
Je mets en ligne la version 4 de mon application Streamlit “Europresse to IRaMuTeQ” : https://europress-to-iramuteq-v4.streamlit.app/. La version 3 reste accessible et je ne reviens pas ici sur les options déjà présentes. Je présente succinctement les nouveautés et j’y reviendrai plus en détail prochainement.
Voici également l’historique des articles publiés sur le blog autour de l’application Europresse to IRaMuTeQ.
- Transformer les fichiers HTML Europresse au format IRAMUTEQ avec Python
- Automatisation du traitement des corpus Europresse pour IRAMUTEQ
- Script Europresse : La révolution V2 est arrivée !
- Optimiser l’analyse de corpus Europresse : Un script de détection de doublons
- Europresse to IRaMuTeQ – v3 – appli en ligne
1. Europresse to Iramuteq v4
https://europress-to-iramuteq-v4.streamlit.app/
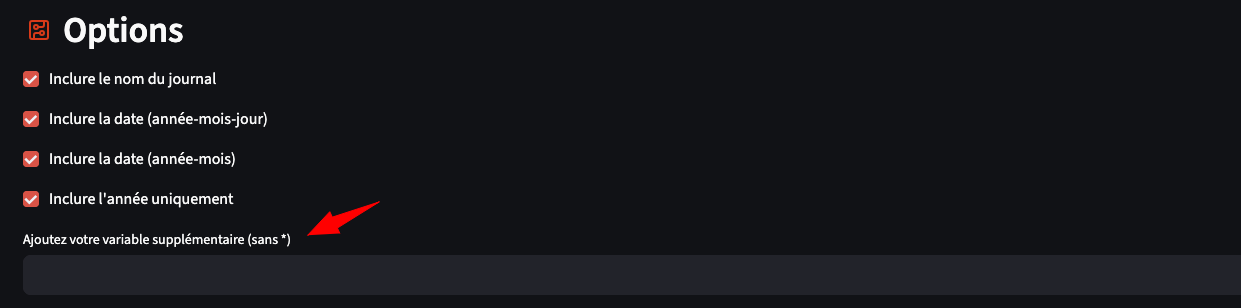
À noter que le lancement de l’application sur le serveur Streamlit Cloud peut prendre quelques secondes : c’est le revers de la gratuité. Autre nouveauté lors de l’import : l’application permet de confirmer le nombre d’articles détectés, que vous pourrez comparer avec votre corpus HTML issu d’Europresse.

Dans les options, vous pouvez toujours renseigner une variable illustrative (ou plusieurs), en plus des variables extraites à partir du fichier HTML.
1.2 Filtrage doublons et articles trop courts
La première nouveauté répond à un problème classique lorsqu’on collecte (trop) rapidement des articles dans Europresse : les doublons. Selon les requêtes, les éditions d’un même quotidien, print ou web, peuvent se cumuler.
Vous pouvez visualiser le résultat du filtrage avant de décider de lancer l’export.
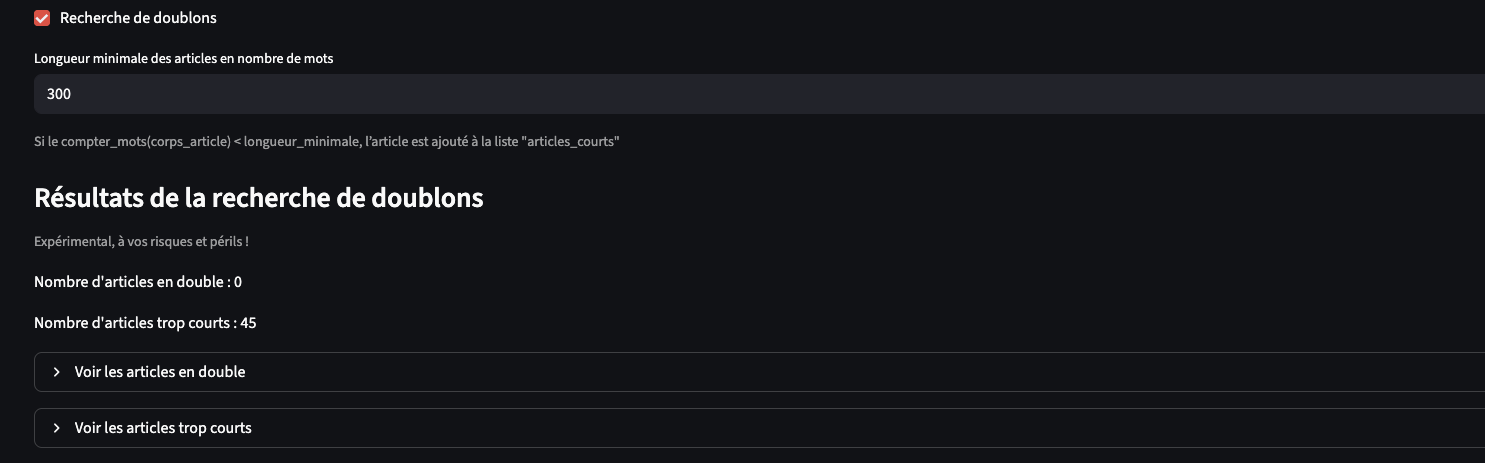
Dans la continuité, la v4 ajoute une option pour éliminer les articles trop courts, qui correspondent souvent à des éditos de quotidiens. Ces deux filtrages sont optionnels.
1.3 Ajout de termes manquants au dictionnaire
Deuxième nouveauté majeure : vous pouvez saisir vos propres règles en Regex pour supprimer des expressions indésirables, notamment celles qui ne figurent pas dans le dictionnaire de nettoyage des balises de type “Edito…”.
1.4 Ajout de règles regex
L’ajout ou la suppression d’un mot en complément ne s’applique pas à l’ensemble du corpus, contrairement au filtrage par regex présenté plus bas. Pourquoi ?
Le “dictionnaire” de termes liés à la ligne éditoriale est constitué de manière empirique, à partir de mots comme “Édito”, “À la une”, etc., mais cette liste est certainement incomplète. Ainsi, lorsque vous ajoutez vos propres termes/expressions repérés dans l’aperçu et qui ne seraient pas filtrés par ce dictionnaire, ils sont recherchés dans des balises spécifiques, qui ne couvrent pas l’intégralité du corpus.
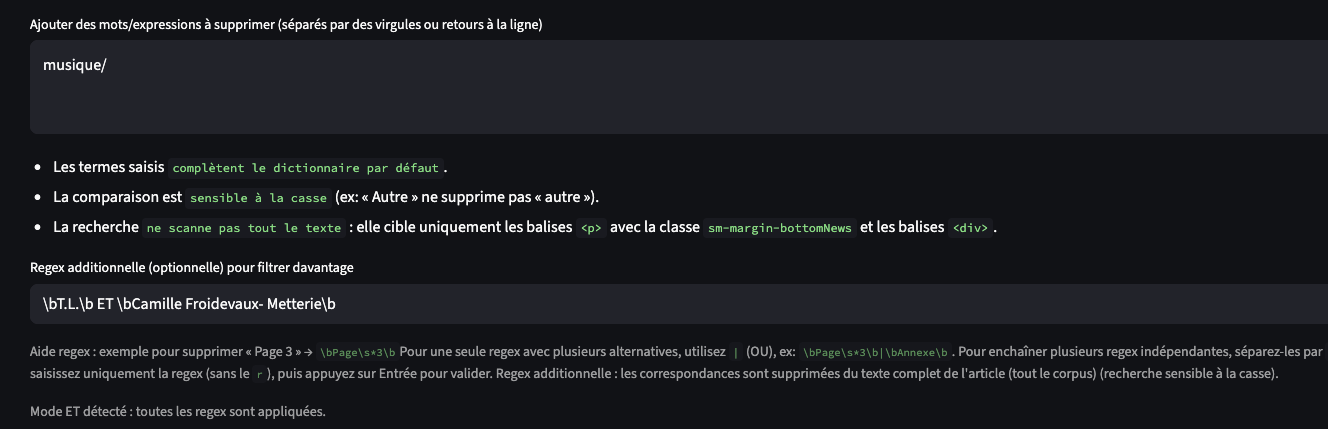
Les règles regex additionnelle, elles, offrent un filtrage sur l’ensemble du corpus.
1.5 Choix de l’export
Enfin, la v4 renforce les possibilités d’export, parce que tout le monde ne travaille pas avec le même objet textuel.
Vous pouvez maintenant choisir de travailler avec intégrabilité de votre corpus ou de filtrer sur les titres et le chapô (chapeau).
J’insiste sur un point important : tous les articles Europresse ne disposent pas d’un “chapô” clairement identifié, et le code HTML d’Europresse reste irrégulier et confus…

Cette nouvelle version vise à réduire le temps passé à “réparer” le corpus après extraction. La version 3 est toujours en ligne.