
Les nuages de mots dominent aujourd’hui les représentations textuelles : chacun y va de son petit nuage…
Pourtant, cette visualisation est réductrice – vous le savez sans doute déjà.
Certes, c’est un outil simple et immédiatement lisible. On pourrait croire qu’il permet d’identifier d’un coup d’œil les « thèmes principaux » d’un corpus…
Mais, dans le cadre d’une étude, le nuage de mots n’a qu’une valeur strictement quantitative.
Il met en évidence la fréquence d’une occurrence, sans pour autant démontrer quoi que ce soit.
Un mot peut être polysémique, c’est-à-dire porter plusieurs sens selon le contexte.
Par exemple, le mot “avocat“ peut désigner un fruit ou bien une profession.
Dans un nuage de mots, le contexte d’évocation n’est pas accessible. Il est donc impossible de trancher précisément sur le sens attribué à un terme polysémique.
L’analyse en fréquence des termes permet donc uniquement de mesurer combien de fois un mot apparaît dans un corpus, mais elle ne renseigne pas sur le sens ou l’usage précis de ce mot.
1. Text mining
Puisqu’il est question de fréquence, voici deux outils permettant de retracer l’évolution d’un terme dans des publications (presse…). Il faut toutefois rappeler que, même si cette approche en fréquence est utile pour certains objectifs de recherche, elle ne permet pas de déterminer la connotation précise d’un mot.
Par exemple, il reste difficile de savoir si le terme “surtourisme“ est employé de manière positive ou négative dans son contexte d’évocation.
Deux outils peuvent être mobilisés dans une primo démarche de text mining :
-
Gallicagram / Gallicapresse (CNRS – France, le serveur est parfois instable…) :
https://shiny.ens-paris-saclay.fr/app/gallicagram - Google Ngram Viewer :
https://books.google.com/ngrams/graph?content=surtourisme&year_start=2010&year_end=2022&corpus=fr&smoothing=0&case_insensitive=false
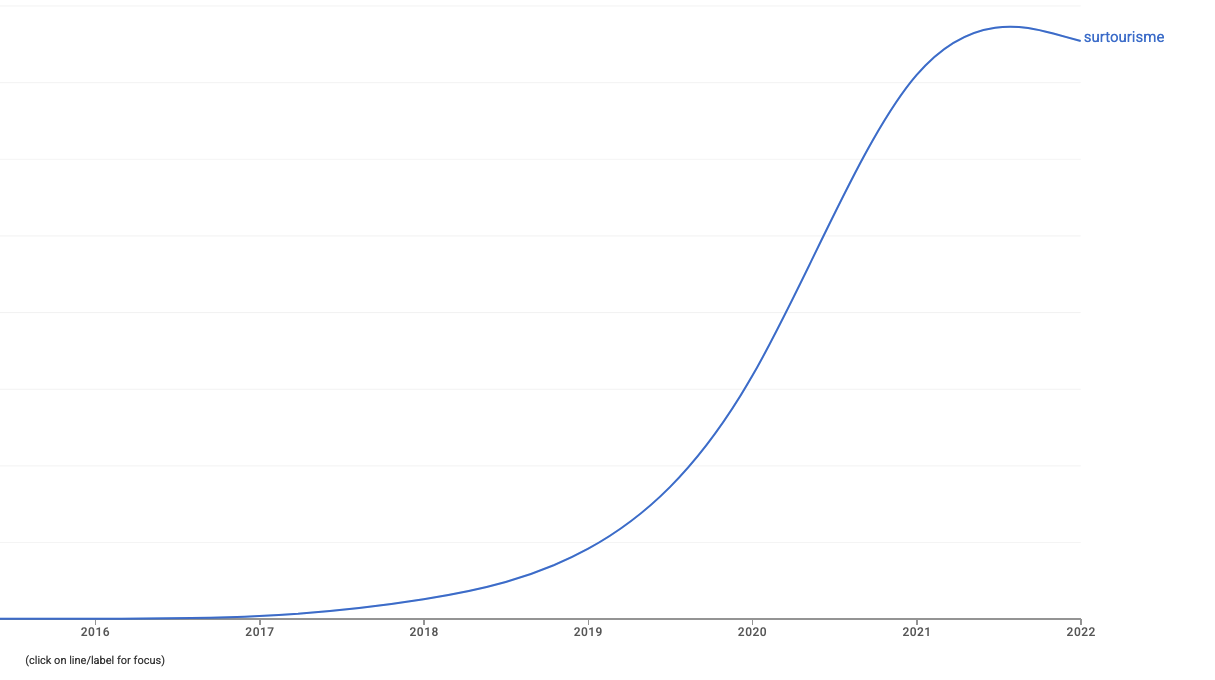
On observe une forte augmentation de la fréquence du mot “surtourisme” dans la littérature à partir de 2015.
2. Fréquence des mots bruts
Prenons un texte tel quel, sans aucun nettoyage, et comptons la fréquence de chaque mot.
Que voit-on ?
- Les mots-outils comme « le », « la », « les », « de », « et » dominent immédiatement le haut du classement.
- Sans normalisation, les termes identiques écrits en majuscule ou en minuscule sont considérés comme des mots différents.
La distribution brute des fréquences ne reflète donc pas véritablement le contenu du texte. Elle nous dit surtout comment la langue française est construite : beaucoup d’articles, de prépositions et de conjonctions.

La matrice : “frequence-rang” des mots du corpus est sans équivoque.
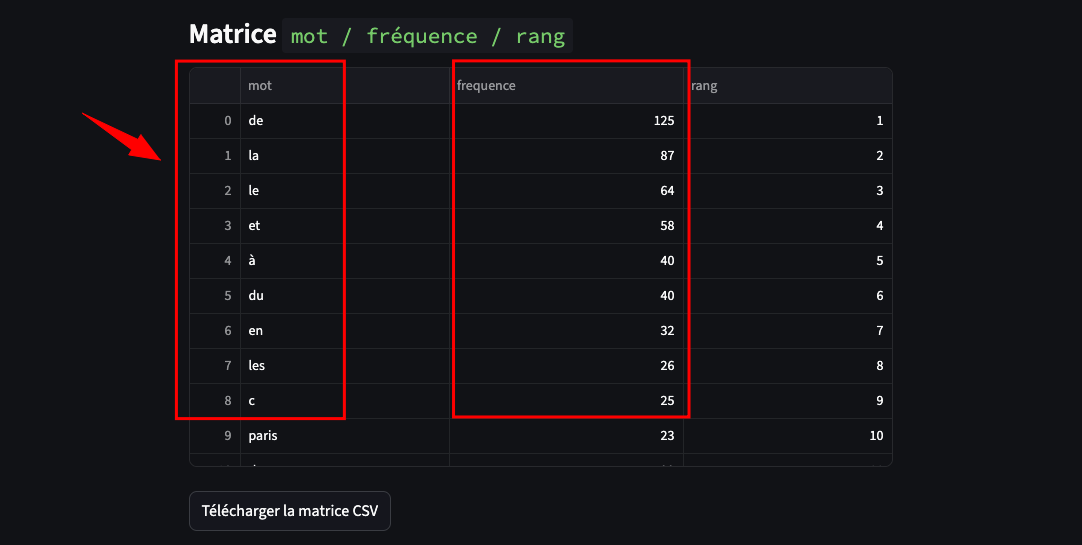
On ne distingue pas les notions centrales, mais seulement les contraintes grammaticales de la langue.
3. Vers une solution : le prétraitement en NLP
Les étapes essentielles du prétraitement (normalisation/preprocessing) consistent à normaliser le texte en plusieurs étapes.
Ces étapes ne sont pas systématiques, elles doivent être mobilisées en fonction des objectifs de l’analyse textuelle.
- Mettre tout le texte en minuscule,
- Éliminer les mots-outils (stopwords),
- Ne pas prendre en compte la ponctuation du texte (tout en conservant certaines balises pour “découper le texte” en segments).
- Réduire les mots à leur racine ou à leur lemme (lemmatisation ou stemming).
Les formes les plus fréquentes que l’on retrouve dans les rangs les plus élevés d’un corpus sont généralement des :
- Déterminants : le, la, les, un, une, des, du, de la, cet, cette, ces, mon, ton, son…
- Pronoms personnels : je, tu, il, elle, on, nous, vous, ils, elles, me, te, se, lui, leur…
- Prépositions : à, de, dans, sur, par, pour, avec, sans, sous, en…
- Conjonctions : et, mais, ou, donc, or, ni, car, que, parce que, lorsque, si…
- Adverbes très généraux : très, bien, déjà, aussi, encore, plus, moins, toujours, jamais…
- Auxiliaires et verbes faibles : être, avoir, faire, aller (surtout à l’infinitif ou au présent)
- Autres mots grammaticaux fréquents : ne, pas, ce, cela, il, y, en, au, aux…
Le choix de supprimer ou non ces formes dans un corpus est arbitraire, et devra être guidé par les objectifs de l’analyse.