Cet article, dense, se déploie en deux temps : d’abord une exploration théorique du signal audio, puis une réflexion sur une méthode pour analyser, restituer et rendre ces données intelligibles.
Il s’agit d’une approche multimodale, croisant audio et texte. Les données textuelles restent au cœur de l’analyse en SHS, mais elles peuvent aujourd’hui être parasitées par des contenus uniformisés générés par GPT, où la dimension critique du discours se perd.
Parallèlement, la montée en puissance des vidéos sur YouTube, TikTok… et autres réseaux montre que le son et l’image dominent désormais le débat médiatique.
Il devient donc indispensable, en SHS, de synchroniser et de confronter observations textuelles, données sonores et images pour enrichir la compréhension des discours. Cette étude, encore au stade expérimental, propose une méthode multimodale (approche (très) tendance dans domaine de l’intelligence artificielle) qui reste à perfectionner.
Pour la simplicité, le script vous demande d’importer un fichier .wav (issu ici de l’extraction préalable d’une vidéo YouTube), mais cette étape pourrait facilement être intégrée dans une version future, ouvrant la voie à une synchronisation image‑audio‑texte.
Vous pouvez testez l’appli via StreamlitCloud (no code ! mais lent) de plus cela vous évite d’installer les dépendances : https://analyse-audio.streamlit.app/
Le code source sur Github (à noter que devrez installer ffmpeg sur votre Mac/Pc ainsi que les dépendances : https://github.com/stephane1109/Analyse_audio/blob/main/main.py
Traditionnellement dans l’analyse textuelle, la segmentation repose sur des indicateurs tels que la ponctuation. Toutefois, l’intensité sonore, qui traduit l’insistance, les variations émotionnelles ou l’importance d’un passage dans le discours, pourrait constituer un indicateur supplémentaire permettant de repérer des segments de texte particulièrement saillants.
Dans cette approche expérimentale, nous nous concentrons sur l’analyse des variations de l’amplitude sonore (les pics d’intensité) afin de délimiter automatiquement des segments de texte autour de ces observations (points) atypiques.
Bien entendu, cette méthode doit être envisagée en prenant en compte de (très) nombreux biais inhérents aux conditions d’enregistrement : réglages/variations d’enregistrement, chevauchement des voix, environnement sonore,..
Il faut donc faire preuve de prudence dans l’interprétation de ces données.
Dire que ces éléments saillants “expriment la pensée du sujet” peut être “risqué” si l’on se base uniquement sur ces mesures acoustiques, car ces indicateurs restent des indices qui nécessitent une interprétation contextualisée.
C’est pour cela que le script propose de contextualisé à t-1 seconde et t+1 seconde en retrouvant le segment de texte.
Ainsi, ces observations “atypiques” de la courbe sonore peuvent suggérer des moments d’intensité, des hésitations ou d’autres signaux émotionnels, mais à eux seuls ils ne racontent pas l’intégralité du processus cognitif de la personne.
1. Le signal sonore
Le signal sonore extrait est une représentation numérique de l’onde acoustique capturée lors de l’enregistrement, constitué d’observation numérique (points) qui mesurent l’amplitude du son.
Le taux d’échantillonnage (sampling rate), exprimé en hertz (Hz), indique le nombre d’observations/valeurs (points sur la courbe) prélevés par seconde.
Plus le taux d’échantillonnage est élevé, plus le signal est détaillé, mais cela génère également une grande quantité de données…
1.1 Zoom sur l’amplitude du signal (waveform)
Dans un signal audio (waveform), on représente la pression acoustique autour d’un point d’équilibre (le zéro) ; les valeurs positives correspondent à des compressions (hausse de pression), les valeurs négatives à des raréfactions (baisse de pression).
« Les valeurs négatives du signal – qui reflètent la phase de raréfaction de la pression acoustique – sont tout aussi significatives que les valeurs positives.
Pour détecter les observations atypiques, on ne regarde pas le signe (+ ou -) mais la distance à l’axe 0 (c’est‑à‑dire l’amplitude), qu’elle soit positive ou négative. »
Les valeurs négatives ne signifient pas « moins intense » ; elles indiquent seulement que la pression est passée en dessous de la ligne de base (0).
L’intensité sonore, elle, dépend de la distance à zéro (amplitude), que la valeur soit positive ou négative.
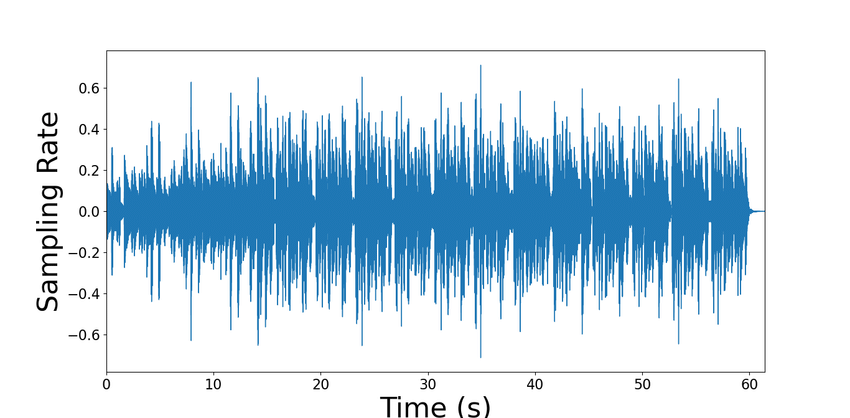
1.2 Analyse sur l’échantillon (toutes les observations)
La première approche a consisté à traiter la totalité des observations : pour 11 minutes d’enregistrement à 16 000 Hz, cela représente plus de 12 millions de valeurs…
Nombre total : 778,77 × 16 000 = 12 460 385 observations
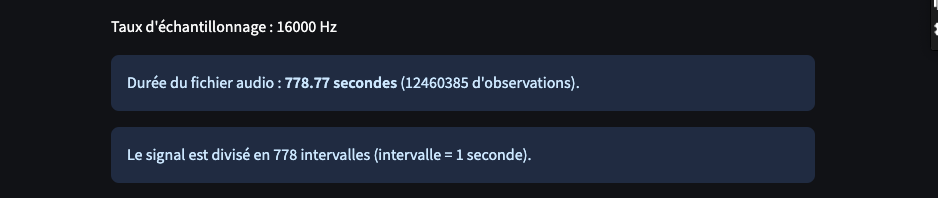
Vous l’aurez compris…, cette solution est “absurde” et pas adaptée aux ressources matérielles dont nous disposons.
1.3 Analyse par sous-échantillonnage
Pour afficher ce signal sans surcharger l’interface ni dépasser les contraintes mémoire, une autre méthode consiste à réduire le nombre total d’observations issues de la piste audio. La méthode la plus simple consiste à sous‑échantillonner le signal : par exemple, sur un enregistrement comportant plus de 12 millions d’observations, on peut n’en conserver qu’un nombre limité (1 000, 50 000 ou 100 000 observations) répartis de manière uniforme sur l’ensemble de la durée.
Cette simplification préserve approximativement la tendance globale du signal… mais, à mon sens, reste insatisfaisante.
2. Réduire la complexité humaine
Il est nécessaire de faire une précision sémantique :
En français, le terme “bin” peut se traduire par “intervalle” ou “catégorie”, et “binning” correspond à “regroupement en intervalles”. Cela désigne le processus consistant à diviser un grand ensemble de données en intervalles, puis à calculer des statistiques (comme la valeur minimale, maximale ou moyenne) pour chaque segment. J’ai choisi de garder le terme intervalle (plutôt que “binning”) même si cela peut porter à confusion avec le terme : “intervalle de confiance”.
-
L’intervalle de regroupement :
Ici, on divise le signal en segments d’une seconde. Chaque intervalle regroupe toutes les observations/valeurs enregistrés pendant une seconde. -
L’intervalle de confiance :
Pour chaque intervalle de regroupement on calcule des statistiques comme la valeur minimale, maximale et la valeur moyenne. Ainsi notre intervalle de confiance ou seuil de détection est défini par : [μ±k×σ].
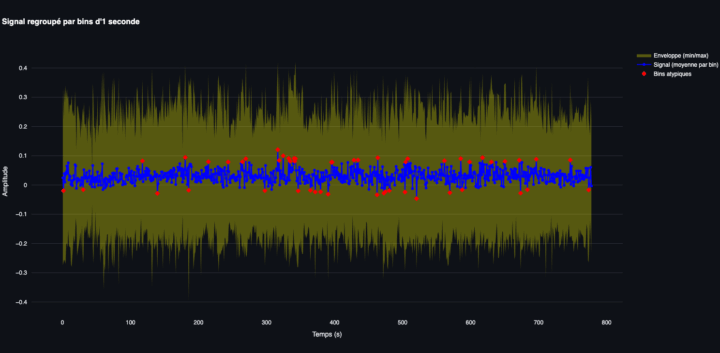
2.1 Regroupement par intervalle de 1 seconde
C’est la méthode que nous allons mettre en œuvre.
Supposons que notre fichier audio de 777 secondes soit composé de 12 460 320 observations : Un intervalle correspond alors approximativement à 12 460 320 ÷ 777 = 16 036 observations du signal.
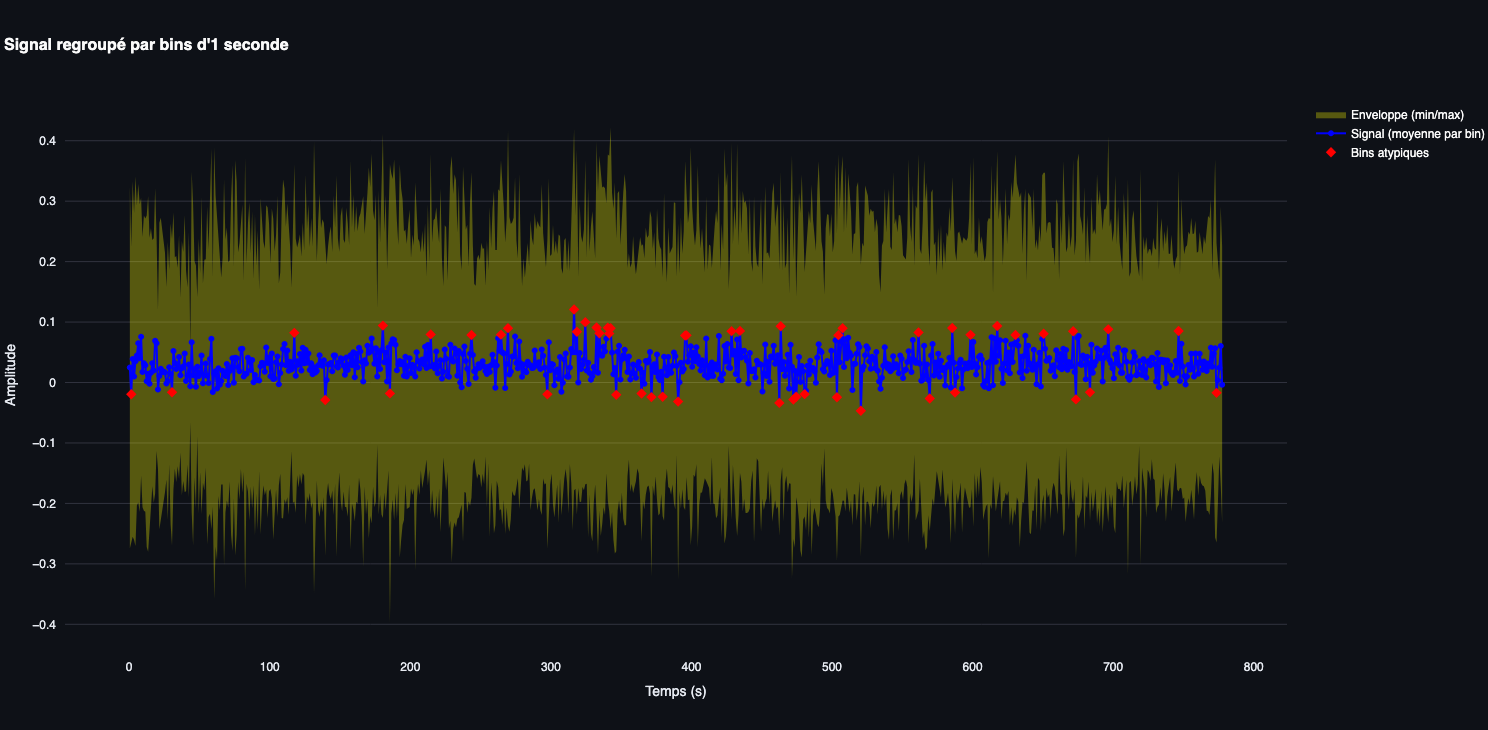
Pour chaque intervalle de 1 seconde, on utilise l’ensemble des observations qui se trouvent dans cet intervalle pour calculer des valeurs comme :
- La valeur minimale (le creux)
- La valeur maximale (le pic)
- La valeur moyenne du signal
-
Temps moyen (ou point médian) de l’intervalle : Pour représenter graphiquement l’intervalle dans le temps, on calcule la moyenne de tous les timestamps de cet intervalle. Comme l’intervalle est d’une seconde, cette moyenne (de 10 s à 11 s, le temps moyen est de 10,5 s). Ce temps moyen est simplement utilisé pour positionner l’intervalle sur le graphique.
3. Mesure de dispersion par l’Écart‑Type et le paramètre k
Pour filtrer et se focaliser sur les variations les plus fortes, le script calcule la moyenne (μ) du signal et son écart‑type (σ).
Un point atypique est détecté s’il se situe en dehors de l’intervalle de confiance défini par [μ – k×σ] et [μ + k×σ] — que ce soit pour une valeur négative ou positive.
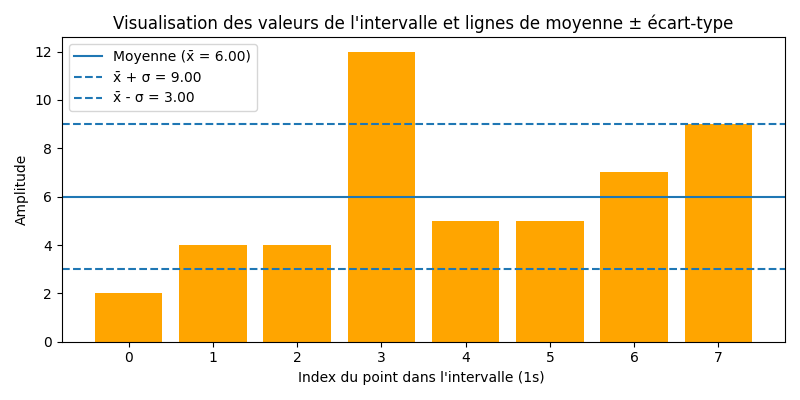
La moyenne globale (μ) et l’écart‑type (σ) sont calculés sur la série des valeurs moyennes de chaque intervalle. On définit ensuite un intervalle de confiance, [μ – k×σ] et [μ + k×σ], où le paramètre k (ajustable dans l’interface) permet de régler la sensibilité de la détection des variations.
La moyenne μ est le point central de la distribution des valeurs.
Pour définir une plage “normale” autour de μ, on veut couvrir à la fois les valeurs inférieures à μ et celles supérieures à μ.
Ainsi : μ−k×σ fixe le seuil inférieur et μ+k×σ fixe le seuil supérieur
L’écart‑type σ mesure la dispersion des observations/valeurs par rapport à la moyenne.
En le multipliant par k, on “ajuste” la largeur de l’intervalle autour de μ.
3.1 Zoom sur le paramètre k
Lorsqu’on fixe le seuil à 1 σ, on retient tous les points situés à plus d’1 σ de la moyenne. Or, pour une loi normale :
- Environ 68,27 % des valeurs se trouvent dans l’intervalle [μ – 1σ, μ + 1σ], soit 31,73 % en dehors.
- Environ 95,45 % des valeurs sont dans [μ – 2σ, μ + 2σ], soit 4,55 % en dehors.
- Environ 99,73 % des valeurs sont dans [μ – 3σ, μ + 3σ], soit 0,27 % en dehors.
Ainsi, avec k = 1, on “conserve” près de 31,7 % des observations comme atypiques, ce qui peut (sembler) trop élevé pour ne conserver que de véritables « pics ».
En passant à k = 2, on ne détecte plus qu’environ 4,5 % des points, et à k = 3 seulement 0,3 %, ne gardant alors que les écarts vraiment saillants par rapport à la moyenne.
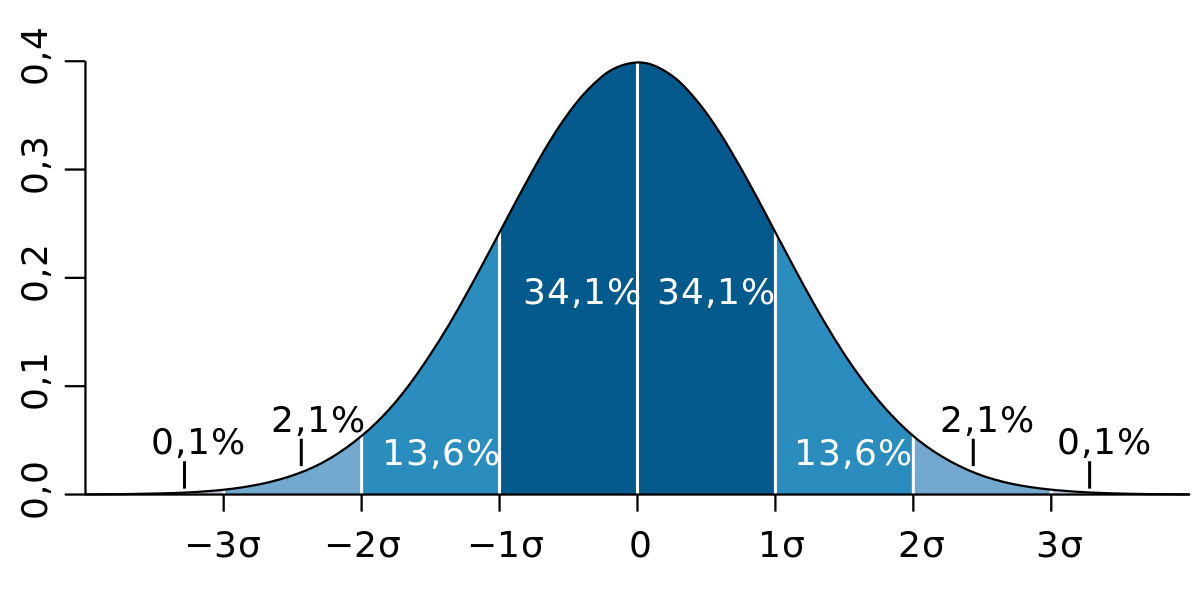
Si vous fixez votre seuil à σ (k = 1), vous allez donc conserver comme « atypiques » environ 32 % de vos observations.
En choisissant k plus grand (par exemple k = 2 ou 3), vous réduisez fortement la proportion de points atypiques détectés, et ne conservez que les écarts les plus marqués par rapport à la moyenne.

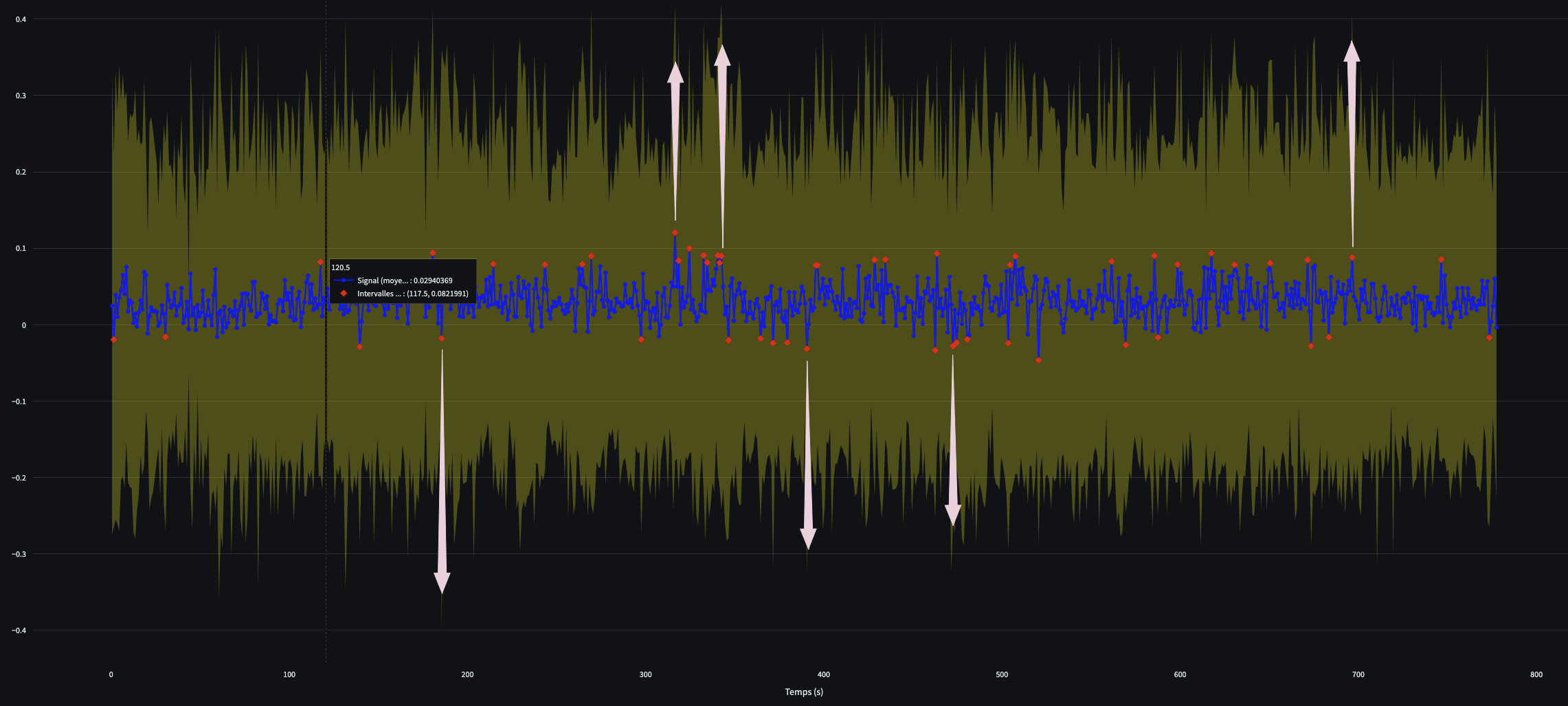
4. Concordancier et recontextualisation
Pour chaque observation atypique, une fenêtre temporelle de 1 seconde avant et 1 seconde après est utilisée pour extraire le texte correspondant à partir de la transcription (si activée).
Ainsi, pour chaque point atypique, le script recontextualise le moment en extrayant les segments de texte correspondants à une fenêtre temporelle allant d’une seconde avant à une seconde après le point atypique.
Cela se fait à l’aide de la transcription générée par Whisper.
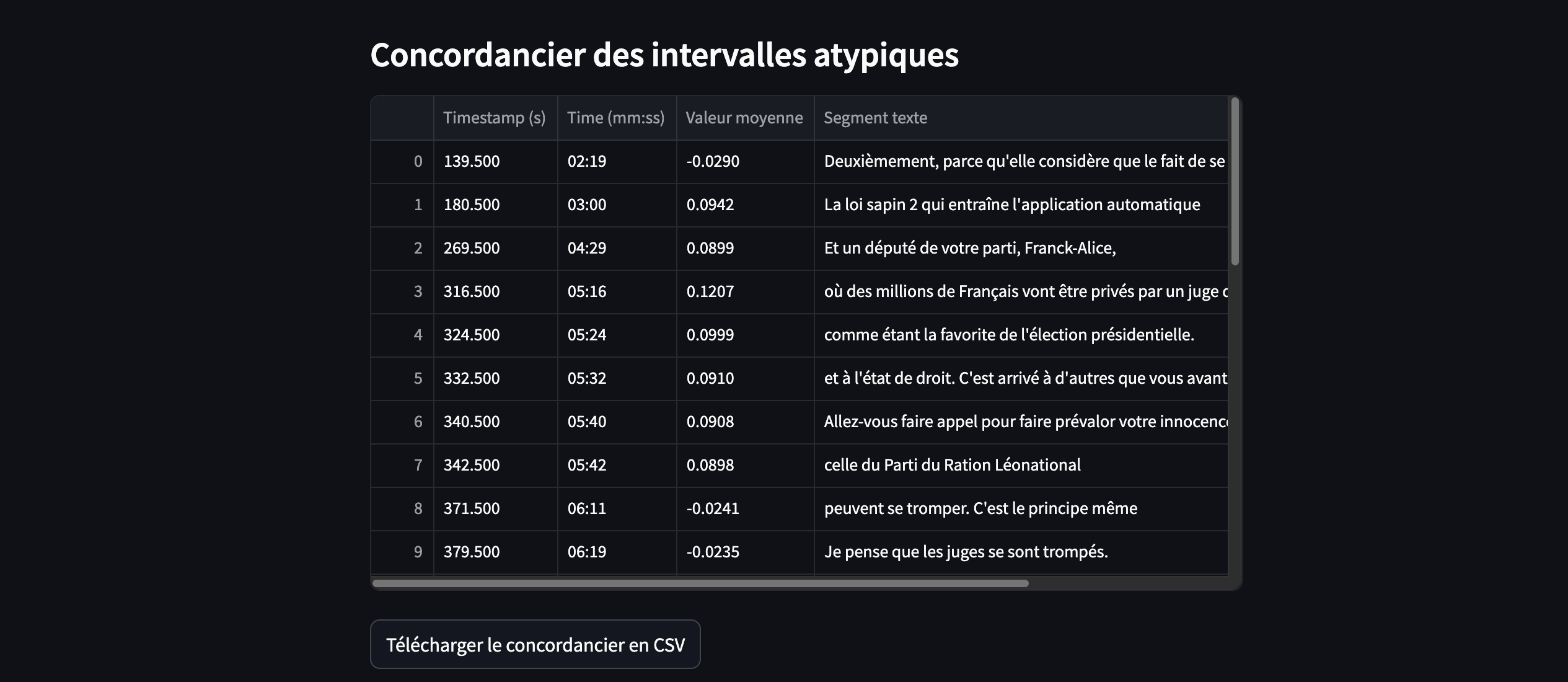
J’ai appliqué la méthode à l’interview de Marine Le Pen diffusée sur TF1 (YouTube – 31/03/2025), réalisée dans la foulée de sa condamnation pour inéligibilité.
L’intérêt réside dans la mise en regard des résultats de l’analyse audio et du fil réel de l’entretien, rendue possible par la précision des timsestamps.
Cette synchronisation (multimodale), permet de croiser amplitude, pauses, débit,…, avec la vidéo et la bande son.
5. Intérêt de la démarche
Cette méthode permettra (je l’espère!) d’identifier et de mettre en évidence des motifs récurrents (patterns) dans les discours politiques par exemple en repérant, via l’analyse statistique du signal audio, les instants où la voix marque une intensité inhabituelle.
En extrayant et en concaténant ces segments de texte associés à ces pics sonores, on reconstitue des passages clés du propos, offrant un aperçu plus ciblé des stratégies argumentatives employées.
Bien que cette analyse se concentre sur l’audio et le texte, l’approche utilisée ouvre naturellement la voie à une analyse multimodale plus large. En combinant simultanément le signal audio, le texte transcrit et les images extraites (par exemple, d’une vidéo), il devient possible de croiser les indices forts du discours avec les éléments visuels, offrant ainsi une compréhension plus riche et nuancée de la communication.
Enfin, l’une des perspectives de cet article sera de synchroniser l’image sur la base temporelle d’une seconde (et non à 25 fps), au même rythme donc que les intervalles sonores.