Fonctions utilitaires ---
def convertir_en_min_sec(seconds: float) -> str:
"""Convertit des secondes en format mm:ss."""
m, s = divmod(max(0, int(seconds)), 60)
return f"{m:02d}:{s:02d}"
def telecharger_video_et_extraire_audio(video_url: str, cookiefile: str=None, rep: str="downloads") -> tuple[str, str]:
"""Télécharge une vidéo YouTube et extrait l'audio en WAV mono 16 kHz."""
os.makedirs(rep, exist_ok=True)
opts = {
"format": "bestvideo[ext=mp4]+bestaudio[ext=m4a]/mp4",
"outtmpl": os.path.join(rep, "%(id)s.%(ext)s"),
"quiet": True
}
if cookiefile:
opts["cookiefile"] = cookiefile
with YoutubeDL(opts) as ydl:
info = ydl.extract_info(video_url, download=True)
vid = info.get("id")
video_path = os.path.join(rep, f"{vid}.mp4")
wav_path = os.path.join(rep, f"{vid}.wav")
cmd = [
"ffmpeg", "-y", "-i", video_path,
"-vn", "-ac", "1", "-ar", "16000", "-c:a", "pcm_s16le", wav_path
]
subprocess.run(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, check=True)
return video_path, wav_path
def extraire_audio_video_locale(video_path: str, rep: str="downloads") -> tuple[str, str]:
"""Extrait l'audio d'un fichier vidéo local MP4 en WAV mono 16 kHz."""
os.makedirs(rep, exist_ok=True)
base = os.path.splitext(os.path.basename(video_path))[0]
wav_path = os.path.join(rep, f"{base}.wav")
cmd = [
"ffmpeg", "-y", "-i", video_path,
"-vn", "-ac", "1", "-ar", "16000", "-c:a", "pcm_s16le", wav_path
]
subprocess.run(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, check=True)
return video_path, wav_path
def extraire_clip_audio(wav_path: str, centre: float, demi: int, rep: str="downloads") -> str:
"""Extrait un clip audio de durée 2*demi secondes centré sur centre."""
os.makedirs(rep, exist_ok=True)
start = max(0, centre - demi)
clip_path = os.path.join(rep, f"clip_{start:.2f}_{2*demi:.2f}.wav")
cmd = [
"ffmpeg", "-y", "-i", wav_path,
"-ss", str(start), "-t", str(2*demi), clip_path
]
subprocess.run(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, check=True)
return clip_path
####
def extraire_clip_video(video_path: str, centre: float, demi: int, rep: str="downloads") -> str:
"""
Extrait un clip vidéo MP4 (durée 2*demi s) centré sur centre,
sans réencodage (mode copy), et retourne son chemin.
"""
os.makedirs(rep, exist_ok=True)
start = max(0, centre - demi)
dur = 2 * demi
base = os.path.splitext(os.path.basename(video_path))[0]
clip_mp4 = os.path.join(rep, f"{base}_clip_{start:.2f}s_{dur:.2f}s.mp4")
cmd = [
"ffmpeg", "-y", "-i", video_path,
"-ss", str(start), "-t", str(dur),
"-c", "copy", clip_mp4
]
subprocess.run(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, check=True)
return clip_mp4
####
def transcrire_clip_whisper(wav_clip: str, highlight: float) -> str:
"""Transcrit un clip audio et surligne en rouge le segment autour de highlight."""
model = whisper.load_model("small")
res = model.transcribe(wav_clip, language="fr")
segs = res.get('segments', [])
texte = " ".join(s['text'].strip() for s in segs)
cible = next((s['text'].strip() for s in segs if s['start'] <= highlight <= s['end']), None)
if cible:
texte = texte.replace(cible, f"<span style='color:red'>{cible}</span>", 1)
return texte
def downsample_by_second(data: np.ndarray, times: np.ndarray, sr: int):
"""Calcule l'enveloppe min/max et temps moyens par seconde."""
step = sr
cnt = len(data) // step
t_int, mn, mx, env = [], [], [], []
for i in range(cnt):
seg = data[i*step:(i+1)*step]
t_int.append(times[i*step:(i+1)*step].mean())
mn.append(float(seg.min())); mx.append(float(seg.max()))
env.append((float(seg.min()) + float(seg.max())) / 2)
return np.array(t_int), np.array(mn), np.array(mx), np.array(env)
def chercher_pic(data: np.ndarray, sr: int, centre: float) -> float:
"""Retourne le timestamp du pic absolu autour de centre ±0.5s."""
demi = sr // 2
idx = int(centre * sr)
start, end = max(idx-demi, 0), min(idx+demi, len(data))
wnd = data[start:end]
if wnd.size == 0:
return centre
rel = np.argmax(np.abs(wnd))
return (start + rel) / sr
# --- Fonctions flux optique ---
def faire_carte_flux(flow_map: np.ndarray) -> np.ndarray:
"""Génère une heatmap JET d'une carte de flux optique."""
mag = np.linalg.norm(flow_map, axis=2) if flow_map.ndim == 3 else flow_map
norm = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
return cv2.applyColorMap(norm.astype(np.uint8), cv2.COLORMAP_JET)
def superposer_vecteurs(frame: np.ndarray, flow_map: np.ndarray, step: int=16) -> np.ndarray:
"""Superpose des vecteurs de flux optique sur une image."""
img = frame.copy(); h, w = img.shape[:2]
fx, fy = flow_map[...,0], flow_map[...,1]
for y in range(0, h, step):
for x in range(0, w, step):
dx, dy = int(fx[y,x]), int(fy[y,x])
cv2.arrowedLine(img, (x,y), (x+dx,y+dy), (0,255,0), 1, tipLength=0.3)
return img
# --- Interface Streamlit ---
st.title("Analyse amplitude sonore & mouvements - version 2")
st.markdown("www.codeandcortex.fr - version 2")
# Aide :
with st.expander("Aide"):
# 4) Explications et interprétations
st.subheader("Interprétation des résultats")
st.markdown("**Qu'est-ce que la magnitude optique ?**")
st.markdown("La **magnitude optique** correspond à la moyenne des normes des vecteurs de déplacement calculés"
"entre deux images consécutives par l'algorithme Farneback. Elle quantifie l'intensité du mouvement visuel :")
st.markdown(
"- *Valeurs élevées* : mouvements rapides ou importants\n"
"- *Valeurs faibles* : mouvements lents ou quasi-statiques")
st.markdown("**Calcul de l'observation atypique audio :**")
st.markdown("Une observation audio atypique est détectée lorsque l'amplitude moyenne de l'enveloppe audio dépasse le seuil défini par μ ± kσ,"
"où μ est la moyenne des amplitudes sur la vidéo et σ leur écart-type. Cela permet d'identifier des pics sonores significatifs.")
st.markdown("**Flux optique :**")
st.markdown("Le flux optique (Farneback) mesure les déplacements de pixels entre deux images consécutives."
"Une heatmap JET traduit ces déplacements en intensité de mouvement, du bleu (faible) au rouge (fort).")
st.markdown("**Superposition :**")
st.markdown("La superposition de la heatmap sur l'image d'origine met en évidence les zones de mouvement significatif,"
"conservant la perception visuelle du contenu tout en signalant le mouvement.")
st.markdown("**Vecteurs de flux :**")
st.markdown("Les flèches tracées représentent les vecteurs de déplacement (dx, dy) de blocs de pixels."
"Leur densité et leur orientation illustrent la direction et l'amplitude du mouvement.")
video_url = st.text_input("URL YouTube")
video_local = st.file_uploader("Importer vidéo locale (MP4)", type=["mp4"])
cookie_file = st.file_uploader("Importer cookies (Netscape)", type=["txt","cookies"])
k_value = st.slider("k (intervalle [μ ± kσ])", 1.0, 5.0, 2.0, 0.1)
window = st.selectbox("Intervalle transcription autour du pic (s)", [1,5,10,20,30,40,50,60], index=0)
if st.button("Lancer l’analyse"):
# Réinitialise rapport
st.session_state['rapport_observations'] = ''
# Vérification source
if not video_url and not video_local:
st.error("URL YouTube ou fichier local requis.")
st.stop()
# Gestion cookies
cp = None
if cookie_file:
os.makedirs("downloads", exist_ok=True)
cp = os.path.join("downloads", cookie_file.name)
with open(cp, 'wb') as f:
f.write(cookie_file.read())
# Chargement vidéo
if video_local:
st.info("Chargement vidéo locale…")
os.makedirs("downloads", exist_ok=True)
chemin = os.path.join("downloads", video_local.name)
with open(chemin, 'wb') as f:
f.write(video_local.read())
video_path, audio_path = extraire_audio_video_locale(chemin)
else:
st.info("Téléchargement YouTube…")
video_path, audio_path = telecharger_video_et_extraire_audio(video_url, cp)
# Affichage vidéo
st.video(video_path)
# Lecture audio
data, sr = sf.read(audio_path)
if data.ndim > 1:
data = data.mean(axis=1)
dur = len(data) / sr
st.write(f"Durée : {dur:.1f}s — {len(data)} échantillons à {sr}Hz")
# Calcul enveloppe
times = np.linspace(0, dur, len(data))
t_int, mn, mx, env = downsample_by_second(data, times, sr)
# Transcription complète avec Whisper modèle small
st.info("Transcription complète…")
whisper.load_model("small").transcribe(audio_path, language="fr")
# Détection anomalies
mu, si = env.mean(), env.std()
mu = 0 if abs(mu) < 1e-6 else mu
si = 0 if abs(si) < 1e-6 else si
lb, ub = mu - k_value * si, mu + k_value * si
idx = np.where((env < lb) | (env > ub))[0]
t_out, env_out = t_int[idx], env[idx]
st.info(f"{len(idx)} observations atypiques détectées")
# Graphique amplitude
fig = go.Figure()
fig.add_trace(go.Scatter(x=np.r_[t_int, t_int[::-1]], y=np.r_[mn, mx[::-1]], fill='toself', fillcolor='rgba(255,255,255,0.2)', line=dict(width=0), name='Enveloppe'))
fig.add_trace(go.Scatter(x=t_int, y=env, mode='lines', name='Enveloppe moyenne'))
fig.add_trace(go.Scatter(x=t_out, y=env_out, mode='markers', marker=dict(color='red', size=8), name='Anomalies'))
fig.update_layout(xaxis_title='Temps (s)', yaxis_title='Amplitude audio')
st.plotly_chart(fig, use_container_width=True, config={"displayModeBar": True, "displaylogo": False})
# Analyse détaillée et constitution du rapport
st.subheader(f"Analyse anomalies et transcription (±{window}s autour du pic audio)")
rapport = []
for i, t0 in enumerate(t_out):
# 1) Calcul du pic précis
t_pic = chercher_pic(data, sr, t0)
# 2) Extraction et affichage du clip vidéo centré ± window
# video_clip = extraire_clip_video(video_path, t_pic, window)
# st.video(video_clip)
# 3) Calcul des bornes et du flux optique
s0, s1 = t_pic - window, t_pic + window
m0, m1 = convertir_en_min_sec(s0), convertir_en_min_sec(min(s1, dur))
evt = compute_optical_flow_metrics(video_path, [t_pic], dt=1.0)[0]
# Affichage observation
st.markdown(f"---\n**Observation #{i+1} [{s0:.1f}s→{s1:.1f}s] ({m0}→{m1})**")
st.markdown(f"- mag_t-1: {evt['mag_prev']:.2f} | mag_t: {evt['mag_next']:.2f}")
# Transcription clip
clip = extraire_clip_audio(audio_path, t_pic, window)
txt = transcrire_clip_whisper(clip, window)
st.markdown(f"> **pic audio** Transcript : {txt}", unsafe_allow_html=True)
# Images brutes et heatmaps/superpositions
cols = st.columns(3)
cap = cv2.VideoCapture(video_path)
for off, col in zip([-1, 0, 1], cols):
frame = _get_frame_at_time(cap, t_pic + off)
col.image(frame, channels='BGR', caption=f"t_pic+{off}s")
cap.release()
h1, h2 = st.columns(2)
heat_prev = faire_carte_flux(evt['flow_map_prev'])
heat_next = faire_carte_flux(evt['flow_map_next'])
h1.image(heat_prev, channels='BGR', caption='Flux t-1→t')
h2.image(heat_next, channels='BGR', caption='Flux t→t+1')
sp1, sp2 = st.columns(2)
sup_prev = cv2.addWeighted(evt['frame_prev'], 0.7, heat_prev, 0.3, 0)
sup_next = cv2.addWeighted(evt['frame'], 0.7, heat_next, 0.3, 0)
sp1.image(sup_prev, channels='BGR', caption='Superposition t-1 → t')
sp2.image(sup_next, channels='BGR', caption='Superposition t → t+1')
v1, v2 = st.columns(2)
vec_prev = superposer_vecteurs(evt['frame_prev'], evt['flow_map_prev'])
vec_next = superposer_vecteurs(evt['frame'], evt['flow_map_next'])
v1.image(vec_prev, channels='BGR', caption='Vecteurs t-1 → t')
v2.image(vec_next, channels='BGR', caption='Vecteurs t → t+1')
# Ajout au rapport
rapport.append(f"Observation {i+1} [{s0:.1f}s→{s1:.1f}s] ({m0}→{m1}) - mag_t-1: {evt['mag_prev']:.2f}, mag_t: {evt['mag_next']:.2f}")
rapport.append(f"Transcript: {txt}")
# Stockage dans session_state
st.session_state['rapport_observations'] = "\n".join(rapport)
# Bouton de téléchargement après analyse détaillée
if st.session_state['rapport_observations']:
# Le téléchargement ne réinitialise pas la session
st.download_button(
label="Télécharger rapport",
data=st.session_state['rapport_observations'],
file_name="rapport_observations.txt",
mime="text/plain",
key="download_btn",
on_click=lambda: None
)
Le fichier opticalflow.py
import cv2
import numpy as np
def _get_frame_at_time(cap: cv2.VideoCapture, time_sec: float) -> np.ndarray:
"""
Se positionne à time_sec (s) et renvoie la frame correspondante.
"""
cap.set(cv2.CAP_PROP_POS_MSEC, time_sec * 1000)
ret, frame = cap.read()
if not ret:
raise ValueError(f"Impossible de lire la frame à {time_sec}s")
return frame
def compute_optical_flow_metrics(video_path: str, event_times: list[float], dt: float = 1.0) -> list[dict]:
"""
Pour chaque t dans event_times, extrait les frames à t-dt, t, t+dt,
calcule le flux Farneback entre (t-dt)->t et t->(t+dt),
renvoie pour chaque événement :
- time, mag_prev, mag_next
- frame_prev, frame, frame_next
- flow_map_prev, flow_map_next (cartes de flux)
"""
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise FileNotFoundError(f"Impossible d’ouvrir la vidéo : {video_path}")
results = []
for t in event_times:
t1 = max(t - dt, 0)
t2 = t
t3 = t + dt
f1 = _get_frame_at_time(cap, t1)
f2 = _get_frame_at_time(cap, t2)
f3 = _get_frame_at_time(cap, t3)
g1 = cv2.cvtColor(f1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(f2, cv2.COLOR_BGR2GRAY)
g3 = cv2.cvtColor(f3, cv2.COLOR_BGR2GRAY)
flow_prev = cv2.calcOpticalFlowFarneback(
g1, g2, None, 0.5, 3, 15, 3, 5, 1.2, 0
)
flow_next = cv2.calcOpticalFlowFarneback(
g2, g3, None, 0.5, 3, 15, 3, 5, 1.2, 0
)
mag_prev = float(np.mean(np.linalg.norm(flow_prev, axis=2)))
mag_next = float(np.mean(np.linalg.norm(flow_next, axis=2)))
results.append({
"time": t,
"mag_prev": mag_prev,
"mag_next": mag_next,
"frame_prev": f1,
"frame": f2,
"frame_next": f3,
"flow_map_prev": flow_prev,
"flow_map_next": flow_next
})
cap.release()
return results