L’enjeu ici est de développer, sur un serveur distant, un script permettant de réaliser une CHD, une AFC et d’autres tests, tels que l’analyse des entités nommées (NER) et l’analyse de cooccurrences. J’avais déjà développé, dans un article précédent, la mise en œuvre du package rainette développé par Julien Barnier. C’est à partir de cette base que j’ai transposé le script en application sur le serveur Hugging Face. : https://huggingface.co/spaces/stephane09/chd-rainette-0.3beta
1. Pourquoi choisir HuggingFace “Spaces” ?
Avec le développement de l’IA, HuggingFace (présentation de l’entreprise à ajouter) permet de développer et d’héberger des applications, notamment en mobilisant des modèles de langage mis à disposition sur la plateforme. Hugging Face est une plateforme qui permet de partager et utiliser des ressources d’IA (modèles, jeux de données, code source).
Son “Hub” centralise ces ressources un peu comme un GitHub dédié au machine learning. Hugging Face “Spaces” est la brique qui permet d’héberger des applications (Gradio, Streamlit, shiny (R)…) directement en ligne.
Par ailleurs, la plupart des scripts présentés sur ce blog sont essentiellement écrits en Python et hébergés sur Streamlit Cloud, qui ne gère pas le langage R. L’utilisation du package R de Julien Barnier, “rainette”, nécessite donc un environnement où l’on peut faire cohabiter R et Python.

Sur la version “cpu-basic” (free), l’application se met automatiquement en veille après 48 heures d’inactivité.
2. L’application
Bon, je n’ai pas trouvé de nom spécifique pour cette application à ce jour… L’important, c’est ce qu’elle réalise.
Tout d’abord, pour des questions d’interopérabilité entre logiciels, votre fichier texte (.txt) devra être encodé au format IRaMuTeQ, notamment avec une première ligne faisant figurer les variables étoilées.
 L’application utilise l’interface graphique Shiny (R). Le problème, c’est que la fonction
L’application utilise l’interface graphique Shiny (R). Le problème, c’est que la fonction rainette_explor affiche la CHD de rainette dans l’interface Shiny, notamment lorsqu’on travaille dans un environnement comme RStudio. Le développement se retrouve alors confronté à l’ouverture de deux boîtes de dialogue dans Shiny, ce qui est impossible, puisque l’application utilise déjà Shiny comme interface utilisateur. Bref, je me comprends : l’affichage des résultats n’a pas été simple, et l’enregistrement des résultats non plus.
En revanche, l’un des atouts du script est, en plus d’être une interface en ligne ne nécessitant aucune installation en local, de proposer un nombre important de paramètres en amont de la classification.
2.1 Méthode Reinert – CHD
La méthode de Reinert est une approche statistique d’analyse lexicale conçue pour dégager des “mondes lexicaux” dans un corpus. L’idée est de repérer des ensembles de segments de texte qui partagent des vocabulaires proches. Il procède par divisions successives : on prend l’ensemble des segments, puis on le coupe en deux groupes maximisant leur différenciation lexicale.
Ensuite, chaque groupe peut être à nouveau subdivisé, et ainsi de suite, jusqu’à obtenir un nombre de classes jugé pertinent.
2.2 Choix de la langue du dictionnaire spaCy
Vous avez le choix entre le français, l’anglais, l’espagnol… On pourrait en ajouter, car ces dictionnaires sont ceux fournis par la librairie NLP spaCy. Ici, nous utilisons (pour le moment) le modèle “medium” (md).
Il existe quatre tailles de modèles : “sm”, “md”, “lg” et “trf” (basé sur la technologie “transformer”). Le script détecte la cohérence entre le choix du dictionnaire et votre corpus importé, sur la base des stopwords.
2.3 Nettoyage – Lancement des tests
L’application segmente, construit une DTM (Document Termes Matrice – aussi appelé “DFM”), lance la CHD avec rainette, calcule les statistiques, génère un HTML surligné (concordancier), puis produit la CHD, AFC, NER (Entités Nommées, ex: Paris => LOC), nuages de mots et réseaux de cooccurrences.
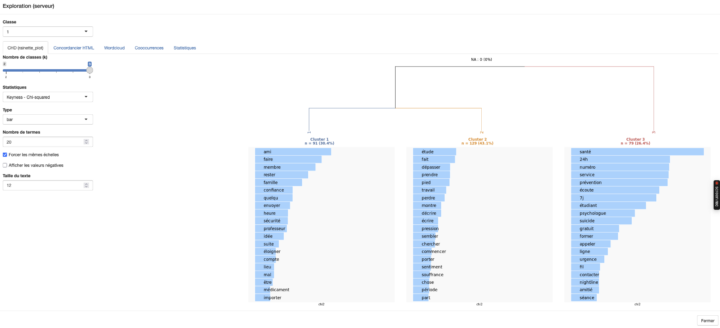
L’onglet d’exploration (Explore_rainette) permet de visualiser la CHD. Ici, on utilise les variables mises à disposition par le package rainette pour le calcul de la CHD.
 Le découpage des classes est réalisé par l’algorithme de rainette, qui permet d’ajuster et d’optimiser ce découpage. Je précise que j’ai utilisé le corpus employé par Julien Barnier lors de la présentation de rainette sur la chaîne Tuto Math SHS (manifeste.txt).
Le découpage des classes est réalisé par l’algorithme de rainette, qui permet d’ajuster et d’optimiser ce découpage. Je précise que j’ai utilisé le corpus employé par Julien Barnier lors de la présentation de rainette sur la chaîne Tuto Math SHS (manifeste.txt).
J’ai également comparé le fonctionnement de rainette avec IRaMuTeQ sur l’un de mes corpus (“Comment l’IA répond à la crise suicidaire ?”).
Deux conclusions s’imposent. D’une part, l’activation des options de nettoyage joue un rôle très important dans les résultats (j’oserais dire autant que le réglage des variables de paramétrage de la CHD, ci-dessous).
 D’autre part, je me suis très vite écarté du paramétrage utilisé à des fins de démonstration par Julien Barnier. Notamment, je propose d’utiliser les “dictionnaires NLP” de la librairie spaCy pour filtrer les stopwords et les catégories morphosyntaxiques.
D’autre part, je me suis très vite écarté du paramétrage utilisé à des fins de démonstration par Julien Barnier. Notamment, je propose d’utiliser les “dictionnaires NLP” de la librairie spaCy pour filtrer les stopwords et les catégories morphosyntaxiques.
Julien Barnier fait la démonstration avec quanteda (package R), tandis qu’IRaMuTeQ utilise son propre dictionnaire, basé sur OpenLexicon (sauf erreur de ma part), que l’on peut modifier.
2.4 Paramètres de la CHD
On ne retrouve pas de “bon” paramétrage, il faut un peut “tattonner” pour un obtenir un résultat qui à du sens.
segment_size : taille des segments lors du découpage du corpus. Vous retrouvez ce paramètre dans IRaMuTeQ.
k (nombre de classes) : nombre de classes demandé pour la CHD.
Nombre minimal de termes par segment (min_segment_size) : Avec min_segment_size = 10, les segments comportant moins de 10 formes sont regroupés avec le segment suivant ou précédent du même document jusqu’à atteindre la taille minimale souhaitée.
Effectif minimal pour scinder une classe (min_split_members). Nombre minimal de documents pour qu’une classe soit scindée en deux. Je reste assez sceptique sur l’impact réel de ce paramètre (peut-être parce que je ne l’ai pas encore parfaitement compris), mais quoi qu’il en soit, vous pouvez obtenir un résultat avec une CHD ne contenant que 3 ou 4 segments de texte.
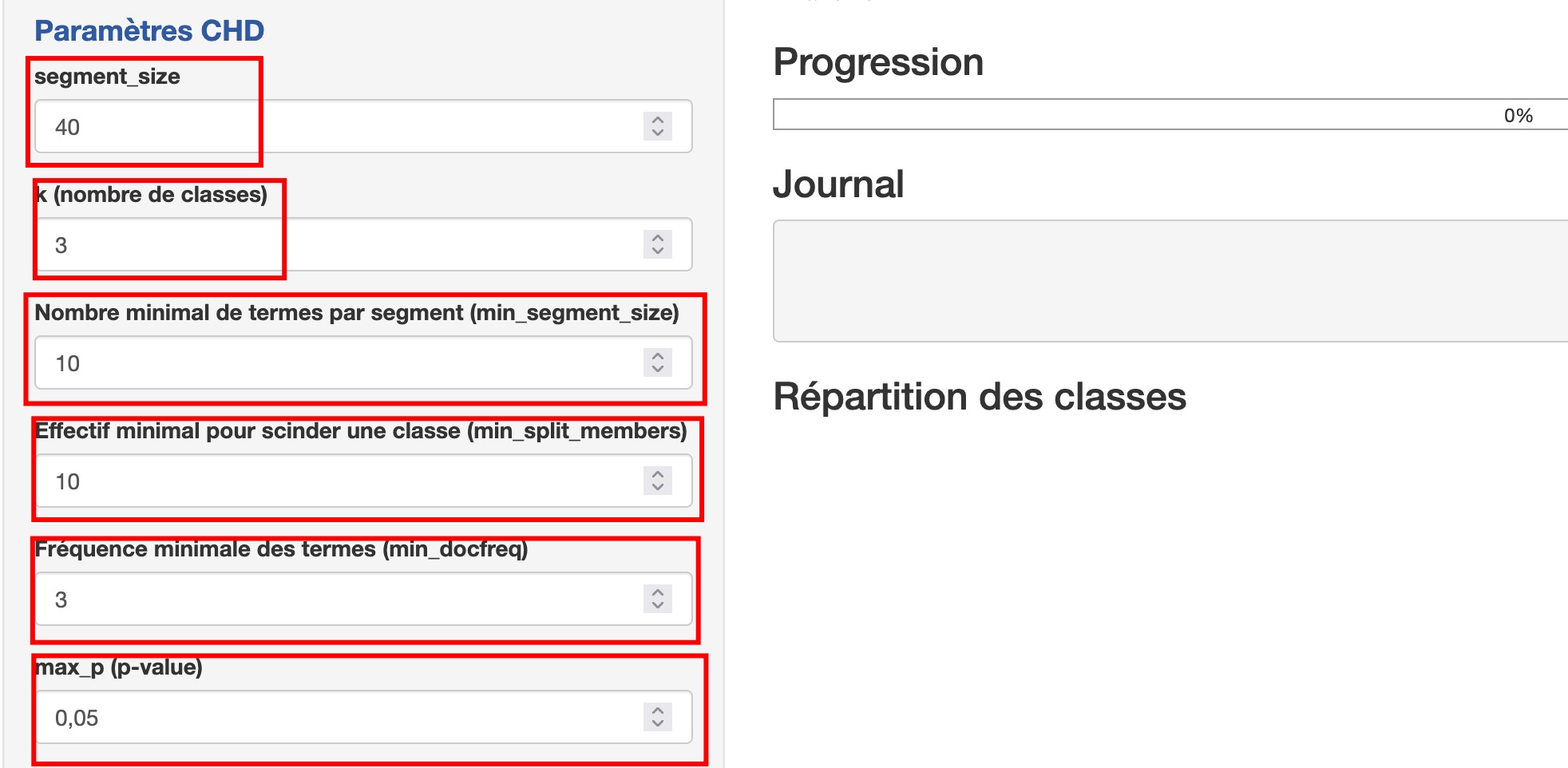
Fréquence minimale des termes : dfm_trim min_docfreq : fréquence minimale en nombre de segments pour conserver un terme dans le DFM. Plus “haut” enlève les termes rares.
Par exemple si vous dfm_trim = 3 cela supprime de la matrice les termes apparaissant dans moins de 3 segments
max_p (p-value) : seuil de p-value pour filtrer les termes mis en avant dans les statistiques.
2.5 Classification double (rainette2)
On réalise deux classifications distinctes en faisant varier la taille minimale des segments (min_segment_size), puis on met en correspondance ces deux partitions afin de reconstruire de nouvelles classes rainette.
2.6 Lemmatisation
Si activée, le texte est lemmatisé avec spaCy… Cela fonctionne bien avec les “VERBES”, mais la lemmatisation est plus efficace avec IRaMuTeQ.
2.7 Filtrage morphosyntaxique
L’activation de cette option (utilisant spaCy) filtre les tokens conservés selon leur catégorie grammaticale (ex : NOUN, ADJ, VERB, PROPN, ADV…). En nous appuyant sur la librairie spaCy, c’est binaire… : soit les catégories morphosyntaxique figurent dans l’analyse, soit elles en sont exclues, un peu à l’image des stopwords.
De plus, je rappelle que nous utilisons ici la version medium du modèle spaCy. La version “trf” est bien plus puissante pour l’attribution des POS tags aux tokens : par exemple, “ou”, selon sa position dans la phrase, peut renvoyer à une alternative/condition ou à un lieu…
3. Exploration
Il faut cliquer (pour des raisons d’affichage et de développement) sur l’onglet “Explore rainette“.
- Classe : sélection de la classe pour afficher les images et la table de statistiques associées.
- CHD : affichage graphique de la CHD dans l’application.
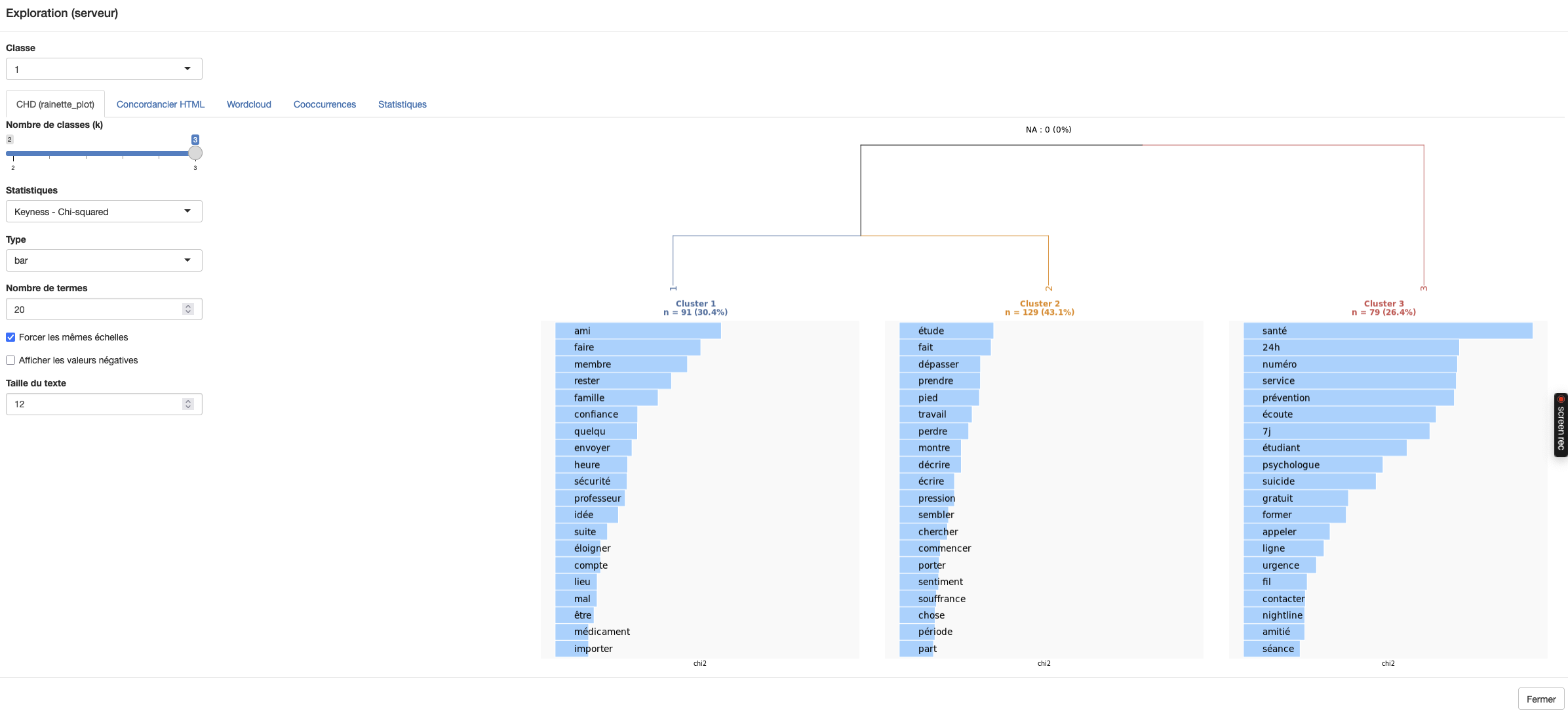
- Type : bar (barres) ou cloud (nuage) pour l’affichage des termes par classe.
- Statistiques : chi2, lr (log-likelihood), frequency.
- Dans les exports CSV de type chi2 (
measure = "chi2"), les colonnes suivantes sont importantes :n_target: nombre d’occurrences du terme dans le sous-corpus cible (la classe analysée).n_reference: nombre d’occurrences du même terme dans le corpus de référence (le reste des classes).chi2etp: test d’association entre cible et référence ; plus lechi2est élevé etppetite, plus le terme est spécifiquement lié.
- Nombre de termes : nombre de termes affichés par classe dans la visualisation.
- Afficher les valeurs négatives : Dans rainette, quand l’affichage propose des “chi2 négatifs”, il ne s’agit pas d’un chi-deux au sens strict, parce qu’un chi2 est toujours positif (il est basé sur un carré). Ici, on affiche un “chi2 signé”, indiquant le sens de l’association. Si le terme est surreprésenté dans la classe, la valeur est affichée positive. Si le terme est sous-représenté dans la classe, la valeur est affichée négative.
4. Aide AFC
top_termes est une limite d’affichage graphique des mots sur le plan AFC.Par défaut :
top_termes = 120Le rôle de top_termes est de limiter le nombre de labels affichés dans tracer_afc_classes_termes, sinon le plot devient illisible (chevauchements). Le code trie les termes par frequency qui détermine ensuite le top_termes.
La p-value réduit ici le “périmètre” des termes de l’AFC.
4.1 Le CSV contient-il seulement top_termes ?
Le CSV stats_termes.csv exporte le jeu complet de stats AFC disponible, sans appliquer la réduction top_termes.
4.2 Comment le résidu de Pearson est calculé ?
Le résidu de Pearson sert à lire, cellule par cellule, où se trouve l’écart entre ce que l’on observe dans les données textuelles et ce que l’on attendrait si les mots étaient distribués “au hasard” entre les classes, c’est-à-dire indépendamment de la classe.
Si le résidu est positif, le terme est surreprésenté dans cette classe : il apparaît plus souvent que prévu.
S’il est négatif, il est sous-représenté : le terme apparaît moins que prévu dans cette classe, ce qui peut aussi être informatif (par exemple un vocabulaire évité ou absent).
Le code extrait, pour chaque mot, la classe où la surreprésentation est la plus forte et sa valeur (resid_max).
Classe_max= C’est simplement la classe qui contient le plus d’occurrences observées de ce mot.resid_max= c’est la valeur la plus élevée du résidu pour un mot ; elle indique la classe où ce mot est le plus surreprésenté par rapport à ce qu’on attendrait.