
Streamlit Cloud est une solution particulièrement intéressante pour héberger gratuitement des applications Python. Simple à utiliser, directement connecté à GitHub, il permet de mettre en production très rapidement des projets basés sur l’interface graphique de Streamlit. Les dépendances sont directement installée et indiquée depuis un fichier requirements.txt. Pour l’utilisateur, “l’expérience” s’apparente à du “no code”, puisqu’il peut exécuter l’application directement à partir d’une simple URL (par exemple) : https://europresse-to-iramuteq.streamlit.app/
Cependant, certains types d’applications rencontrent des blocages sur Streamlit Cloud, notamment celles utilisant ffmpeg et la librairie yt-dlp pour extraire ou télécharger des ressources vidéo ou audio en ligne.
Premièrement, ffmpeg n’est pas une librairie Python mais un programme externe ; il faudrait donc pouvoir l’installer directement sur le serveur de Streamlit Cloud, ce qui est impossible car l’utilisateur (vous) n’a pas les droits d’administration du serveur.
Deuxièmement, même si une solution de contournement semble exister en utilisant la librairie ffmpeg-python, sa mise en œuvre reste complexe. Pour ma part, malgré plusieurs essais, j’ai rencontré des difficultés à faire fonctionner cette option.
Mes recherches sur les forums dédiés à Streamlit Cloud n’ont pas été concluantes : certains “posts” sur les forum datant de 2023/2024 expliquent la démarche, mais en 2025, beaucoup des applications qui semblaient avoir résolu le problème ne fonctionnent plus.
L’objectif ici est de proposer un script capable d’extraire, à partir d’une vidéo YouTube (url), plusieurs types de données dans une perspective d’analyse multimodale :
- La vidéo complète au format mp4,
- Les pistes audio aux formats mp3 et wav,
- La vidéo mp4 découpée selon un intervalle défini par l’utilisateur,
- Les fichiers audio extraits selon cet intervalle,
- L’ensemble des images de la vidéo capturées à une fréquence de 1 image par seconde ou 25 images par seconde.
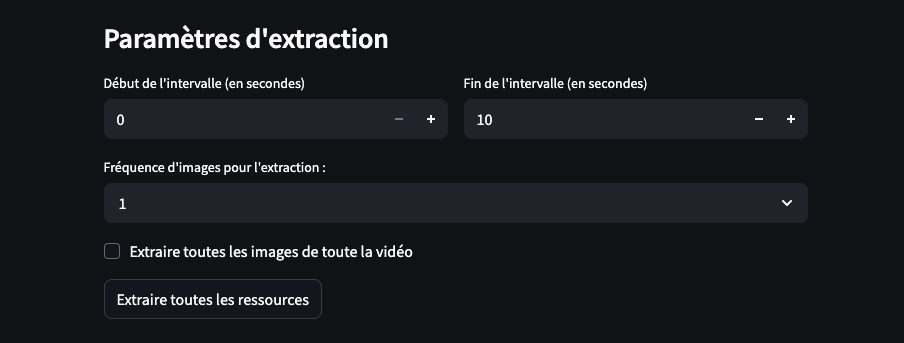
Concernant le paramétrage de l’intervalle, l’interface permet de lire la vidéo directement afin de repérer précisément les moments souhaités.
Les librairies à installer
pip install streamlit # version locale de streamlit, ne pas confondre avec le serveur StreamlitCloud pip install yt-dlp
La principale difficulté reste l’installation de ffmpeg, qui doit être installé en local sur votre machine pour garantir le bon fonctionnement de l’application.
L’erreur 403 avec yt-dlp
L’erreur 403 signifie que l’accès à la ressource est interdit par le serveur de YouTube qui vous détecte comme un “robot”.
Sur Streamlit Cloud, cela se produit car le serveur distant n’a pas les cookies (identité de votre navigateur) nécessaires pour authentifier votre requête.
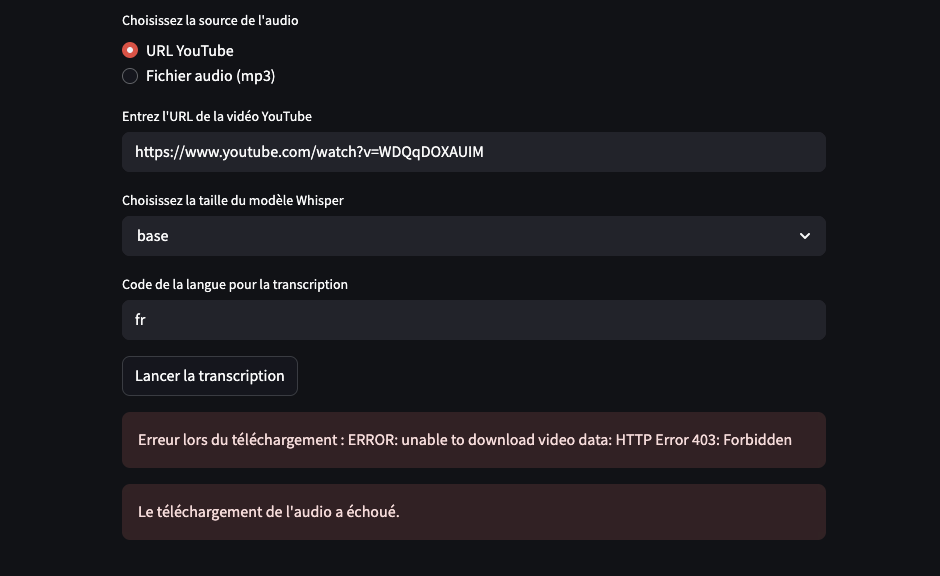
Ainsi, le script peut parfaitement fonctionner lorsqu’on importe directement un fichier source (mp4, mp3, etc.), alors que l’extraction depuis une URL YouTube ne fonctionne plus dans le contexte de StreamliCloud..
Fichier cookies.txt
Le script prend en charge, si nécessaire, l’utilisation d’un fichier cookies extrait de votre navigateur, permettant à YouTube de vous identifier comme un (vrai) utilisateur.
Si un message d’erreur apparaît indiquant que YouTube vous bloque l’accès : relancez l’application (important !), puis ajoutez votre fichier cookies depuis votre disque local.
Cette méthode fonctionne à condition que le fichier ait été généré avec Firefox et que l’application soit exécutée dans ce même navigateur.
Pour générer un cookies, il suffit d’installer l’extension (gratuite) Get cookies.txt.
À quoi sert ffmpeg ?
ffmpeg n’est pas une librairie Python, mais un utilitaire en ligne de commande, indispensable pour traiter de l’audio et de la vidéo. Il permet par exemple :
- D’extraire l’audio d’une vidéo,
- De découper une vidéo selon un intervalle temporel,
- De capturer des images à une fréquence donnée (1fps, 25fps…).
L’installation de ffmpeg sur macOS nécessite l’outil Homebrew, qui est un gestionnaire de paquets.
Ouvrez votre Terminal (Applications → Utilitaires → Terminal) et collez cette commande :
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"

Puis, toujours dans votre terminal tapez la commande :
brew install ffmpeg
Et voila, le tour est joué ! Vous pouvez vérifier la version de ffmpeg :
ffmpeg -version
Le code source
Pour lancer le script dans votre terminal de votre éditeur de code tapez : streamlit run main.py
########
# Extraction multimédia - en local
# wwww.codeandcortex.fr
########
# ---------------- Imports ----------------
import streamlit as st
import tempfile
import os
import zipfile
import subprocess
from yt_dlp import YoutubeDL
# ---------------- Fonctions ----------------
# Fonction pour vider le cache
def vider_cache():
st.cache_data.clear()
# Fonction pour définir un répertoire temporaire
def definir_repertoire_travail_temporaire():
return tempfile.mkdtemp()
# Fonction pour télécharger une vidéo YouTube
def telecharger_video(url, repertoire, cookies_path=None):
st.write("Téléchargement de la vidéo en cours...")
# User-Agent Firefox fixé
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:115.0) Gecko/20100101 Firefox/115.0"
ydl_opts = {
'outtmpl': os.path.join(repertoire, '%(title)s.%(ext)s'),
'format': 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/mp4',
'merge_output_format': 'mp4',
'noplaylist': True,
'quiet': True,
'no_warnings': True,
'user_agent': user_agent,
}
if cookies_path:
ydl_opts['cookiefile'] = cookies_path
try:
with YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(url, download=True)
video_title = info.get('title', 'video')
video_path = os.path.join(repertoire, f"{video_title}.mp4")
return video_path, video_title, None
except Exception as e:
return None, None, str(e)
# Fonction pour extraire toutes les ressources
def extraire_ressources(video_path, repertoire, debut, fin, video_title, fps_choice, extraire_toute_video):
ressources = {}
try:
ressources['video_complet'] = video_path
# Extraction audio complet
mp3_path = os.path.join(repertoire, f"{video_title}.mp3")
wav_path = os.path.join(repertoire, f"{video_title}.wav")
subprocess.run(["ffmpeg", "-i", video_path, "-vn", "-acodec", "libmp3lame", "-q:a", "2", mp3_path], check=True)
subprocess.run(["ffmpeg", "-i", video_path, "-vn", "-acodec", "pcm_s16le", wav_path], check=True)
ressources['audio_mp3_complet'] = mp3_path
ressources['audio_wav_complet'] = wav_path
# Extraction vidéo extrait
extrait_video_path = os.path.join(repertoire, f"{video_title}_extrait.mp4")
subprocess.run(["ffmpeg", "-y", "-ss", str(debut), "-to", str(fin), "-i", video_path, "-c", "copy", extrait_video_path], check=True)
ressources['video_extrait'] = extrait_video_path
# Extraction audio extrait
extrait_mp3_path = os.path.join(repertoire, f"{video_title}_extrait.mp3")
extrait_wav_path = os.path.join(repertoire, f"{video_title}_extrait.wav")
subprocess.run(["ffmpeg", "-y", "-ss", str(debut), "-to", str(fin), "-i", video_path, "-vn", "-acodec", "libmp3lame", "-q:a", "2", extrait_mp3_path], check=True)
subprocess.run(["ffmpeg", "-y", "-ss", str(debut), "-to", str(fin), "-i", video_path, "-vn", "-acodec", "pcm_s16le", extrait_wav_path], check=True)
ressources['audio_mp3_extrait'] = extrait_mp3_path
ressources['audio_wav_extrait'] = extrait_wav_path
# Extraction images
images_repertoire = os.path.join(repertoire, f"images_{fps_choice}fps_{video_title}")
os.makedirs(images_repertoire, exist_ok=True)
output_pattern = os.path.join(images_repertoire, "image_%04d.jpg")
cmd = [
"ffmpeg", "-y",
"-i", video_path,
"-vf", f"fps={fps_choice},scale=1920:1080",
"-q:v", "1",
output_pattern
]
if not extraire_toute_video:
cmd = [
"ffmpeg", "-y",
"-ss", str(debut),
"-to", str(fin),
"-i", video_path,
"-vf", f"fps={fps_choice},scale=1920:1080",
"-q:v", "1",
output_pattern
]
subprocess.run(cmd, check=True)
# Zipper les images
zip_images_path = images_repertoire + ".zip"
with zipfile.ZipFile(zip_images_path, 'w') as zipf:
for root, dirs, files in os.walk(images_repertoire):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, images_repertoire)
zipf.write(file_path, arcname)
ressources['images_zip'] = zip_images_path
return ressources, None
except Exception as e:
return None, str(e)
# Fonction pour créer un zip général de toutes les ressources
def creer_zip_global(ressources, repertoire):
zip_path = os.path.join(repertoire, "ressources_completes.zip")
with zipfile.ZipFile(zip_path, 'w') as zipf:
for nom, chemin in ressources.items():
if os.path.exists(chemin):
zipf.write(chemin, os.path.basename(chemin))
return zip_path
# ---------------- Interface utilisateur ----------------
st.title("Extraction multimédia (mp4 - mp3 - wav - images) depuis YouTube")
st.markdown("**[www.codeandcortex.fr](https://www.codeandcortex.fr)**")
st.markdown("""
➡ Entrez une URL YouTube.
➡ **Renseignez votre fichier cookies.txt** (optionnel) : fonctionne sans... tant que YouTube ne le demande pas.
➡ Le script téléchargera la **vidéo complète** au format .mp4
➡ Ensuite, il extraira automatiquement :
- L'audio complet (.mp3 et .wav)
- Un extrait vidéo (.mp4 selon l'intervalle défini)
- Un extrait audio (.mp3 et .wav)
- Des images extraites (1 ou 25 fps, toute la vidéo ou intervalle)
Enfin, vous pourrez télécharger toutes les ressources dans un seul fichier ZIP.
""")
# Nettoyage du cache au démarrage
vider_cache()
# Initialiser la session Streamlit
if 'video_path' not in st.session_state:
st.session_state['video_path'] = None
if 'video_title' not in st.session_state:
st.session_state['video_title'] = None
if 'repertoire_travail' not in st.session_state:
st.session_state['repertoire_travail'] = None
# Entrée URL
url = st.text_input("Entrez l'URL de la vidéo YouTube :")
cookies_file = st.file_uploader("Uploader votre fichier cookies.txt (optionnel)", type=["txt"])
# Téléchargement vidéo
if st.button("Télécharger la vidéo"):
if url:
st.session_state['repertoire_travail'] = definir_repertoire_travail_temporaire()
cookies_path = None
if cookies_file:
cookies_temp_path = os.path.join(st.session_state['repertoire_travail'], "cookies.txt")
with open(cookies_temp_path, "wb") as f:
f.write(cookies_file.read())
cookies_path = cookies_temp_path
video_path, video_title, erreur = telecharger_video(url, st.session_state['repertoire_travail'], cookies_path=cookies_path)
if erreur:
st.error(f"Erreur lors du téléchargement : {erreur}")
else:
st.success(f"Téléchargement réussi : {video_title}")
st.session_state['video_path'] = video_path
st.session_state['video_title'] = video_title
else:
st.error("Veuillez entrer une URL valide.")
# Extraction des ressources
if st.session_state['video_path']:
st.markdown("---")
st.subheader("Lecture de la vidéo téléchargée")
st.video(st.session_state['video_path'])
st.markdown("---")
st.subheader("Paramètres d'extraction")
col1, col2 = st.columns(2)
debut = col1.number_input("Début de l'intervalle (en secondes)", min_value=0, value=0)
fin = col2.number_input("Fin de l'intervalle (en secondes)", min_value=1, value=10)
fps_choice = st.selectbox("Fréquence d'images pour l'extraction :", options=[1, 25])
extraire_toute_video = st.checkbox("Extraire toutes les images de toute la vidéo", value=False)
if st.button("Extraire toutes les ressources"):
ressources, erreur = extraire_ressources(
st.session_state['video_path'],
st.session_state['repertoire_travail'],
debut,
fin,
st.session_state['video_title'],
fps_choice,
extraire_toute_video
)
if erreur:
st.error(f"Erreur lors de l'extraction : {erreur}")
else:
zip_global_path = creer_zip_global(ressources, st.session_state['repertoire_travail'])
st.success("Toutes les ressources ont été extraites avec succès !")
with open(zip_global_path, "rb") as f:
st.download_button(
label="Télécharger toutes les ressources (ZIP)",
data=f,
file_name="ressources_completes.zip",
mime="application/zip"
)